


ТРАНСФОРМАТОРЫ. РАСШИФРОВКА НАИМЕНОВАНИЙ
Наименование (а точнее, номенклатура) трансформатора, говорит о его конструктивных особенностях и параметрах. При умении читать наименование оборудования можно только по нему узнать количество обмоток и фаз силового трансформатора, тип охлаждения, номинальную мощность и напряжение высшей обмотки.
ОБЩИЕ РЕКОМЕНДАЦИИНоменклатура трансформаторов (расшифровка буквенных и цифровых обозначений наименования) не регламентируется какими-либо нормативными документами, а всецело определяется производителем оборудования. Поэтому, если название Вашего трансформатора не поддаётся расшифровке, то обратитесь к его производителю или посмотрите паспорт изделия. Приведенные ниже расшифровки букв и цифр названия трансформаторов актуальны для отечественных изделий.
Наименование трансформатора состоит из букв и цифр, каждая из которых имеет своё значение. При расшифровке наименования следует учитывать то что некоторые из них могут отсутствовать в нём вообще (например буква «А» в наименовании обычного трансформатора), а другие являются взаимоисключающими (например, буквы «О» и «Т»).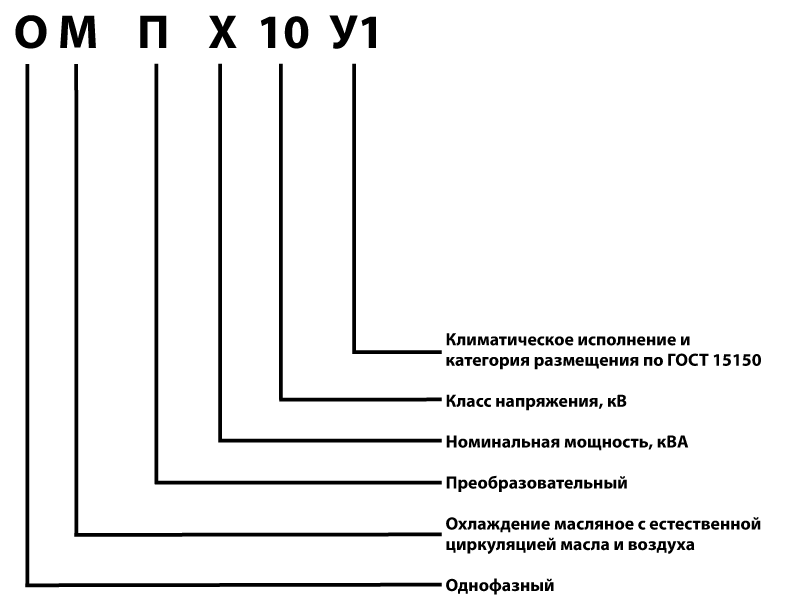
Для силовых трансформаторов приняты следующие буквенные обозначения:
Таблица 1 — Расшифровка буквенных и цифровых обозначений наименования силового трансформатора
Примечание: принудительная циркуляция воздуха называется дутьем, то есть «с принудительной циркуляцией воздуха» и «с дутьем» равнозначные выражения.
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ СИЛОВЫХ ТРАНСФОРМАТОРОВ
ТМ — 100/35 — трансформатор трёхфазный масляный с естественной циркуляцией воздуха и масла, номинальной мощностью 0,1 МВА, классом напряжения 35 кВ;
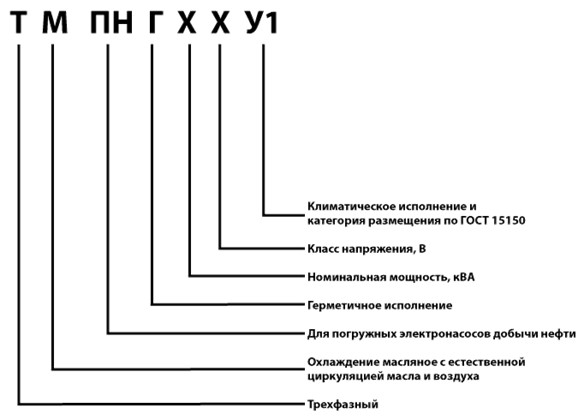
ТДНС — 10000/35 — трансформатор трёхфазный с дутьем масла, регулируемый под нагрузкой для собственных нужд электростанции, номинальной мощностью 10 МВА, классом напряжения 35 кВ;
ТРДНФ — 25000/110 — трансформатор трёхфазный, с расщеплённой обмоткой, масляный с принудительной циркуляцией воздуха, регулируемый под нагрузкой, с расширителем, номинальной мощностью 25 МВА, классом напряжения 110 кВ;
АТДЦТН — 63000/220/110 — автотрансформатор трёхфазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 63 МВА, класс ВН — 220 кВ, класс СН — 110 кВ;
АОДЦТН — 333000/750/330 — автотрансформатор однофазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 333 МВА, класс ВН — 750 кВ, класс СН — 500 кВ.
