


Трансформатор ТМ расшифровка
Конечно, у нас собстевенное производство, поэтому мы можем производить не стандартные транс р с боковым подключением вводов и выводов высокого и низкого напряжения. Вправо и влево — вверх и вниз, типа НН и ВН и дополнительными опциями! Сборка любых технических параметров первичной и вторичной обмотки
Да, мы сотрудничаем с официальными дилерами, представительство в России, список таких заводов:
Казахстан — Кентауский трансформаторный завод
Белоруссия Минск — Минский электротехнический завод им Козлова
Украина Богдано Хмельницчкий (Запорожский) — Укрэлектроаппарат
Алтайский Барнаул — Барнаульский Алттранс
Тольяттинский
Самарский — Самара ЗАО Электрощит СЭЩ
Санкт Петербург СПБ Невский — Волхов Великий Новгород
Подольский — ЗАО Трансформер
Чеховский Электрощит
Георгиевский ОАО ГТЗ
Компания кубань электрощит
Марки трансформаторов с естественной масляной системой охлаждения обмоток серии ТМ ТМГ ТМЗ ТМФ ТМГФ. Виды баков гофро (гофрированный) и с радиаторами (радиаторный)
А так же доступны линейки сухих трансформаторов ТС ТСЗ ТСЛ ТСЛЗ
Виды баков гофро (гофрированный) и с радиаторами (радиаторный)
А так же доступны линейки сухих трансформаторов ТС ТСЗ ТСЛ ТСЛЗ
Производим повышающие и понажающие напряжение заземление тока, большие цеховые, производственные, промышленные и общепромышленные трансформаторы собственных нужд общего назначения внутренней встроенные в помещение ТП и наружной установки закрытого типа. Выбор наминалы мощности 25 40 63 100 160 250 400 630 1000 (1 мВа) 1250 (1 25 мВа) 1600 (1 6 мВа) 2500 4000 6300 кВа и напряжением 6 10 35 110 0.4 кВ кВт. Можем сделать испытание напряжением под заказ, например компоновка новые типовые проекты из аморфной стали или с глухозаземлённой нейтралью каскадные, разделительные, фланцевые с боковыми вводами выводами. Строительство соответствует нормам ПУЭ и ТУ сертификация систем охлаждения.
С необходимыми параметрами и тех характеристиками габаритами размерами весом высотой шириной и доп описание из образеца технического задания справочные данные документация условия работы.![]()
Поставляем в дачный посёлок коттеджные дачи коттеджи, садовые СНТ товарищества, сельские деревенские местности деревни
Отличия силовых трансформаторов ТМ, ТМГ, ТМГФ
Большинству специалистов известна разница между трансформаторами ТМ, ТМГ и ТМГФ. Однако, для тех, кто редко с этим сталкивается, небольшая справка будет полезна.
Все перечисленные трансформаторы относятся к типу «масляных». Их охлаждение осуществляется с помощью специального трансформаторного масла, залитого в радиаторы.
Прямое назначение силовых масляных трансформаторов — понижение напряжения в сети до рабочего значения (как правило, 0,4 кВ). Устанавливаются трансформаторы как внутри помещений трансформаторных подстанций, так и снаружи, так как довольно неприхотливы в отношении температуры окружающей среды.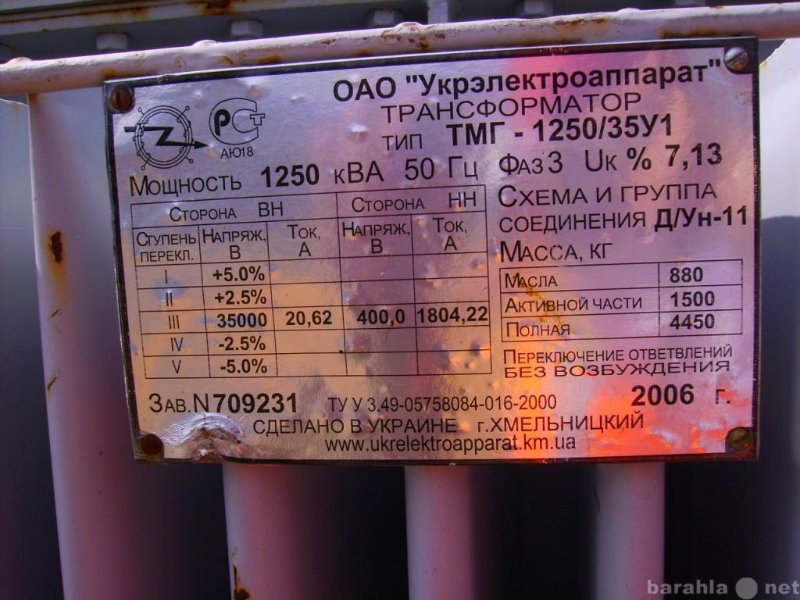 Силовые трансформаторы могут работать при температуре от -60 до +45 градусов. Защита обмоток масляной средой увеличивает срок эксплуатации до 25 лет, одновременно повышая надежность и нетребовательность к обслуживанию. Единственным недостатком силовых масляных трансформаторов считается потребность в химически пассивной и невзрывоопасной окружающей среде.
Силовые трансформаторы могут работать при температуре от -60 до +45 градусов. Защита обмоток масляной средой увеличивает срок эксплуатации до 25 лет, одновременно повышая надежность и нетребовательность к обслуживанию. Единственным недостатком силовых масляных трансформаторов считается потребность в химически пассивной и невзрывоопасной окружающей среде.
По конструктивному исполнению трехфазные силовые трансформаторы с масляным охлаждением делятся на следующие виды:
- трехфазные масляные (ТМ),
- трехфазные масляные в герметичной оболочке (ТМГ).
Трансформаторы ТМ
Исторически первыми появившимися силовыми масляными трансформаторами были трансформаторы марки ТМ. Эта аббревиатура собственно и означает «трансформатор масляный» (точнее трансформатор «трехфазный масляный»).
 Масло перед заливкой дегазируется, что позволяет увеличить электрическую прочность изоляции.
Масло перед заливкой дегазируется, что позволяет увеличить электрическую прочность изоляции.
Характерной чертой внешнего вида трансформаторов ТМ с полным заполнением маслом является расширительный бак.
Во время работы трансформатора масло нагревается, его объем увеличивается. Увеличение объема масла компенсируется расширителем, который имеет масляный затвор с воздухоосушителем для очистки и осушения воздуха. Объем расширительного бака составляет около 10% от объема масла.
Трансформаторы марки ТМ не являются герметичными. Со временем трансформаторное масло может впитывать влагу и воздух из окуружающей среды, теряя при этом свои свойства. По этой причине для трансформаторов ТМ предусматривается регулярная замена трансформаторного масла, что, учитывая его объем (до 300-400 литров), является непростой процедурой и может проводиться только специалистами. Кроме того, возникает проблема утилизации старого трансформаторного масла.
Указанных проблем лишены трансформаторы ТМГ с герметичным масляным баком, которые к настоящему времени практически полностью вытеснили трансформаторы ТМ до мощности 6,3 мВА.
Трансформаторы ТМГ
В отличии от предшествующей серии трансформаторов ТМ, масляные трансформаторы серии ТМГ изготавливаются в герметичном исполнении (их внутренний объем не имеет сообщения с окружающей средой).
Трансформаторы заполнены трансформаторным маслом. Расширитель или газовая «подушка», сообщающаяся с внешней средой, отсутствует, вследствии чего исключается увлажнение и окисление масла, а также шламообразование. Трансформаторное масло не меняет своих свойств в течение всего срока службы трансформаторов, поэтому проводить отбор пробы масла и его замену не требуется (Правила устройства электроустановок. 7-е Издание. Глава 1.8.16, п. 13).
Герметичные трансформаторы ТМГ, даже после продолжительного хранения, практически не требуют расходов на предпусковые работы и при правильной эксплуатации не нуждаются в профилактических ремонтах и ревизиях в течении всего срока эксплуатации.
Изменение давления внутри бака компенсируется благодаря небольшой воздушной «подушке», предусмотренной в верхней части бака масляного трансформатора ТМГ, а также благодаря конструкции радиаторов. Для исключения недопустимого превышения давления трансформатор ТМГ снабжен предохранительным клапаном, срабатывающим при избыточном давлении 75 кПа (0,75 кгс/см2).
Для исключения недопустимого превышения давления трансформатор ТМГ снабжен предохранительным клапаном, срабатывающим при избыточном давлении 75 кПа (0,75 кгс/см2).
Для локализации последствий аварий, связанных с повреждением трансформатора, баки трансформаторов серий ТМГ оснащаются предохранительными мембранными устройствами, предназначенными для аварийного сброса масла при резком увеличении избыточного давления. При нормальной эксплуатации данное устройство не требует дополнительного обслуживания в течение всего срока службы трансформатора ТМГ.
Трансформаторы ТМГФ
Трансформаторы ТМГФ (фланцевые) являются модификацией трансформаторов ТМГ для установки внутри производственных помещений.
Вводы высокого и низкого напряжений на трансформаторах серий ТМГФ смещены в торцам корпуса трансформатора и оснащены коробами, что обеспечивает возможность фланцевого сопряжения с соответствующими распределительными устройствами.
При установке внутри помещения шины высокого и низкого напряжения должны быть расположены таким образом, чтобы к ним не было доступа обслуживающего персонала.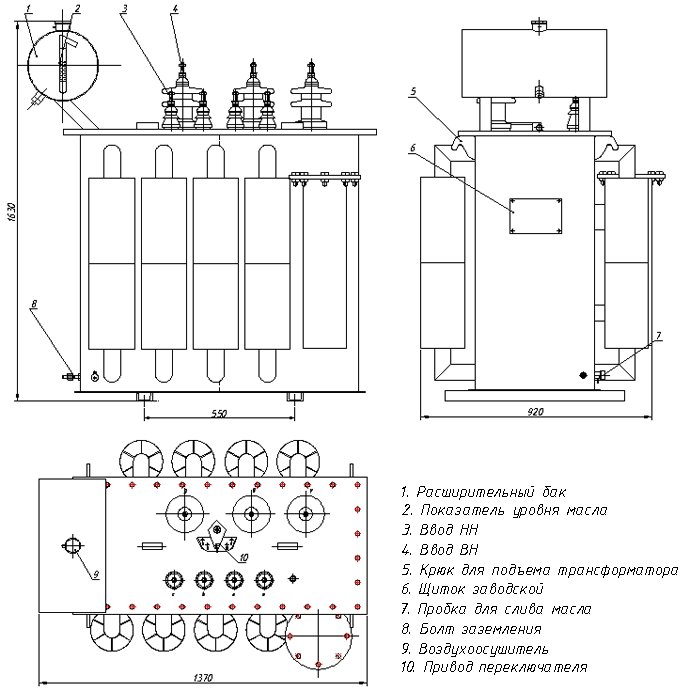 Для этого используют металлические короба, которые ограждают шины. Короба на трансформаторе крепятся к фланцам.
Для этого используют металлические короба, которые ограждают шины. Короба на трансформаторе крепятся к фланцам.
Установка трансформатора ТМГФ внутри помещения
расшифровка, технические характеристики и типы
Трансформаторы ТМН представляют собой трёхфазные электроустройства с возможностью регулировать напряжение под нагрузкой. Их можно устанавливать как внутри здания, так и снаружи. Оформить заказ на трансформатор ТМН лучше всего на специализированном сайте, где такая продукция представлена в широком ассортименте.
Принцип работы
Изделия оборудованы специальной системой, которые позволяют принудительно охлаждать компоненты оборудования. Установки ТМН можно применять для работы в энергосетях 35 кВ. Согласно конструкции воздушные массы и масло в ней циркулируют естественно. Использование такой установки избавляет от крупных потерь электроэнергии. Это способствует улучшению всех параметров энергетического потребления на линиях электропередач.![]() Такие изделия не нуждаются в том, чтобы их технически обслуживали и заменяли масло на протяжении всего периода использования.
Такие изделия не нуждаются в том, чтобы их технически обслуживали и заменяли масло на протяжении всего периода использования.
Конструкция
Любое устройство ТМН, которое представлено на сайте, обладает схожими конструктивными особенностями. Поставляемое оборудование состоит из:
- магнитопровод, выполненный из электротехнического стального материала;
- многослойных обмоток из сплавов алюминия и меди,
- непроницаемым баком, который наполнен маслом;
- клеммной коробкой;
- воздухоосушителем;
- расширителем, где указывается объём масла.
Также в состав таких устройств входят шины низкого и повышенного напряжения, катки, позволяющие перемещать устройство и другое техоборудование. Дополнительно устройство может комплектоваться мановакуумметрами, набором запчастей и нужных особых инструментов для подключения.
Технические характеристики
Характеристики трансформаторов разных видов позволяют подобрать оптимальное устройство для любых целей использования, в частности, чтобы снабжать энергией жилые либо промышленные объекты.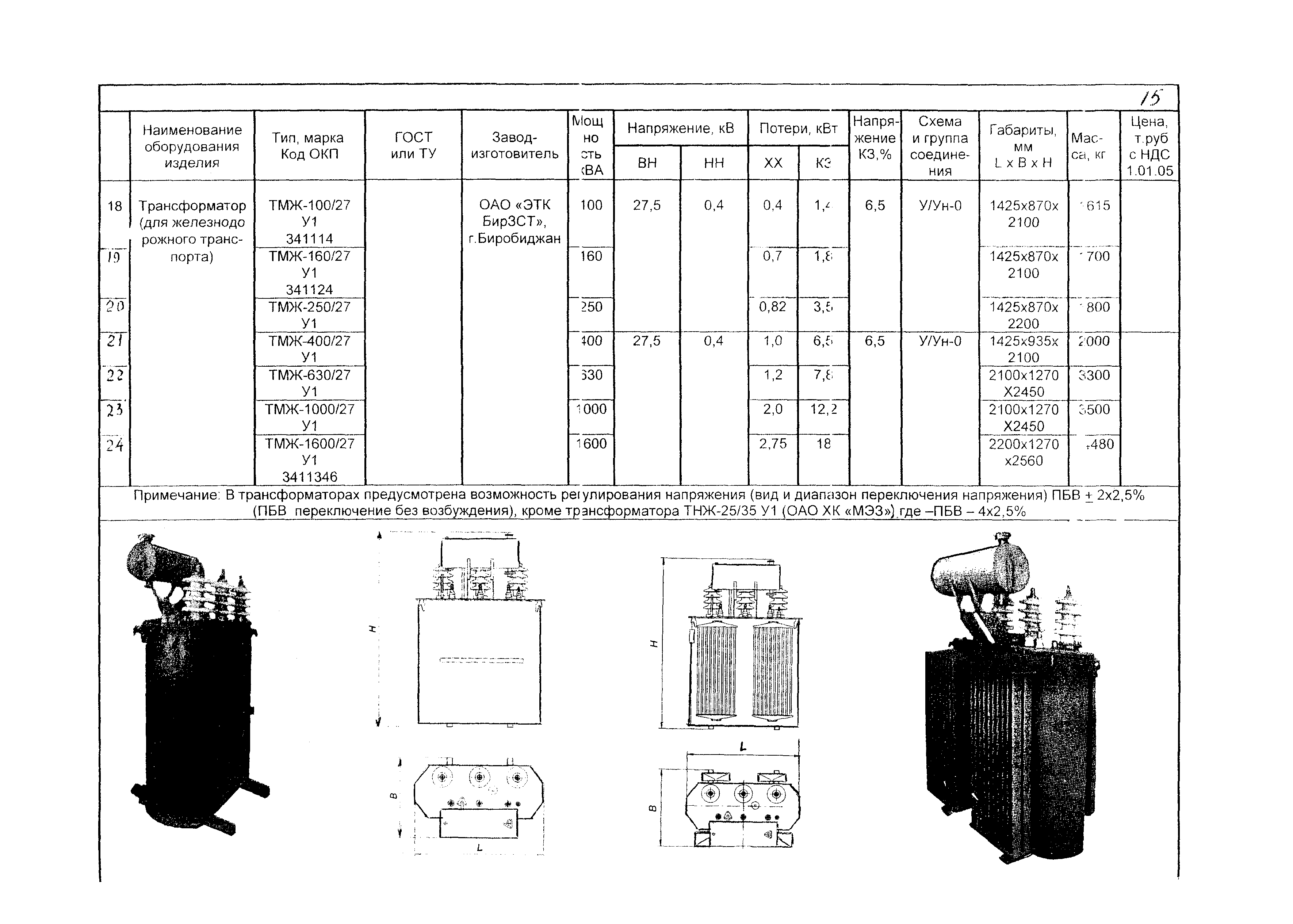
Технический паспорт трансформатора типа ТМН:Смотреть документ.
Классификация
Мощность устройств может быть от 1000 до 25000 кВА. Трансформаторы можно эксплуатировать в течение периода до тридцати лет. Их изготавливают в климатических исполнениях УХЛ1 либо У1 – оборудование способно осуществлять работу при температурном режиме до – 60 и – 40 °С соответственно.
Цена аппарата
Стоимость трансформаторного оборудования зависит от его размеров и мощности. Цена силовых трансформаторов отличается своей доступностью. На сайте представлены разнообразные модели:
- 1000 С РПН,
- 1600 С РПН,
- 25000 С РПН.
Узнать цену можно по запросу.
Маркировка
Аббревиатура ТМН соответствуют определённым показателям:
- Т – 3-фазная конструкция.
- М – присутствие системы охлаждения масла.
- Н – регулирование напряжения осуществляется под нагрузкой.

РПН трансформатора

Назначение и область применения
Применение трансформаторов ТМН достаточно обширно. Назначение таких устройств – организовать эффективную систему энергетического снабжения малых населённых пунктов, посёлков с дачами и коттеджами, месторождений газа и нефти. Силовые трансформаторы приобретают промышленные и аграрные предприятия, торгово-складские комплексы.
Требования при эксплуатации
Эксплуатировать оборудование следует в соответствии с инструкцией предприятия-изготовителя, а также установленным нормам техэксплуатации и нормам конструкции электрических установок.
Оборудование рассчитано на длительную эксплуатацию при увеличении напряжения, но не больше десяти процентов над номинальным напряжением конкретного ответвления обмотки ВН. Причём мощность не должна быть больше номинально заявленной.
Согласно правилам ГОСТ:
- Окружающая среда не должна быть опасной для взрывов, не должна содержать пыль, проводящую пыль.
- Вышина конструкции над уровнем моря не должна быть больше тысячи метров, а влажность воздуха не должна быть больше восьмидесяти процентов.
- Изделия, выполненные в традиционном исполнении, нельзя использовать в условиях химически агрессивных сред.
Как подключить
Поставка моделей трёхфазного электрооборудования может осуществлять собранном или частично разобранном виде. В наборе содержатся конкретные чертёжные проекты, показывающие как правильно собирать заводскую конструкцию. Процедуру монтажа выполняет компания, которая получила соответствующую гослицензию на подобную деятельность. Её сотрудники осматривают, настраивают и запускают установку ТМН согласно требованиям изготовителя.
При 3-фазных трансформаторных обмотках существует 3 способа подсоединения: «треугольник», «звезда» и «взаимно связанная звезда». Схема подключения определяется исходя от совмещения напряжений и мощности устройства. Монтаж трансформатора ТМН выполняется на заранее подготовленную фундаментную основу.
Трансформатор ТМ 25 6 0,4 масляный 75 190 руб.
Трансформатор ТМ 25 6 0,4 технические характеристки
СРОК СЛУЖБЫ 25 ЛЕТ
Для предотвращения возникновения избыточного давления при аварийных режимах в баке
трансформатора ТМ 25 устанавливается предохранительный клапан
Соответствуют ГОСТ Р 52719-2007
Длительный режим работы
Перед отгрузкой электротехническое оборудование проверяется, испытывается и полностью готово к эксплуатации
В комплекте поставляются:паспорт и протокол испытаний
| Номинальная мощность, кВА | 25 |
|---|---|
| Номинальное напряжение на стороне ВН, кВ | 6 |
| Номинальное напряжение на стороне НН, кВ | 0,4 |
| Схема соединения | У/Ун-0 (звезда-звезда), Д/Ун-11 (треугольник-звезда), У/Zн-11 (звезда-зигзаг) |
| Климатическое исполнение и категория размещения | У1, УХЛ1 |
| Допустимая температура эксплуатации | от -45 до +40 °С (У1), от -60 до +40 °С (УХЛ1) |
| Материал обмоток | Алюминий (алюминиевый), медь (медный) |
| Нормативные документы | ГОСТ 11677, ГОСТ 30830, ГОСТ Р 52719-2007, МЭК – 76 |
| Гарантия | 3 года |
Конструктивное исполнение ТМ
Вводы ВН и НН расположены на крышке.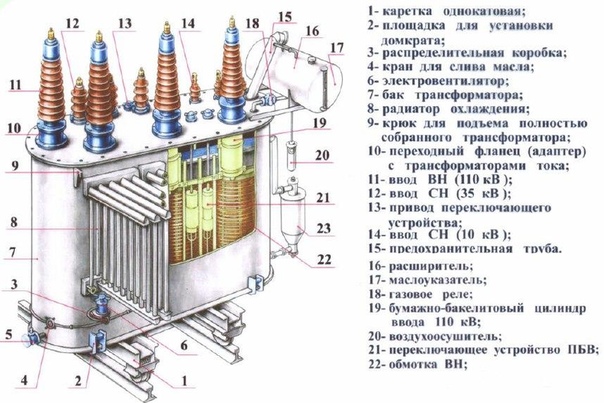 Баки трансформаторов ТМ прямоугольной формы. Для увеличения поверхности охлаждения применяются радиаторы.
Баки трансформаторов ТМ прямоугольной формы. Для увеличения поверхности охлаждения применяются радиаторы.
На крышке бака имеется кран (пробка) для залива масла, внизу бака имеются пробка для спуска масла, кран (пробка) для взятия пробы, болт заземления.
Намотка провода и изоляции катушек производится с одновременной укладкой на автоматизированном оборудовании. Вводы ВН и НН расположены на крышке. Для предотвращения возникновения избыточного давления при аварийных режимах в баке трансформатора серии ТМ устанавливается предохранительный клапан.
По желанию заказчика возможна:
- ● установка катков, которые служат для продольного и поперечного перемещения трансформато-ров;
- ● установка пробивного предохранителя на стороне низкого напряжения;
- ● установка контактных зажимов;
- ● для измерения температуры верхних слоев масла, на крышке трансформатора может устанавли-ваться термометр, термометрический сигнализатор;
- ● установка газового реле.
Структура условного обозначения (Расшифровка)
- ● ТМ — Х/6(10) У(ХЛ)1
- ● Т – трансформатор трехфазный,
- ● М – охлаждение масляное с естественной циркуляцией воздуха и масла,
- ● Х – номинальная мощность, кВА,
- ● 10(6) – класс напряжения обмотки ВН, кВ,
- ● У(ХЛ)1 – климатическое исполнение и категория
Технические данные и габаритно-весовые характеристики
| 1 — Ввод НН; 2 — ввод ВН; 3 — маслорасшеритель; 4 — табличка паспортная; 5 — петли подъемные; 6 — пробка для слива масла; 7 — привод переключателя; 8 — воздухоосушитель; 9 — пробка для заливки масла; 10 — клемма заземления; 11 — маслоуказатель; 12 — радиатор; | |
Номинальная мощность трансформаторов кВт | Потери Вт | Ток ХХ, % | Напря жение КЗ,% | Габаритные размеры, мм | Масса, кг | |
|---|---|---|---|---|---|---|
ХХ | КЗ | |||||
ТМ-25 | 120 | 600 | 3,2 | 4,5 | 800 х 430 х 970 | 320 |
Трансформатор ТДН 10000/110/6 характеристики, размеры
Трехфазный двухобмоточный трансформатор с устройством РПН номинальной мощностью 10 МВА (Мега вольт-ампер)
предназначен для использования в электрических сетях
с номинальным напряжением
110, 6 кВ.![]() Частота сети 50 Гц.