Для регулировочных трансформаторов приняты следующие сокращения:
Таблица 2 — Расшифровка буквенных и цифровых обозначений наименования регулировочного трансформатора
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ РЕГУЛИРОВОЧНЫХ ТРАНСФОРМАТОРОВ
ВРТДНУ — 180000/35/35 — трансформатор вольтодобавочный, регулировочный, трёхфазный, с масляным охлаждением типа Д, регулируемый под нагрузкой, с усиленным вводом, проходной мощностью 180 МВА, номинальное напряжение обмотки возбуждения 35 кВ, номинальное напряжения регулировочной обмотки 35 кВ;
ЛТМН — 160000/10 — трансформатор линейный, трёхфазный, с естественной циркуляцией масла и воздуха, регулируемый под нагрузкой, проходной мощностью 160 МВА, номинальным линейным напряжением 10 кВ.
РАСШИФРОВКА НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ НАПРЯЖЕНИЯ
Для трансформаторов напряжения приняты следующие сокращения:
Таблица 3 — Расшифровка буквенных и цифровых обозначений наименования трансформатора напряжения
Примечание:
Комплектующий для серии НОСК;
С компенсационной обмоткой для серии НТМК;
Кроме серии НОЛ и ЗНОЛ, в которых:
— 06 — для встраивания в закрытые токопроводы, ЗРУ и КРУ внутренней установки;
— 08 — для ЗРУ и КРУ внутренней и наружной установки;
— 11 — для взрывоопасных КРУ..JPG.b9ec7012306a44884bbc6e05c059b894.JPG)
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ НАПРЯЖЕНИЯ
НОСК-3-У5 — трансформатор напряжения однофазный с сухой изоляцией, комплектующий, номинальное напряжение обмотки ВН 3 кВ, климатическое исполнение — У5;
НОМ-15-77У1 — трансформатор напряжения однофазный с масляной изоляцией, номинальное напряжение обмотки ВН 15 кВ, 1977 года разработки, климатическое исполнение — У1;
ЗНОМ-15-63У2 — трансформатор напряжения с заземляемым концом обмотки ВН, однофазный с масляной изоляцией, номинальное напряжение обмотки ВН 15 кВ, 1963 года разработки, климатическое исполнение — У2;
ЗНОЛ-06-6У3 — трансформатор напряжения с заземляемым концом обмотки ВН, однофазный с литой эпоксидной изоляцией, для встраивания в закрытые токопроводы, ЗРУ и КРУ внутренней установки, климатическое исполнение — У3;
НТС-05-УХЛ4 — трансформатор напряжения трёхфазный с сухой изоляцией, номинальное напряжение обмотки ВН 0,5 кВ, климатическое исполнение — УХЛ4;
НТМК-10-71У3 — трансформатор напряжения трёхфазный с масляной изоляцией и компенсационной обмоткой, номинальное напряжение обмотки ВН 10 кВ, 1971 года разработки, климатическое исполнение — У3;
НТМИ-10-66У3 — трансформатор напряжения трёхфазный с масляной изоляцией и обмоткой для контроля изоляции сети, номинальное напряжение обмотки ВН 10 кВ, 1966 года разработки, климатическое исполнение — У3;
НКФ-110-58У1 — трансформатор напряжения каскадный в фарфоровой покрышке, номинальное напряжение обмотки ВН 110 кВ, 1958 года разработки, климатическое исполнение — У1;
НДЕ-500-72У1 — трансформатор напряжения с ёмкостным делителем, номинальное напряжение обмотки ВН 500 кВ, 1972 года разработки, климатическое исполнение — У1;
РАСШИФРОВКА НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ ТОКА
Для трансформаторов тока приняты следующие сокращения:
Таблица 4 — Расшифровка буквенных и цифровых обозначений наименования трансформатора тока
Примечание:
Для серии ТВ, ТВТ, ТВС, ТВУ;
Для серии ТНП, ТНПШ — с подмагничиванием переменным током;
Для серии ТШВ, ТВГ;
Для ТВВГ — 24 — водяное охлаждение;
Для серии ТНП, ТНПШ;
Для серии ТВ, ТВТ, ТВС, ТВУ — номинальное напряжения оборудования;
Для серии ТНП, ТНПШ — число обхватываемых жил кабеля;
Для серии ТНП, ТНПШ — номинальное напряжение.