Частота сети 50 Гц.
Расшифровка
- Т — трехфазный,
- Д — система охлаждения дутьевая (естественная циркуляция масла и принудетельная циркуляция воздуха),
- Н — наличие регулирования под нагрузкой,
- 10000 — номинальная полная мощность (кВА),
- 110/6 — классы номинального напряжения сети.
| Sн, МВА | Uвн, кВ | Uсн, кВ | Uнн, кВ | ΔPx, кВт | ΔPквн, кВт | ΔPквс, кВт* | Uкв-с, % | Uкв-н, % | Uкс-н, % | Ix, % | Sнн, МВА |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 115 | — | 6,6 | 14 | 58 | — | — | 10,5 | — | 0,9 | — |
*Обычно приводится для автотрансформаторов.
- Sн
- Полная номинальная мощность трансформатора (автотрансформатора) в МВА;
- Uвн
- Номинальное напряжение обмотки высшего напряжения в кВ;
- Uсн
- Номинальное напряжение обмотки среднего напряжения в кВ;
- Uнн
- Номинальное напряжение обмотки низшего напряжения в кВ;
- ΔPx
- Потери мощности холостого хода в кВт;
- ΔPквн
- Потери мощности короткогозамыкания (высокая — низкая) в кВт;
- ΔPквс
- Потери мощности короткогозамыкания (высокая — средняя) в кВт;
- Uкв-с
- Напряжение короткого замыкания (высокая — средняя) в %;
- Uкв-н
- Напряжение короткого замыкания (высокая — низкая) в %;
- Uкс-н
- Напряжение короткого замыкания (средняя — низкая) в %;
- Ix
- Ток холостого хода в %;
- Sнн
- Полная номинальная мощность обмотки низкого напряжения.
Обозначение на схеме
Характеристики ТДН 10000/110/6
| Тип трансформатора | ТДН |
| Номинальная мощность Sн, МВА | 10 |
| Количество обмоток и тип | Двухобмоточный трансформатор |
| Напряжение сети стороны ВН Uном.сети, кВ | 110 |
| Напряжение обмотки ВН Uвн, кВ | 115 |
| Напряжение обмотки СН Uсн, кВ | — |
| Напряжение обмотки НН Uнн, кВ | 6,6 |
| Потери холостого хода ΔPxx, кВт | 14 |
| Потери короткого замыкания ΔPкз, кВт | 58 |
| Напряжение Ukв-н, % | 10,5 |
| Ток Ixx, % | 0,9 |
Схема замещения
Двухобмоточный трансформатор
- Rт
- Активное сопротивление обмоток трансформатора, Ом;
- Xт
- Реактивное сопротивление обмоток трансформатора, Ом;
- Bт
- Реактивная проводимость, См;
- Gт
- Активная проводимость, См;
Схема замещения с потерями мощности холостого хода.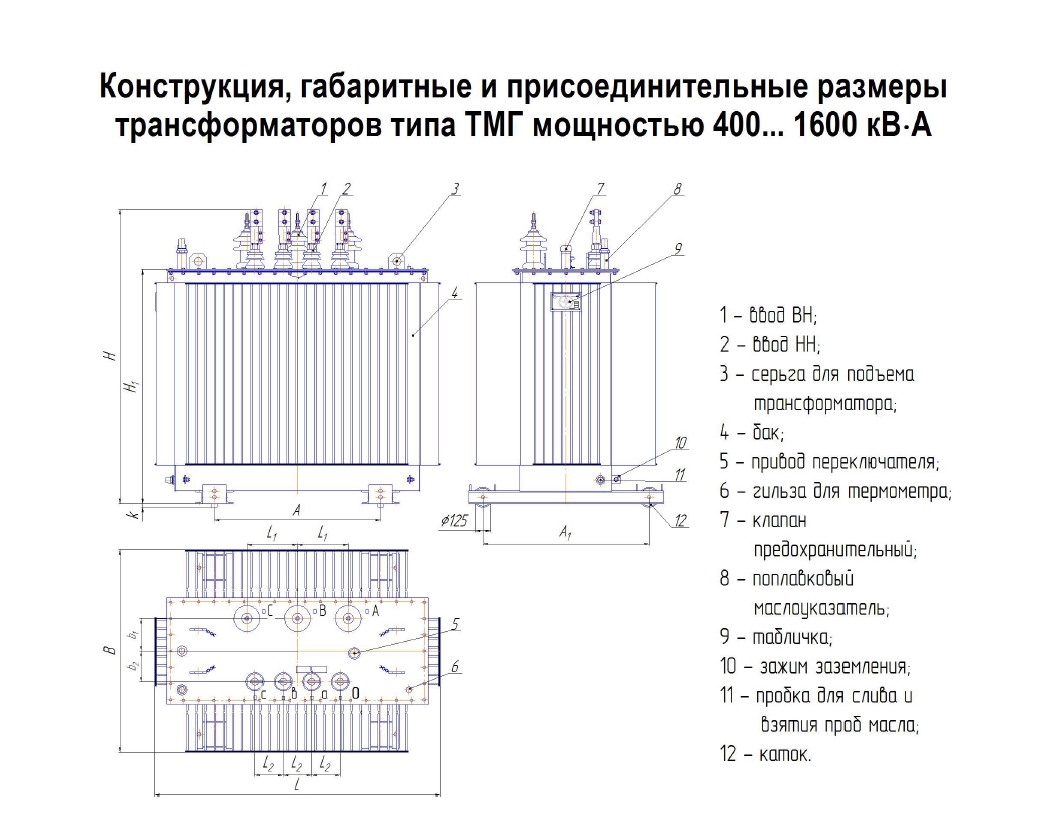 {-6}\left[См\right]\]
{-6}\left[См\right]\]
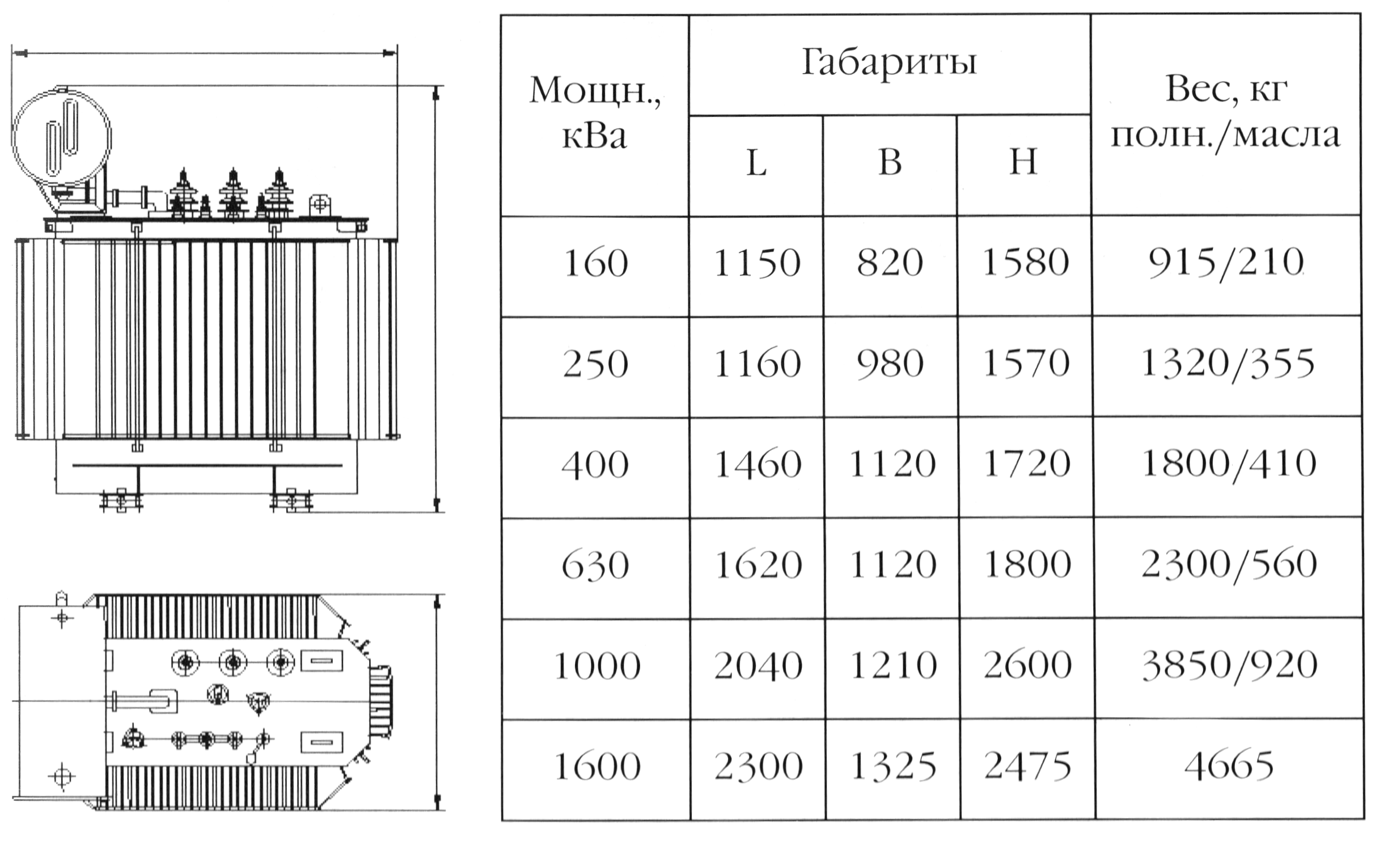
Трансформаторы ТМ-25, ТМ-40, ТМ-63, ТМ-100, ТМ-160, ТМ-250, ТМ-400, ТМ-630, ТМ-1000, ТМ-1600, ТМ-2500
Силовые масляные трехфазные двухобмоточные понижающие общепромышленного назначения трансформаторы ТМ мощностью от 25 до 2500 кВА предназначены для внутренней и наружной установки.Для увеличения поверхности охлаждения в трансформаторах ТМ — 25…2500 с маслорасширителем, применяются гофрированные стенки, ТМ-1600-2500 – радиаторы.
Силовые трансформаторы ТМ-25-2500 выпускаются с номинальным напряжением первичной обмотки (высокого напряжения) до 10 кВ, включительно, и вторичной обмотки (низкого напряжения) – 0,4 кВ. Схема и группа соединений – Y/Yн-0, Д/Yн-11.
Трансформаторы состоят из активной части, крышки и сварного бака овальной формы. На крышке расположены вводы ВН и НН, привод переключателя, расширитель с маслоуказателем и воздухоосушителем.
Активная часть состоит из магнитопровода с обмотками, нижних и верхних ярмовых балок, переключателя ответвлений обмоток.
 Магнитная система трансформатора плоскошихтованная, стержневого типа, собирается из холоднокатаной электротехнической стали.
Магнитная система трансформатора плоскошихтованная, стержневого типа, собирается из холоднокатаной электротехнической стали.Конструкция обмоток трансформатора — цилиндрическая. Обмотки ВН имеют регулировочные отводы. При изготовлении обмоток применена блочная намотка (т.е. обмотка Вн наматывается на обмотку НН).
Активная часть трансформатора жестко закреплена в верхней части бака в четырех местах распорными винтами. Над активной частью установлен переключатель, к неподвижным контактам которого присоединены регулировочные отводы обмоток ВН.
В верхней части бака приварены крюки для подъема трансформатора. В нижней части бака имеется пластина заземления и пробка для слива масла. Конструкция пробки позволяет брать пробу масла при частичном ее отвинчивании. Ко дну бака приварены полосы с отверстиями для крепления трансформатора к фундаменту.
Расшифровка ТМ
ТМ-ХХ/Y-ZZ-У1:
Т — трехфазный трансформатор;
М — маслянный;
ХХ — номинальная мощность, кВ*А;
Y — класс напряжения обмотки, кВ;
ZZ — год разработки;
У1 — климатическое исполнение и категория размещения
Технические характеристики трансформаторов ТМ
Тип трансформатора | Мощность, кВА | Напряжение | Схема и группа соединения | Напряжение КЗ, % | Потери, Вт | Габаритные размеры, мм | Масса, кг | ||||
ВН | НН | ХХ | КЗ | L | B | H | |||||
| ТМ — 25 | 25 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 110 | 600 | 980 | 365 | 1 065 | 250 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | Y/Zн — 11 | 1010 | 425 | 1155 | 270 | ||||||
| ТМ — 40 | 40 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 150 | 880 | 1010 | 425 | 1155 | 290 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | Y/Zн — 11 | 870 | 485 | 1 195 | 308 | ||||||
| ТМ — 63 | 1600 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 220 | 1280 | 870 | 485 | 1195 | 360 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | Y/Zн — 11 | 1030 | 635 | 1175 | 377 | ||||||
| ТМ — 100 | 100 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 305 | 1970 | 1020 | 650 | 1150 | 495 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | Y/Zн — 11 | 1230 | 600 | 1435 | 510 | ||||||
| 6, 10 | 0,23 | Y/Yн — 0 | 4,5 | 410 | 2650 | 1215 | 715 | 1240 | 500 | ||
| ТМ — 160 | 160 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 410 | 2 650 | 1130 | 820 | 1425 | 725 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | Y/Zн — 11 | 1320 | 780 | 1495 | 750 | ||||||
| 6, 10 | 0,23 | Yн/Д — 11 | 1215 | 680 | 1500 | 743 | |||||
| ТМ — 250 | 250 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 550 | 3700 | 1320 | 780 | 1495 | 990 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | Y/Zн — 11 | 1425 | 790 | 1665 | 1008 | ||||||
| 6, 10 | 0,23 | Y/Yн — 0 | 1305 | 830 | 1660 | 1000 | |||||
| ТМ — 400 | 400 | 6, 10 | 0,4 | Y/Yн — 0 | 4,5 | 830 | 5500 | 1305 | 830 | 1660 | 1285 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | 0,23 | Yн/Д — 11 | 1290 | ||||||||
| ТМ — 630 | 630 | 6, 10 | 0,4 | Y/Yн — 0 | 5,5 | 1050 | 7600 | 1600 | 1000 | 1590 | 1795 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | 0,23 | Yн/Д — 11 | 1803 | ||||||||
| ТМ — 1000 | 1000 | 6, 10 | 0,23 | Yн/Д — 11 | 5,5 | 1550 | 10800 | 1765 | 1000 | 1930 | 2920 |
| 6, 10 | 0,4 | Y/Yн — 0 | |||||||||
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | 0,69 | ||||||||||
| 6, 10 | 3,15 | Y/Д — 11 | |||||||||
| 6, 10 | 6,3 | ||||||||||
| ТМ — 1600 | 1600 | 6, 10 | 0,4 | Y/Yн — 0 | 6,0 | 2050 | 16000 | 2200 | 1250 | 2400 | 4750 |
| 6, 10 | Д/Yн — 11 | ||||||||||
| 6, 10 | 0,69 | Д/Yн — 11 | |||||||||
| 6, 10 | 3,15 | Y/Д — 11 | |||||||||
| 6, 10 | 6,3 | Y/Д — 11 | |||||||||
| ТМ — 2500 | 2500 | 6, 10 | 0,4 | Д/Yн — 11 | 6,0 | 2800 | 24000 | 2370 | 1330 | 2900 | 6980 |
Трансформаторы
ТМ(Г) – это силовые трехфазные двухобмоточные трансформаторы. Они относится к трансформаторам понижающего типа на масляном охлаждении. ТМ(Г) преобразуют переменный ток и распределяют электроэнергию в различных электротехнических установках. Силовые трансформаторы делятся на понижающие и повышающие. Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТМ(Г) — Т1\Т2\Т3 У/Ун-0:
Они относится к трансформаторам понижающего типа на масляном охлаждении. ТМ(Г) преобразуют переменный ток и распределяют электроэнергию в различных электротехнических установках. Силовые трансформаторы делятся на понижающие и повышающие. Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТМ(Г) — Т1\Т2\Т3 У/Ун-0:
- Т – трехфазный;
- М – охлаждается от окружающей среды, с использованием масла;
- (Г) – виды защиты масла: герметичные;
- Т1 – номинальная мощность;
- Т2/Т3– класс напряжения обмотки ВН и НН;
- У/Ун-0 – схема и группа соединения обмоток;
ТС(З)(Г)Л — это сухие силовые трансформаторы и не имеют масляного охладителя, его заменяет естественная среда. Они являются разновидностью силовых трансформаторов. Если вы решили купить сухой трансформатор – то сделали правильный выбор. Они могут быть установлены вблизи от потребителей, так как являются пожаробезопасными. К тому же сухой трансформатор меньше размером, чем маслянный. Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТС(З)(Г)Л — Т1\Т2\Т3 Д/Ун-11:
Рассмотрим расшифровку обозначения силовых трансформаторов на примере ТС(З)(Г)Л — Т1\Т2\Т3 Д/Ун-11:
- Т – трехфазный;
- С – охлаждается от окружающей среды, без использования масла;
- З – имеется защитный кожух;
- Г – в обмотку добавлен кварцевый компаунд «ГЕАФОЛЬ»;
- Л – эпоксидная изоляция обмотки;
- Т1 – номинальная мощность;
- Т2/Т3– класс напряжения обмотки ВН и НН;
- Д/Ун-11 – схема и группа соединения обмоток.
Трансформаторы серии ТМГ предназначены для работы в умеренном и холодном климате. Для работы необходима окружающая среда, не содержащая взрывоопасных и легковоспламеняющихся веществ. Также они не выдерживают тряски, вибрации и ударов. Напряжение настраивается на отключенном полностью трансформаторе переключением ответвлений его обмотки переключателем типа ПБВ.
На современных трансформаторах установлены поплавковые маслоуказатели, для того, чтобы измерять уровень масла. Обезопасить трансформатор мощностью до 63 кВА от избыточного давления поможет специальный предохранительный клапан. По желанию клиента на трансформаторах мощностью выше 100 кВА. устанавливается вакуумметр.
По желанию клиента на трансформаторах мощностью выше 100 кВА. устанавливается вакуумметр.
Также на такие трансформаторы устанавливаются термометры для измерения температуры масла. На большие трансформаторы (мощностью более 630 кВА) устанавливаются ролики для его перемещения по разным направлениям. Также можно установить ролики на меньшие трансформаторы.
При производстве трансформаторов ТМГ используются передовые технологии, благодаря чему повышаются эксплуатационные характеристики, долговечность и надежность. Изделие является герметичным и полностью заполняется маслом без воздушной подушки. Масло не вступает в контакт с окружающей средой, поэтому оно не окисляется и не загрязняется.
Перед использованием масла из него удаляются все газы. В бак оно заливается в вакуумной камере. Благодаря этому из масла выходит весь воздух. Также удаляются из емкости различные воздушные и газовые подушки. Благодаря этому обеспечивается высокая устойчивость изоляции трансформатора к электрическим нагрузкам и долговечность устройства.![]() Масло при такой заливке не подвержено окислению и практически не портится на протяжении всего времени эксплуатации. Заявленный срок службы трансформатора – 25 лет.
Масло при такой заливке не подвержено окислению и практически не портится на протяжении всего времени эксплуатации. Заявленный срок службы трансформатора – 25 лет.
Масло силовых трансформаторов ТМ, ТМГ и т.д., большинства заводов изготовителей проходит процедуру дегазации. Что позволяет увеличить срок иксплуатации изделия.
У нас вы можете купить силовые трансформаторы как повышающие, так и понижающие, с минимальными сроками и наличием на складе (по заявке). Мы продаем трансформаторы от 16 кВА до 3150кВА.Также мы предлагаем вам однофазные трансформаторы ОМП, которые предназначены для питания систем безопасности и прочих однофазных приборов. Производитель дает гарантию на трансформаторы от 3 до 5 лет.
Скачать опросный лист на ТМГ
Руководство по декодированию нейронного машинного перевода без авторегрессии с переупорядочиванием информации — arXiv Vanity
Аннотация
Неавторегрессивный нейронный машинный перевод (NAT) генерирует каждое целевое слово параллельно и обеспечивает многообещающее ускорение вывода. Однако существующие модели NAT по-прежнему имеют большой разрыв в качестве перевода по сравнению с моделями авторегрессионного нейронного машинного перевода из-за огромного пространства для декодирования. Чтобы решить эту проблему, мы предлагаем новую структуру NAT ReorderNAT, которая явно моделирует информацию о переупорядочении в процедуре декодирования.Мы также вводим детерминированные и недетерминированные стратегии декодирования, которые используют информацию переупорядочения, чтобы сузить пространство поиска декодирования в предлагаемом нами ReorderNAT. Результаты экспериментов с различными широко используемыми наборами данных показывают, что предлагаемая нами модель обеспечивает лучшую производительность по сравнению с существующими моделями NAT и даже обеспечивает сопоставимое качество перевода с моделями авторегрессионного перевода со значительным ускорением.
Однако существующие модели NAT по-прежнему имеют большой разрыв в качестве перевода по сравнению с моделями авторегрессионного нейронного машинного перевода из-за огромного пространства для декодирования. Чтобы решить эту проблему, мы предлагаем новую структуру NAT ReorderNAT, которая явно моделирует информацию о переупорядочении в процедуре декодирования.Мы также вводим детерминированные и недетерминированные стратегии декодирования, которые используют информацию переупорядочения, чтобы сузить пространство поиска декодирования в предлагаемом нами ReorderNAT. Результаты экспериментов с различными широко используемыми наборами данных показывают, что предлагаемая нами модель обеспечивает лучшую производительность по сравнению с существующими моделями NAT и даже обеспечивает сопоставимое качество перевода с моделями авторегрессионного перевода со значительным ускорением.
1 Введение
Модели нейронного машинного перевода (NMT) с фреймворком кодировщика-декодера (sutskever2014sequence; bahdanau2014neural) значительно превосходят традиционные статистические модели машинного перевода (koehn2003statistical; koehn2007moses) по качеству перевода. Несмотря на свой успех, современные модели NMT обычно страдают от низкой скорости вывода, которая стала узким местом для применения NMT в реальных системах перевода. Низкая скорость вывода моделей NMT обусловлена их авторегрессивным свойством, то есть пословным декодированием целевого предложения в соответствии с историей переводов.
Несмотря на свой успех, современные модели NMT обычно страдают от низкой скорости вывода, которая стала узким местом для применения NMT в реальных системах перевода. Низкая скорость вывода моделей NMT обусловлена их авторегрессивным свойством, то есть пословным декодированием целевого предложения в соответствии с историей переводов.
Недавно в gu2017non был введен неавторегрессивный протокол NMT (NAT), который может одновременно декодировать все целевые слова, чтобы устранить узкое место в моделях авторегрессионного NMT (AT).С этой целью NAT модели (gu2017non; wei2019imitation; wang2019non; guo2019non; shao2019retrieving) обычно напрямую копирует представления исходного слова на вход декодера вместо использования ранее предсказанных представлений целевого слова. Следовательно, логический вывод различных целевых слов независим, что позволяет параллельное вычисление декодера в моделях NAT. Модели NAT могут достичь 10-15-кратного ускорения по сравнению с моделями AT при сохранении значительного качества перевода.