ПРИМЕРЫ РАСШИФРОВКИ НАИМЕНОВАНИЙ ТРАНСФОРМАТОРОВ ТОКА
ТФЗМ — 35А — У1 — трансформатор тока в фарфоровой покрышке, с обмоткой звеньевого исполнения, с масляной изоляцией, номинальным напряжением обмотки ВН 35 кВ, категории А, климатическим исполнением У1;
ТФРМ — 750М — У1 — трансформатор тока в фарфоровой покрышке, с обмоткой рымочного исполнения, с масляной изоляцией, номинальным напряжением обмотки ВН 750 кВ, климатическим исполнением У1;
ТШЛ — 10К — трансформатор тока шинный с литой изоляцией, номинальное напряжением обмотки ВН 10 кВ;
ТЛП — 10К — У3 — трансформатор тока с литой изоляцией, проходной, номинальным напряжением обмотки ВН 10 кВ, климатическое исполнение — У3;
ТПОЛ — 10 — трансформатор тока проходной, одновитковый, с литой изоляцией, номинальным напряжением обмотки ВН 10 кВ;
ТШВ — 15 — трансформатор тока шинный, с воздушным охлаждением, номинальным напряжением обмотки ВН 15 кВ;
ТВГ — 20 — I
ТШЛО — 20 — трансформатор тока шинный, с литой изоляцией, одновитковый, номинальным напряжением обмотки ВН 20 кВ;
ТВ — 35 — 40У2 — трансформатор тока встроенный, номинальным напряжением обмотки ВН 35 кВ, током термической стойкости 40 кА, климатическое исполнение — У2;
ТНП — 12 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, охватывающий 12 жил кабеля;
ТНПШ — 2 — 15 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, шинный, охватывающий 2 жилы кабеля, номинальным напряжением обмотки ВН 15 кВ.
Расшифровка и маркировка обозначений трансформаторов (аббревиатур)
Маркировка трансформаторов
Любой трансформатор отличается различными конструктивными особенностями, областью применения, номинальным напряжением и климатическими условиями и т.п. Нужно уметь правильно расшифровать маркировку буквенно — цифровые обозначения характеристик трансформаторов: его мощность, систему охлаждения, количество обмоток, напряжение на обмотках высшего напряжения и низшего напряжения.
В настоящее время чтобы точно определить номенклатуру трансформатора нужно не только смотреть на название трансформатора, нормативные документы, но сверятся с документацией завода производителя трансформатора. Ниже даны расшифровки трансформаторов отечественного производства.
Любая цифра или буква на табличке набитой на корпусе трансформатора имеет свое значение. Некоторые буквы могут отсутствовать, другие не могут быть одновременно, например «О» и «Т» однофазный и трехфазный.![]()
Самые частые обозначения трансформаторов буквенные: ТМ, ТС, ТСЗ, ТД, ТДЦ, ТМН, ТДН, ТЦ, ТДГ, ТДЦГ, ОЦ, ОДГ, ОДЦГ, АТДЦТНГ, АОТДЦН и т. д
- А – обозначает автотрансформатор
- Первая буква отмечает фазировку: Т — трехфазный, О – однофазный;
- Буква Р (с расщепленной обмоткой) после числа фаз в обозначении указывает, что обмотка низшего напряжения представлена двумя (тремя) обмотками.