Однако существующие системы NAT игнорируют зависимости между целевыми словами и одновременно генерируют все целевые слова, что делает пространство поиска в процедуре декодирования слишком большим, чтобы его можно было хорошо смоделировать. В частности, при декодировании целевого слова, чтобы определить, из какой части исходного предложения оно переведено, модели NAT должны искать в большом глобальном пространстве гипотез, чтобы сделать вывод, что выражено его предыдущими и последними словами в переводе. Следовательно, проблема большого пространства для декодирования заставляет модели NAT генерировать перевод, обусловленный меньшим количеством или неточной исходной информацией, что приводит к отсутствующим, повторяющимся и даже неправильным переводам.Эта проблема не является серьезной для моделей AT, потому что ей нужно только декодировать целевое слово в небольшом локальном пространстве гипотез, обусловленном ранее переведенными словами.
Рисунок 1: Структура нашей модели ReorderNAT. В отличие от исходных моделей NAT, наша модель добавляет модуль переупорядочения между модулем кодировщика и модулем декодера для явного моделирования информации переупорядочения. Для исходной модели NAT входы декодера — это скопированные вложения исходного предложения (пунктирная стрелка №1), а для модели ReorderNAT входы декодера представляют собой вложения псевдотрансляции.
В отличие от исходных моделей NAT, наша модель добавляет модуль переупорядочения между модулем кодировщика и модулем декодера для явного моделирования информации переупорядочения. Для исходной модели NAT входы декодера — это скопированные вложения исходного предложения (пунктирная стрелка №1), а для модели ReorderNAT входы декодера представляют собой вложения псевдотрансляции. В этой статье для решения этой проблемы мы предлагаем новую структуру NAT под названием ReorderNAT, которая явно моделирует информацию переупорядочения для управления декодированием NAT. Чтобы быть конкретным, как показано на рисунке 1, ReorderNAT сначала переупорядочивает исходное предложение в псевдоперевод, образованный исходными словами, но в структуре целевого языка, а затем переводит псевдоперевод на целевой язык, чтобы получить окончательный перевод. Далее мы представляем две руководящие стратегии декодирования, которые используют информацию о переупорядочении (т.е. псевдоперевод), чтобы указать направление поиска при декодировании. Первый — это детерминированное управляющее декодирование, которое сначала генерирует наиболее вероятный псевдоперевод, а затем на его основе генерирует целевое предложение. Второй — это недетерминированное направляющее декодирование, которое использует условное распределение псевдоперевода в качестве скрытой переменной для управления декодированием целевого предложения.
Первый — это детерминированное управляющее декодирование, которое сначала генерирует наиболее вероятный псевдоперевод, а затем на его основе генерирует целевое предложение. Второй — это недетерминированное направляющее декодирование, которое использует условное распределение псевдоперевода в качестве скрытой переменной для управления декодированием целевого предложения.
Пространство поиска в процедуре декодирования ReorderNAT намного меньше, чем все пространство декодирования исходного NAT: (1) пространство декодирования модуля переупорядочения при генерации псевдотрансляции ограничено перестановкой исходных слов; (2) с руководством по переупорядочиванию информации для каждого целевого слова то, что оно выражается, может быть почти сужено до соответствующего слова псевдоперевода в той же позиции.Следовательно, ReorderNAT может эффективно сократить пространство поиска декодирования, вводя информацию переупорядочения в NAT.
Экспериментальные результаты нескольких широко используемых общедоступных тестов показывают, что предлагаемая нами модель ReorderNAT обеспечивает значительные и последовательные улучшения по сравнению с существующими моделями NAT за счет явного моделирования информации переупорядочения для управления декодированием. Более того, вводя простой, но эффективный AT-декодер для моделирования информации о переупорядочении, наш ReorderNAT значительно сокращает разрыв в качестве трансляции между моделями AT и NAT, сохраняя при этом значительное ускорение (почти в шесть раз быстрее).Мы выпустим все исходные коды и связанные ресурсы этой работы для дальнейших исследований.
Более того, вводя простой, но эффективный AT-декодер для моделирования информации о переупорядочении, наш ReorderNAT значительно сокращает разрыв в качестве трансляции между моделями AT и NAT, сохраняя при этом значительное ускорение (почти в шесть раз быстрее).Мы выпустим все исходные коды и связанные ресурсы этой работы для дальнейших исследований.
2 Фон
Неавторегрессивный нейронный машинный перевод (NAT) впервые предложен gu2017non для решения проблемы медленного декодирования моделей авторегрессионного нейронного машинного перевода (AT), которые могут одновременно генерировать целевые слова, удаляя их зависимости. Формально, учитывая исходное предложение X = {x1, ⋯, xn} и целевое предложение Y = {y1, ⋯, ym}, NAT моделирует вероятность перевода из X в Y как произведение условно независимой вероятности целевого слова:
| P (Y | X) = m∏i = 1P (yi | X). | (1) |
Вместо использования предыдущей истории трансляций модели NAT обычно копируют последовательность представлений исходного слова в качестве входных данных декодера. Следовательно, при переводе предложения модели NAT могут предсказывать все целевые слова с их максимальной вероятностью индивидуально, нарушая зависимость между целевыми словами, и, следовательно, процедура декодирования моделей NAT выполняется параллельно и имеет очень низкую задержку перевода.
Следовательно, при переводе предложения модели NAT могут предсказывать все целевые слова с их максимальной вероятностью индивидуально, нарушая зависимость между целевыми словами, и, следовательно, процедура декодирования моделей NAT выполняется параллельно и имеет очень низкую задержку перевода.
Однако, поскольку модели NAT отбрасывают последовательные зависимости между словами в целевом предложении, они страдают от потенциального снижения производительности из-за резкого увеличения пространства поиска декодирования.Чтобы быть конкретным, при декодировании целевого слова модель NAT должна иметь возможность выяснить не только, какую информацию на стороне цели описывает слово, но также и то, что выражается другими целевыми словами. Из-за стремительного роста пространства поиска декодирования модели NAT не могут эффективно изучать сложные шаблоны перевода от исходных предложений к целевым предложениям, что приводит к низкому качеству перевода.
Сравнение моделей и онлайн-приложение
6. Ссылки
Ссылки
[1] A.Крижевский, И. Суцкевер и Г.Е. Хинтон, «Класс ImageNet с глубокими сверточными нейронными сетями», в NIPS, 2012.
1
[2] К. Симонян и А. Зиссерман, «Очень глубокая сверточная сеть. —
работы по распознаванию крупномасштабных изображений », в Международной конференции по обучающим представлениям, 2015. 1
[3] К. Хе, Х. Чжан, С. Рен и Дж. Сан,« Глубокий остаточное обучение для распознавания изображений
, препринт arXiv arXiv: 1512.03385, 2015. 1,6
[4] С. Иоффе и К. Сегеди, «Пакетная нормализация: ускорение глубокого обучения сети
за счет уменьшения внутреннего ковариантного сдвига», в Proc.
ICML, 2015. 1
[5] Дж. С. Чанг и А. Зиссерман, «Чтение по губам в дикой природе», в Proc.
ACCV, 2016. 1
[6] Дж. С. Чанг, А. Сеньор, О. Виньялс и А. Зиссерман, «Губное чтение —
предложений в дикой природе», в Proc. CVPR, 2017. 1,3
[7] И. Суцкевер, О. Виньялс, К.Ле, «Последовательность для последовательного обучения —
с помощью нейронных сетей», в NIPS, 2014. 1
1
[8] К. Чо, Б. ван Мерри
enboer, C¸. G¨
ulc¸ehre, D. Bahdanau,
F. Bougares, H. Schwenk и Y. Bengio, «Репрезентация обучающей фразы
с использованием кодировщика-декодера rnn для статистической машины
перевод» в ЕМНЛП , Октябрь 2014 г. 1
[9] Д. Бахданау, К. Чо и Ю. Бенжио, «Трансформация нейронной машины
путем совместного обучения выравниванию и трансляции», CoRR, vol.
abs / 1409.0473, 2014. 1
[10] A. Graves, S. Fern´
andez, F. Gomez, J. Schmidhuber, «Con-
неконтиционистская временная классификация: маркировка несегментированных сегментов
. обрабатывать данные с помощью рекуррентных нейронных сетей », в Proc. ICML.
ACM, 2006. 1
[11] А. Грейвс, «Последовательная трансдукция с рекуррентной нейронной сетью —
работ», CoRR, vol. abs / 1211.3711, 2012. 1
[12] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L.Джонс, AN
Гомес, Л. Кайзер и И. Полосухин, «Внимание — все, что вам нужно»,
Полосухин, «Внимание — все, что вам нужно»,
в NIPS, 2017. 1,2
[13] Дж. С. Чанг и А. Зиссерман, «Обучение губам. читать слова
смотреть видео », CVIU, 2018. 1
[14] YM Assael, B. Shillingford, S. Whiteson, N. de Fre-
itas,« Lipnet: чтение по губам на уровне предложений », arXiv препринт
arXiv: 1611.01599, 2016. 1,2,3
[15] Дж. С. Чанг, А. Зиссерман, «Чтение по губам в профиле», в Proc.
BMVC., 2017. 1,3
[16] Т. Стафилакис и Г. Цимиропулос, «Объединение остаточной сетки-
работает с lstms для чтения по губам», Interspeech, 2017. 1,2,3,
6
[17] С. Петридис, Т. Стафилакис, П. Ма, Ф. Кай, Г. Цимиропулос и
М. Пантик, «Сквозное аудиовизуальное распознавание речи», CoRR,
vol. abs / 1802.06424, 2018. 1
[18] С. Бай, Дж. З. Колтер и В. Колтун, «Эмпирическая оценка общих сверточных и рекуррентных сетей
для последовательного моделирования
eling», препринт arXiv arXiv: 1803 . 1
1
[20] Дж. Геринг, М. Аули, Д. Гранжье, Д. Яратс и Ю. Н. Дофин,
«Сверточная последовательность для обучения последовательности», в ICML, 2017. 1
[21] Н. Кальхбреннер, Л. Эспехольт, К. Симонян, А. ван ден Оорд,
А. Грейвс, К. Кавукчуоглу, «Нейронный машинный перевод в линейном времени
», CoRR, vol.abs / 1610.10099, 2016. 1
[22] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals,
A. Graves, N. Kalchbrenner, AW Senior, and K. Kavukcuoglu,
«Wavenet: генеративная модель для необработанного звука», в ISCA Speech
Synthesis Workshop, 2016. 1
[23] Л. Кайзер, А. Н. Гомес и Ф. Чолле, «Разделение по глубине —
ble свертки для нейронного машинного перевода », препринт arXiv
arXiv: 1706.03059, 2017. 1
[24] F.Шолле, «Xception: глубокое обучение с глубинным разделением
сверток», в Proc. CVPR, 2017. 1,2
[25] Я. Ван, Х. Дэн, С. Пу и З. Хуанг, «Остаточные сверточные сети CTC для автоматического распознавания речи», arXiv
препринт arXiv: 1702. 07793, 2017. 1
07793, 2017. 1
[26] Y. Zhang, M. Pezeshki, P. Brakel, S. Zhang, C. Laurent, Y. Ben-
gio, и AC Courville, «На пути к сквозной речи. распознавание
с глубокими сверточными нейронными сетями, CoRR, т.
abs / 1701.02720, 2017. 1,4
[27] Р. Коллобер, К. Пурш и Г. Синнив, «Wav2letter: система распознавания речи на основе сквозной сети
», CoRR, т.
abs / 1609.03193, 2016. 1
[28] В. Липчинский, Г. Синнаев, Р. Коллобер, «Распознавание речи на основе Letter-
с закрытыми коннекторами», CoRR, vol.
abs / 1712.09444, 2017. 1
[29] Н. Зегидур, Н. Усуньер, И. Коккинос, Т. Шац, Г. Синнаев,
и Э.Дюпу, «Изучение банков фильтров по необработанной речи для распознавания телефона
», CoRR, vol. abs / 1711.01161, 2017. 1
[30] К. Раффель, Т. Луонг, П. Дж. Лю, Р. Дж. Вайс и Д. Эк, «Онлайн и
линейно-временное внимание путем принудительного монотонного выравнивания», CoRR,
т. abs / 1704. 00784, 2017. 1
00784, 2017. 1
[31] Y. Luo, C.-C. Чиу, Г. Брейн, Н. Джайтли и И. Суцкевер, «Learn-
онлайн-согласований с непрерывным градиентом политики вознаграждений»,
препринт arXiv arXiv: 1608.01281, 2017. 1
[32] С. Ким, М.Л. Зельцер, Дж. Ли и Р. Чжао, «Улучшенное обучение
для онлайн-систем сквозного распознавания речи», препринт arXiv
arXiv: 1711.02212 , 2017. 1
[33] К. Хван и В. Сунг, «Онлайн-последовательное обучение рекуррентных нейронных сетей
с коннекционистской временной классификацией», arXiv
препринт arXiv: 1511.06841, 2017. 1
[34] N Джайтли, К. В. Ле, О. Виньялс, И. Суцкевер, Д. Сусилло, и
S.Bengio, «Онлайн-модель последовательность-последовательность с частичным условием
», в NIPS, 2016. 1
[35] А. Грейвс и Н. Джайтли, «На пути к сквозному распознаванию речи
с повторяющимся нейронные сети », Труды 31-й Международной конференции по машинам
, Международная конференция по машинам
Обучение — Том 32, сер.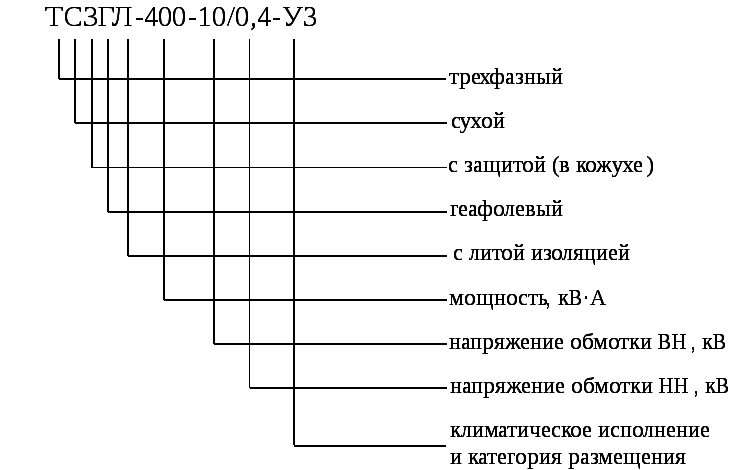 ICML, 2014. 2
ICML, 2014. 2
[36] AL Maas, Z. Xie, D. Jurafsky и AY Ng, «Распознавание разговорной речи без словаря
с помощью нейронных сетей», в Pro-
ceedings the North American Chapter of Ассоциация компьютерной лингвистики
(NAACL), 2015.2,6
[37] А. Каннан, Ю. Ву, П. Нгуен, Т. Н. Сайнат, З. Чен и
Р. Прабхавалкар, «Анализ включения внешней языковой модели
в последовательность -тоследовательная модель », препринт arXiv
arXiv: 1712.01996, 2017. 2,6
[38] Н. Шривастава, Г. Хинтон, А. Крижевский, И. Суцкевер,
Р. Салахутдинов,« Отказ : Простой способ предотвратить переобучение нейронной сети
», Журнал машинного обучения Re-
search, 2014.3
[39] Д. П. Кингма и Дж. Ба, «Адам: метод стохастической оптимизации
», в Proc. ICLR, 2015. 3
[40] A. Zeyer, E. Beck, R. Schl
uter, и H. Ney, «CTC в контексте
обобщенного обучения HMM с полной суммой», в INTERSPEECH,
2017. 4
4
[41] Z. Chen, Y. Zhuang, Y. Qian, K. Yu, Z. Chen, Y. Zhuang, Y. Qian,
K. Yu, K. Yu, Y. Чжуан, З. Чен и Ю. Цянь, «Phone syn-
Распознавание хронической речи с помощью ctc-решеток», IEEE / ACM Trans.
Аудио, речь и язык. Proc., 2017. 4
[42] А. Розенберг, К. Аудхаси, А. Сетхи, Б. Рамабхадран и
М. Пичени, «Сквозное распознавание речи и поиск по ключевым словам
на низком уровне. ресурсные языки »в ICASSP, 2017. 4
[43] Y. Wu, M. Schuster, Z. Chen, QV Le, M. Norouzi, W. Macherey,
M. Krikun, Y. Cao, Q. Гао, К. Машери, Дж. Клингнер, А. Шах,
М. Джонсон, Х. Лю, Л. Кайзер, С. Гоус, Ю. Като, Т. Кудо,
H.Казава, К. Стивенс, Г. Куриан, Н. Патил, В. Ван, К. Янг,
Дж. Смит, Дж. Риза, А. Рудник, О. Виньялс, Г. Коррадо,
М. Хьюз, и Дж. Дин, «Система нейронного машинного перевода Google
: преодоление разрыва между человеческим и машинным переводом
», CoRR, vol. abs / 1609.08144, 2016.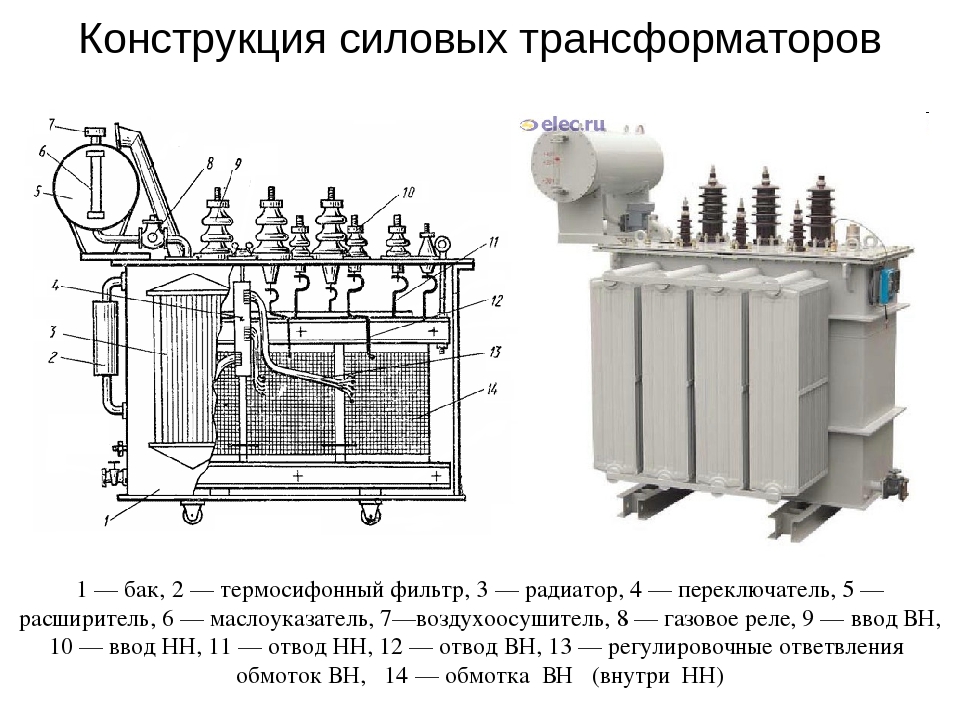 6
6
Последние достижения в области машинного обучения
Руководство для читателей
Что это за страница? На этой странице слева показаны таблицы, извлеченные из документов arXiv.Он показывает извлеченные результаты с правой стороны, которые соответствуют таксономии в Papers With Code.
Какие цветные прямоугольники справа? Здесь показаны результаты, извлеченные из статьи и связанные с таблицами слева. Результат состоит из значения метрики, имени модели, имени набора данных и имени задачи.
Что означают цвета? Зеленый означает, что результат одобрен и показан на сайте. Желтый — результат того, что вы добавили, но еще не сохранили.Синий — это результат ссылки, полученный из другой бумаги.
Откуда берутся предлагаемые результаты? У нас есть модель машинного обучения, работающая в фоновом режиме, которая дает рекомендации по статьям.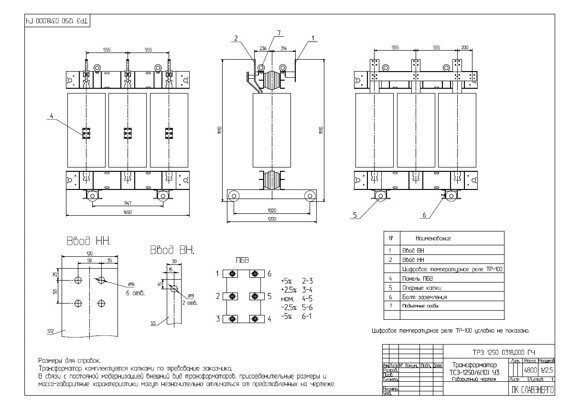
Откуда берутся ссылочные результаты? Если мы находим в таблице результаты со ссылками на другие статьи, мы показываем проанализированный справочный блок, который редакторы могут использовать для аннотирования, чтобы получить эти дополнительные результаты из других статей.
Руководство для редактора
Я впервые редактирую и боюсь ошибиться.Помощь! Не волнуйтесь! Если вы сделаете ошибки, мы можем исправить их: все версионировано! Так что просто сообщите нам на канале Slack, если вы что-то случайно удалили (и так далее) — это вообще не проблема, так что дерзайте!
Как добавить новый результат из таблицы? Щелкните ячейку в таблице слева, откуда берется результат. Затем выберите одно из 5 лучших предложений. Вы можете вручную отредактировать неправильные или отсутствующие поля. Затем выберите задачу, набор данных и название метрики из таксономии «Документы с кодом».Вы должны проверить, существует ли уже эталонный тест, чтобы предотвратить дублирование; если его не существует, вы можете создать новый набор данных.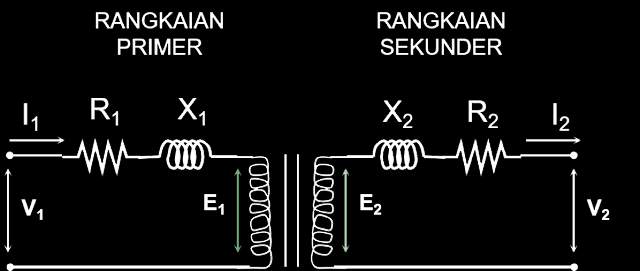 Например. ImageNet по классификации изображений уже существует с показателями Top 1 Accuracy и Top 5 Accuracy.
Например. ImageNet по классификации изображений уже существует с показателями Top 1 Accuracy и Top 5 Accuracy.
Каковы соглашения об именах моделей? Название модели должно быть простым, как указано в документе. Обратите внимание, что вы можете использовать круглые скобки для выделения деталей, например: BERT Large (12 слоев), FoveaBox (ResNeXt-101), EfficientNet-B7 (NoisyStudent).
Другие советы и рекомендации
- Если эталонный тест уже существует для введенной пары набор данных / задача, вы увидите ссылку.
- Если эталонный тест не существует, появится значок «новый», обозначающий новый рейтинг.
- Если вам повезет, Cmd + щелкните ячейку в таблице, чтобы получить первый результат автоматически.
- При редактировании нескольких результатов из одной таблицы вы можете нажать кнопку «Заменить все», чтобы скопировать текущее значение во все другие записи из этой таблицы.