- Вторая буква указывает на систему охлаждения: М — естественное масляное, т. е. естественная циркуляция масла, С — сухой трансформатор с естественным воздушным охлаждением открытого исполнения, Д — масляное с дутьем, т. е. с обдуванием бака при помощи вентилятора, Ц — принудительная циркуляция масла через водяной охладитель, ДЦ — принудительная циркуляция масла с дутьем.
- Наличие второй буквы Т означает, что трансформатор трехобмоточный, двухобмоточный специального обозначения не имеет.
- Н — регулирование напряжения под нагрузкой (РПН), отсутствие — наличие переключения без возбуждения (ПБВ),
- Г — грозоупорный.

- За буквенными обозначениями следуют (Uн) номинальная мощность трансформатора (кВА)
- через дробь — класс номинального напряжения обмотки ВН (кВ). В автотрансформаторах добавляют в виде дроби класс напряжения обмотки СН. Иногда указывают год начала выпуска трансформаторов данной конструкции.
Шкала номинальных мощностей трехфазных силовых трансформаторов и автотрансформаторов (действующие государственные стандарты 1967 — 1974 гг.) высоковольтных сетей выстроена так, чтобы были значения мощности, кратные десяти: 20, 25, 40, 63, 100, 160, 250, 400, 630, 1000, 1600 кВА и т. д. Отдельные исключение составляют мощности 32000, 80000, 125000, 200000, 500000 кВА
Срок службы трансформаторов довольно длительные и равен 50 лет. В наше время можно встретить трансформаторы промышленных производств изготовленные еще 1968г, прошедшие капитальный ремонт.
Шкала мощностей трансформаторов выпущенных в СССР: 5, 10, 20, 30, 50, 100, 180, 320, 560, 750, 1000, 1800, 3200, 5600, …, 31500, 40500, кВА и т. д.
д.
Чтобы не запутаться в табличке указанных данных, можно разбить ее шесть групп.
Пример определения показателей для трансформатора АОДЦТН — 333000/750/330
автотрансформатор однофазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 333 МВА, класс ВН — 750 кВ, класс СН — 500 кВ
Расшифровка трансформаторов, примеры
Трансформаторы тока обозначаются следующим образом:
• Т — Буква указывает, что это именно трансформатор тока
• Вторая буква означает конструктивное исполнение: «П» — проходной, «О» – опорный трансформатор, «Ш» -шинный, «Ф» — с фарфоровой покрышкой
• Третье обозначение указывает на изоляцию и систему охлаждения обмоток трансформатора «Л» — литая изоляция, «М» — масляная,
Потом идет через “-“ класс изоляции, климатическое исполнение трансформаторов, и, категория установок.
Пример расшифровки трансформатора тока ТПЛ — 10УХЛ4 100/5А.
- Т – тока
- П – проходной
- Л – литая изоляция
- Класс 10 кВ
- УХ – умеренного и холодного климата
- 4 – четвертая категория
- 100/5А – коэффициент трансформации как сто к пяти.

Примеры расшифровка трансформаторов напряжения:
ТМ — 100/35 — трансформатор трёхфазный масляный с естественной циркуляцией воздуха и масла, номинальной мощностью 0,1 МВА, классом напряжения 35 кВ;
ТДНС — 10000/35 — трансформатор трёхфазный с дутьем масла, регулируемый под нагрузкой для собственных нужд электростанции, номинальной мощностью 10 МВА, классом напряжения 35 кВ;
ВРТДНУ — 180000/35/35 — трансформатор вольтодобавочный, регулировочный, трёхфазный, с масляным охлаждением типа Д, регулируемый под нагрузкой, с усиленным вводом, проходной мощностью 180 МВА, номинальное напряжение обмотки возбуждения 35 кВ, номинальное напряжения регулировочной обмотки 35 кВ;
ЛТМН — 160000/10 — трансформатор линейный, трёхфазный, с естественной циркуляцией масла и воздуха, регулируемый под нагрузкой, проходной мощностью 160 МВА, номинальным линейным напряжением 10 кВ.
НКФ-110-58У1 — трансформатор напряжения каскадный в фарфоровой покрышке, номинальное напряжение обмотки ВН 110 кВ, 1958 года разработки, климатическое исполнение — У1;
НДЕ-500-72У1 — трансформатор напряжения с ёмкостным делителем, номинальное напряжение обмотки ВН 500 кВ, 1972 года разработки, климатическое исполнение — У1;
ТНП — 12 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, охватывающий 12 жил кабеля;
ТНПШ — 2 — 15 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, шинный, охватывающий 2 жилы кабеля, номинальным напряжением обмотки ВН 15 кВ.