Как добавить результаты, на которые имеются ссылки? Если в таблице есть ссылки, вы можете использовать функцию синтаксического анализа ссылок, чтобы получить больше результатов из других документов.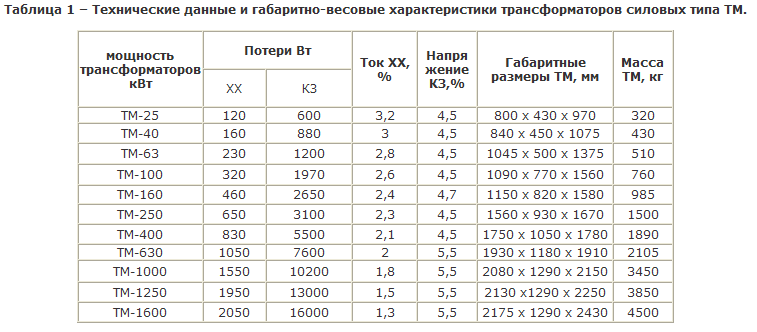 Во-первых, вам понадобится хотя бы одна запись в ячейке с результатами (пример см. На изображении ниже). Затем нажмите кнопку «Анализировать ссылки», чтобы связать ссылки с статьями в PapersWithCode и аннотировать результаты. Ниже вы можете увидеть пример.
Во-первых, вам понадобится хотя бы одна запись в ячейке с результатами (пример см. На изображении ниже). Затем нажмите кнопку «Анализировать ссылки», чтобы связать ссылки с статьями в PapersWithCode и аннотировать результаты. Ниже вы можете увидеть пример.
Как сохранить изменения? Когда вы будете довольны своим изменением, нажмите «Сохранить», и предложенные вами изменения станут зелеными!
Надюймов Facebook ближе к универсальным разведчикам с UniT
Недавно исследователи из Facebook AI Research (FAIR) представили новую модель Transformer с возможностью изучения задач в нескольких доменах одновременно, известную как Unified Transformer (UniT). По словам исследователей, модель Transformer принимает изображения и тексты в качестве входных данных и обучает входные данные для различных задач, от визуального восприятия и понимания языка до зрения и языковых рассуждений.
Зарегистрируйтесь для бесплатного AI Summit
За последние несколько лет модели Transformer доказали свою ценность в широком диапазоне областей, таких как естественный язык, изображения, видео, аудио и т. Д. Языковые модели, такие как BERT, GPT, XLNet, AlBERT, достигли огромных успехов.
Transformers, обученные на огромных наборах данных, могут выучить надежные представления для широкого круга последующих языковых задач. По словам исследователей, несмотря на достижения моделей Transformer для конкретных доменов, было не так много попыток связать несколько задач между доменами.
Исследователи искусственного интеллекта Facebook начали с вопроса: «Может ли Transformer, обученный логическому выводу на естественном языке при вводе текста, также выполнять обнаружение объектов на изображениях, или может ли классификатор изображений на основе Transformer также выполнять текстовое следствие?»
Присоединяйтесь к нашему серверу Discord.
 Станьте частью интересного онлайн-сообщества. Присоединиться здесь.
Станьте частью интересного онлайн-сообщества. Присоединиться здесь.За блоком
Модель UniT
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.UniT построен на архитектуре кодировщика-декодера Transformer и состоит из отдельных кодировщиков для каждого типа входной модальности, за которыми следует декодер с простыми головками для конкретных задач. UniT упаковывает модули кодирования, которые кодируют каждую входную модальность как последовательность скрытых состояний и декодер по закодированным входным модальностям, за которыми следуют выходные головки для конкретных задач, чтобы получить окончательные прогнозы для каждой данной задачи.
Смотрите такжеЗагрузите наше мобильное приложение
Исследователи заявили: «По сравнению с предыдущей работой по многозадачному обучению с помощью Transformers, мы обучаем Unified Transformer и достигаем производительности, сопоставимой с хорошо зарекомендовавшей себя предыдущей работой над гораздо большим разнообразием задач; это не только совместные задачи видения и языка, такие как визуальные ответы на вопросы (VQA), но также задачи только на видение, а также только на язык.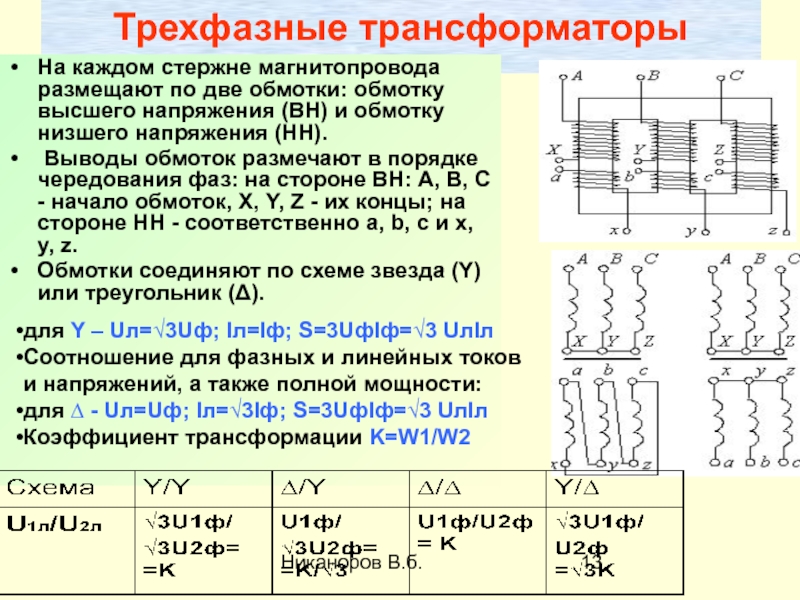 ”
”
- Исследователи предложили унифицированную архитектуру кодировщика-декодера Transformer под названием UniT, которая соединяет и изучает несколько задач и областей в единой модели.
- Модель совместно изучила задачи в визуальной и текстовой областях и их пересечениях, таких как визуальные ответы на вопросы, обнаружение объектов, визуальное следствие и задачи понимания естественного языка в тесте GLUE, включая QNLI, MNLI, QQP и SST-2 .Исследователи также показали, что этим разнообразным задачам можно заниматься одновременно, и они должным образом сходятся в рамках схемы обучения.
- Мультимодальные задачи, такие как визуальные ответы на вопросы (VQA) и визуальное следствие, выигрывают от многозадачного обучения с одномодальными задачами.
Исследователи искусственного интеллекта Facebook продемонстрировали, что фреймворк Transformer может применяться в различных доменах для обработки множества задач в рамках единой унифицированной модели кодировщика-декодера.Модель UniT одновременно решала семь задач в восьми различных наборах данных и обеспечивала отличную производительность по каждой задаче с помощью единого набора общих параметров.
По словам исследователей, модель UniT имеет архитектуру преобразователя, не зависящую от предметной области, что делает модель огромным шагом на пути к созданию универсальных разведывательных агентов, способных обрабатывать широкий спектр приложений в различных областях, включая визуальное восприятие, понимание языка и т. Д. и рассуждения о нескольких модальностях.
Прочтите все исследование здесь.
Амбика ЧоудхуриТехнический журналист, который любит писать о машинном обучении и искусственном интеллекте. Любитель музыки, сочинения и обучения чему-то нестандартному.
% PDF-1.6 % 3497 0 obj> эндобдж xref 3497 120 0000000016 00000 н. 0000004778 00000 п. 0000005101 00000 п. 0000005154 00000 н. 0000005572 00000 н. 0000005610 00000 п. 0000005688 00000 п. 0000006677 00000 н. 0000007319 00000 н. 0000008349 00000 п. 0000008882 00000 н. 0000009654 00000 п. 0000010024 00000 п. 0000010446 00000 п. 0000010916 00000 п. 0000011451 00000 п. 0000017154 00000 п. 0000020228 00000 п. 0000020632 00000 п. 0000021023 00000 п. 0000021232 00000 н. 0000027682 00000 н. 0000028083 00000 п. 0000029464 00000 н. 0000030887 00000 п. 0000031480 00000 п. 0000031735 00000 п. 0000033107 00000 п. 0000034252 00000 п. 0000041976 00000 п. 0000042531 00000 п. 0000043228 00000 п. 0000043608 00000 п. 0000043804 00000 п. 0000044205 00000 п. 0000045099 00000 н. 0000045322 00000 п. 0000045951 00000 п. 0000051043 00000 п. 0000051556 00000 п. 0000051952 00000 п. 0000052291 00000 п. 0000053877 00000 п. 0000054171 00000 п. 0000054503 00000 п. 0000054599 00000 п. 0000055791 00000 п. 0000056178 00000 п. 0000056414 00000 п. 0000056990 00000 п. 0000061741 00000 п. 0000062147 00000 п. 0000063647 00000 п. 0000064991 00000 п. 0000067662 00000 п. 0000095335 00000 п. 0000095409 00000 п. 0000095498 00000 п. 0000095644 00000 п. 0000095731 00000 п. 0000095785 00000 п. 0000095957 00000 п. 0000096050 00000 п. 0000096104 00000 п. 0000096195 00000 п. 0000096357 00000 п. 0000096507 00000 п. 0000096561 00000 п. 0000096655 00000 п. 0000096768 00000 п. 0000096822 00000 н. 0000096979 00000 п. 0000097033 00000 п. 0000097206 00000 п. 0000097260 00000 п. 0000097432 00000 п. 0000097513 00000 п. 0000097567 00000 п. 0000097719 00000 п. 0000097848 00000 н. 0000097901 00000 п. 0000098009 00000 п. 0000098128 00000 п. 0000098181 00000 п. 0000098302 00000 п. 0000098355 00000 п. 0000098480 00000 п. 0000098536 00000 п. 0000098645 00000 п. 0000098695 00000 п. 0000098806 00000 п. 0000098862 00000 п. 0000098916 00000 п. 0000099091 00000 п. 0000099145 00000 п. 0000099276 00000 н. 0000099330 00000 н. 0000099463 00000 н. 0000099517 00000 п. 0000099606 00000 н. 0000099660 00000 н. 0000099714 00000 н. 0000099768 00000 н. 0000099822 00000 н. 0000099959 00000 н. 0000100013 00000 н. 0000100132 00000 н. 0000100186 00000 н. 0000100299 00000 н. 0000100353 00000 н. 0000100450 00000 н. 0000100504 00000 н. 0000100558 00000 н. 0000100606 00000 н. 0000100735 00000 н. 0000100789 00000 н. 0000100843 00000 н. 0000100897 00000 н. 0000004536 00000 н. 0000002755 00000 н. трейлер ] >> startxref 0 %% EOF 3616 0 obj> поток x ڔ VkPWI6 ayh # mPj7Q * «N) ƨv @ NPik6ZqJZ4 ڢݥ hg2wsf7
Оптимизированные модели трансформаторов для ответов на часто задаваемые вопросы
1.Ба, Дж., Каруана, Р .: Действительно ли глубокие сети должны быть глубокими? In: NIPS, pp. 2654–2662 (2014)
2. Бергер, А., Каруана, Р., Кон, Д., Фрейтаг, Д., Миттал, В .: Преодоление лексической пропасти: статистические подходы к ответу -поиск. В: SIGIR, pp. 192–199 (2000)
3. Чаттерджи, А., Гупта, М., Агравал, П .: FAQaugmenter: предлагать вопросы для корпоративных страниц часто задаваемых вопросов. В: WSDM, стр. 829–832 (2020)
4. Chen, T., et al. : автоматизированный компилятор сквозной оптимизации для глубокого обучения.В: OSDI, стр. 578–594 (2018) 5. Ченг, Ю., Ван, Д., Чжоу, П., Чжан, Т .: Обзор сжатия и ускорения модели для глубоких нейронных сетей. Препринт arXiv arXiv: 1710.09282 (2017) 6. Девлин, Дж., Чанг, М., Ли, К., Тутанова, К .: Берт: предварительная подготовка глубоких двунаправленных преобразователей для понимания языка. Препринт arXiv arXiv: 1810.04805 (2018)7. Гупта, С., Карвалью, В .: Поиск FAQ с использованием внимательного сопоставления. В: СИГИР, стр. 929–932 (2019)
8. Хаммонд, К., Берк, Р., Мартин, К., Lytinen, S .: FAQ finder: тематический подход к навигации по знаниям. В кн .: Конференция по прикладному искусственному интеллекту, т. 114 (1995)
9. Хинтон, Г., Виньялс, О., Дин, Дж .: Преобразование знаний в нейронную сеть. Препринт arXiv arXiv: 1503.02531 (2015) 10. Хохрайтер С., Шмидхубер Дж. Долговременная кратковременная память. Neural Comput. 1997. 9 (8): 1735–1780. DOI: 10.1162 / neco.1997.9.8.1735. [PubMed] [CrossRef] [Google Scholar]11. Jijkoun, V., de Rijke, M .: Получение ответов со страниц часто задаваемых вопросов в Интернете.In: CIKM, pp. 76–83 (2005)
12. Kingma, D.P., Ba, J .: Adam: метод стохастической оптимизации. Препринт arXiv arXiv: 1412.6980 (2014)13. Котари, Г., Неги, С., Фаруки, Т.А., Чакараварти, В.Т., Субраманиам, Л.В .: Интерфейс на основе SMS для поиска часто задаваемых вопросов. В ACL, стр. 852–860 (2009)
14. Лай, Й., Фунг, К., Ву, Ч .: Анализ вопросов и ответов с помощью обнаружения списков. В: Многоязычное обобщение и ответы на вопросы, стр. 1–7 (2002)
15. Лю, X., Хе, П., Чен, В., Гао, Дж .: Многозадачные глубокие нейронные сети для понимания естественного языка.Препринт arXiv arXiv: 1901.11504 (2019) 16. МакНемар К. Психологическая статистика. Нью-Йорк: Уайли; 1969. [Google Scholar] 17. Мирзаде, С., Фараджтабар, М., Ли, А., Гасемзаде, Х .: Улучшение извлечения знаний через помощника учителя: преодоление разрыва между учеником и учителем. Препринт arXiv arXiv: 1902.03393 (2019)18. Пеннингтон, Дж., Сочер, Р., Мэннинг, Ч .: Перчатка: глобальные векторы для представления слов. В: EMNLP, pp. 1532–1543 (2014)
19. Робертсон С., Сарагоса Х. и др. Структура вероятностной релевантности: BM25 и выше.FnTIR. 2009. 3 (4): 333–389. [Google Scholar]20. Schmonsees, R.J .: Динамическая система часто задаваемых вопросов (FAQ). Патент США 5,842,221, ноябрь 1998 г.
21. Снейдерс, Э .: Автоматические ответы на часто задаваемые вопросы: постоянный опыт работы с поверхностным пониманием языка. В кн .: Вопросно-ответные системы. Документы с осеннего симпозиума AAAI 1999 г., стр. 97–107 (1999)
22. Снейдерс, Э .: Автоматические ответы на часто задаваемые вопросы с помощью представления знаний по конкретным вопросам для веб-самообслуживания. В: Взаимодействие с человеческими системами, стр.298–305 (2009)
23. Сонг, В., Фэн, М., Гу, Н., Веньинь, Л .: Расчет подобия вопросов для ответов на часто задаваемые вопросы. В: Семантика, знания и сетка, стр. 298–301. IEEE (2007)
24. Васвани А. и др .: Внимание — это все, что вам нужно. В: NIPS, pp. 5998–6008 (2017)
25. Wang, A., et al.:. SuperGLUE: более надежный тест для систем понимания языков общего назначения. Препринт arXiv arXiv: 1905.00537 (2019)26. Ван, А., Сингх, А., Майкл, Дж., Хилл, Ф., Леви, О., Боуман, С.Р .: GLUE: многозадачная платформа для тестирования и анализа естественного языка. В: ICLR (2019)
27. Ван, З., Хамза, В., Флориан, Р.: Двустороннее сопоставление с несколькими перспективами для предложений на естественном языке. Препринт arXiv arXiv: 1702.03814 (2017) 28. Уайтхед С.Д. Auto-faq: эксперимент по использованию киберпространства. Comput. Netw. ISDN Syst. 1995. 28 (1–2): 137–146. DOI: 10.1016 / 0169-7552 (95) 00101-2. [CrossRef] [Google Scholar]29. Wu, W., Sun, X., Wang, H .: Сети уплотнения вопросов для выбора ответов при ответах на вопросы сообщества.В: ACL, стр. 1746–1755 (2018)
30. Ву Ю. и др.: Система нейронного машинного перевода Google: устранение разрыва между человеческим и машинным переводом. Препринт arXiv arXiv: 1609.08144 (2016)Механизм позиционного кодирования — Программист искал
Тепло скрыто в холоде снаружи и горячем внутри,
Но код, который выглядит холодным,
Его также можно объединить в самые романтичные и красивые любовные слова.
♥
Позиционное кодирование
Пока что в модели трансформатора отсутствует способ объяснить порядок слов во входной последовательности.Чтобы справиться с этой проблемой, преобразователь добавляет дополнительное векторное позиционное кодирование ко входу уровня кодера и уровня декодера. Размер такой же, как и размер вложения. Этот вектор использует очень уникальный метод, позволяющий модели узнать это значение. Этот вектор может определять позицию текущего слова или расстояние между разными словами в предложении. Для этого вектора положения существует множество конкретных методов расчета. Методика расчета в статье следующая
Среди них pos относится к позиции текущего слова в предложении, а i — это индекс каждого значения в указывающей величине.Видно, что в четных позициях используется синусоидальное кодирование, а в нечетных — косинусное кодирование. Наконец, значение этого позиционного кодирования и встраивания добавляется и отправляется на следующий уровень в качестве входных данных.
Чтобы модель фиксировала информацию о порядке слов, мы добавляем информацию вектора позиционного кодирования (ПОЗИЦИОННОЕ КОДИРОВАНИЕ). Вектор позиционного кодирования не требует обучения. Имеет метод регулярной генерации (формула выше).
Если размер встраивания равен 4, то фактическое кодирование позиции показано на рисунке ниже:
Итак, какие правила необходимо соблюдать для создания вектора положения?
Обратите внимание на рисунок ниже, каждая строка представляет код позиции вектора.Итак, первая строка — это вектор встраивания первого слова в нашей входной последовательности, каждая строка содержит 512 значений, каждое значение находится между 1 и -1. Мы используем цвет для представления значения между 1, -1, чтобы его можно было отобразить удобным визуальным способом:
Это пример кодирования позиции столбца (512) для 20 слов (строк). Вы обнаружите, что его центральное положение разделено на две половины. Это потому, что значение левой половины генерируется синусоидальной функцией, а правая половина генерируется другой функцией (косинусом).Затем соедините их, чтобы сформировать каждый вектор кода позиции.
Нормализация слоев
В преобразователе после каждого подслоя (self-attetion, ffnn) будет подключен остаточный модуль, и будет выполняться нормализация уровня
Для дальнейшего изучения его внутреннего метода расчета, мы можем визуализировать вышеупомянутый слой как следующий рисунок:
Я считаю, что все очень ясно понимают остаточный модуль, поэтому я не буду здесь его объяснять, а в основном объясню нормализацию уровня.Существует много типов нормализации, но все они имеют общую цель — преобразовать входные данные в данные со средним значением 0 и дисперсией 1. Мы выполняем нормализацию перед отправкой данных в функцию активации, потому что мы этого не делаем. Я хочу, чтобы входные данные попадали в область насыщения функции активации.
Когда дело доходит до нормализации, вы обязательно должны упомянуть пакетную нормализацию. Основная идея BN: нормализовать каждый пакет данных на каждом уровне. Мы можем нормализовать входные данные, но после сетевого уровня наши данные больше не нормализуются.С развитием этой ситуации отклонение данных становится все больше и больше. Мое обратное распространение должно учитывать эти большие отклонения. Это заставляет нас использовать меньшую скорость обучения, чтобы предотвратить исчезновение или взрыв градиента.
Конкретный метод BN — нормализовать каждый небольшой пакет данных в направлении пакета. Как показано ниже:
Видно, что среднее значение правой половины выполняется по направлению данных batch_size, а формула расчета выглядит следующим образом:
Так что же такое нормализация слоев? Это также способ нормализации данных, но LN вычисляет среднее значение и дисперсию для каждой выборки, а не BN, который вычисляет дисперсию и среднее значение в направлении партии.
Давайте посмотрим на формулу LN:
Пока это содержимое всех кодировщиков. Если два кодировщика накладываются друг на друга, это структура. Последний момент, на который следует обратить внимание при самовнимании, — это то, что он использует сокращенную структуру в остаточной сети для решения проблемы деградации глубины в обучении.
Уровень декодера
На приведенном выше рисунке представлена подробная структура трансформатора, которая более подробна, чем структурная схема в начале и конце этой статьи.Далее мы объясним часть декодера в соответствии с этой структурной схемой.
Вы можете видеть, что часть декодера на самом деле такая же, как и часть кодировщика, но есть дополнительное замаскированное обозначение мутильной головы внизу. Маска здесь также является ключевой технологией трансформатора. Давайте взглянем.
Маска
Маскапредставляет собой маску, которая маскирует определенные значения, поэтому она не действует при обновлении параметров. В модели Transformer используются два типа масок, а именно маска заполнения и маска последовательности.
Среди них маска заполнения используется во всем масштабируемом скалярном произведении внимания, а маска последовательности используется только в собственном внимании декодера.
Маска с подкладкой
Что такое маска заполнения? Поскольку длина каждого пакета входной последовательности различна, то есть нам необходимо выровнять входную последовательность. В частности, он должен заполнить 0 после более короткой последовательности. Но если входная последовательность слишком длинная, содержимое слева перехватывается, а лишнее сразу отбрасывается.Поскольку эти заполненные позиции на самом деле бессмысленны, наш механизм внимания не должен фокусироваться на этих позициях, поэтому нам нужно провести некоторую обработку.
Конкретный метод состоит в том, чтобы добавить очень большое отрицательное число (отрицательную бесконечность) к значению этих позиций. В этом случае вероятность прохождения softmax этих позиций будет близка к 0!
И наша маска заполнения на самом деле является тензором, каждое значение является логическим, значение false — это то место, где мы хотим обработать.
Маска последовательности
Как упоминалось ранее в статье, маска последовательности должна сделать декодер неспособным видеть будущую информацию. То есть для последовательности в момент time_step равно t, наш декодированный вывод должен зависеть только от вывода до момента t, а не от вывода после t. Следовательно, нам нужно найти способ скрыть информацию после t.
Так как ты это делаешь? Это также очень просто: сгенерируйте верхнюю треугольную матрицу, все значения верхнего треугольника равны 0.Примените эту матрицу к каждой последовательности для достижения нашей цели.
Для самовнимания декодера используемое в нем внимание масштабированного скалярного произведения также требует маски заполнения и маски последовательности как attn_mask. Конкретная реализация заключается в добавлении двух масок как attn_mask. В других случаях attn_mask совпадает с маской заполнения. Кодировщик запускается обработкой входной последовательности. Затем преобразуйте выходные данные верхнего кодировщика в набор векторов внимания k и v. Каждый декодер будет использовать эти векторы внимания в своем слое «внимание кодера-декодера», что помогает декодеру сосредоточить свое внимание на соответствующей позиции на входе. последовательность.
После завершения фазы кодирования мы начинаем фазу декодирования. Каждый шаг фазы декодирования выводит элемент из выходной последовательности (в данном случае предложение перевода на английский язык).
Следующие шаги повторяют этот процесс до тех пор, пока не будет достигнут символ, указывающий, что декодер завершил вывод. Выходные данные каждого шага отправляются нижнему декодеру на следующем временном шаге. Декодер похож на то, что мы делаем со входом кодировщика. Мы встраиваем и добавляем код позиции к этим входам декодера, чтобы представить значение каждого слова.позиция.
Выходной слой
Когда весь слой декодера выполнен, как сопоставить полученный вектор с нужными нам словами? Это очень просто, просто добавьте полностью связанный слой и слой softmax в конце.