Видео: Классификация трансформаторов
Поделиться ссылкой:
Расшифровка трансформаторов: тока, напряжения и силовых
Чтобы понимать, для каких условий эксплуатации предназначен тот или иной трансформатор тока или напряжения, а также прочие разновидности, применяется особая маркировка приборов. Отечественные и импортные агрегаты имеют различное обозначение. В нашей стране чаще применяются установки, изготовленные по ГОСТу.
Маркировка трансформаторов наносится на щиток из металла на корпусе. Самые распространённые виды условных обозначений трансформаторов будут рассмотрены далее.
Информация на корпусе
Информация, представленная на видимой стороне устройства, наносится при помощи гравировки, травления или теснения. Это обеспечивает чёткость и долговечность надписи. На металлическом щитке указываются данные о заводе-изготовителе оборудования. Наносится год его выпуска, заводской номер.
Наносится год его выпуска, заводской номер.
Помимо данных о производителе обязательно присутствует информация об агрегате. Указывается номер стандарта, которому соответствует представленная конструкция. Обязательно наносится показатель номинальной мощности. Для трехфазных устройств этот параметр приводится для каждой обмотки отдельно. Указывается информация о напряжении ответвлений витков катушек.
Для всех обмоток определяется показатель номинального тока. Приводится количество фаз установки, частота тока. Производитель предоставляет данные о конфигурации и группах соединения катушек.
После приведённой выше информации можно ознакомиться с параметрами напряжения короткого замыкания. Представляются требования к установке. Она может быть наружной или внутренней.
Технические характеристики позволяют определить способ охлаждения, массу масла в баке (если применяется эта система), а также массу активной части. На приводе переключателя указывается его положение. Если установка обладает сухим видом охлаждения, есть данные о мощности установки при отключённом вентиляторе.
Если установка обладает сухим видом охлаждения, есть данные о мощности установки при отключённом вентиляторе.
Под щитком должен быть выбит заводской номер. Он присутствует на баке. Номер указывается на крышке возле ввода ВН, а также сверху и слева на полке балки сердечника.
Схема
Все приведённые на табличке данные можно разбить на 6 групп. Чтобы не запутаться в информации, следует рассмотреть последовательность её написания. Например, установка АТДЦТН-125000/220/110/10-У 1. Для маркировки особенностей прибора применяются следующие группы:
- I группа. А — Предназначена для указания типа прибора (силовой или автотрансформатор).
- II группа. Т — Соответствует типу сети, для которой применяется прибор (однофазная, трехфазная).
- III группа. ДЦ – Система охлаждения с принудительной циркуляцией масла и воздуха.
- IV группа. Т – Показывает количество обмоток (трехобмоточный).
- V группа. Н – Напряжение регулируется под нагрузкой.
- VI группа. Все цифры (номинальная мощность, напряжение ВН СН обмоток, климатическое исполнение, категория размещения).
 Все цифры (номинальная мощность, напряжение ВН СН обмоток, климатическое исполнение, категория размещения).
Все цифры (номинальная мощность, напряжение ВН СН обмоток, климатическое исполнение, категория размещения).О каждой категории следует узнать подробнее. Это значительно облегчит выбор.
Разновидности
Обозначение трансформаторов обязательно начинается с разновидности оборудования. Если маркировка начинается с буквы А, это автотрансформатор. Её отсутствие говорит о том, что агрегат относится к классу силовых трансформаторов.
Обязательно приводится число фаз. Это позволяет выбрать установку, работающую от бытовой или промышленной сети. Если трансформатор подключается к трехфазной сети, в маркировке будет присутствовать Т. Однофазные же разновидности имеют букву О. Они применяются в бытовых сетях.
Если устройство обладает расщеплённой обмоткой, он будет иметь Р. Если присутствует регулировка напряжения под нагрузкой (РПН) устройство будет иметь маркировку Н на металлическом щитке. При её отсутствии можно сделать вывод об отсутствии представленной особенности в аппарате.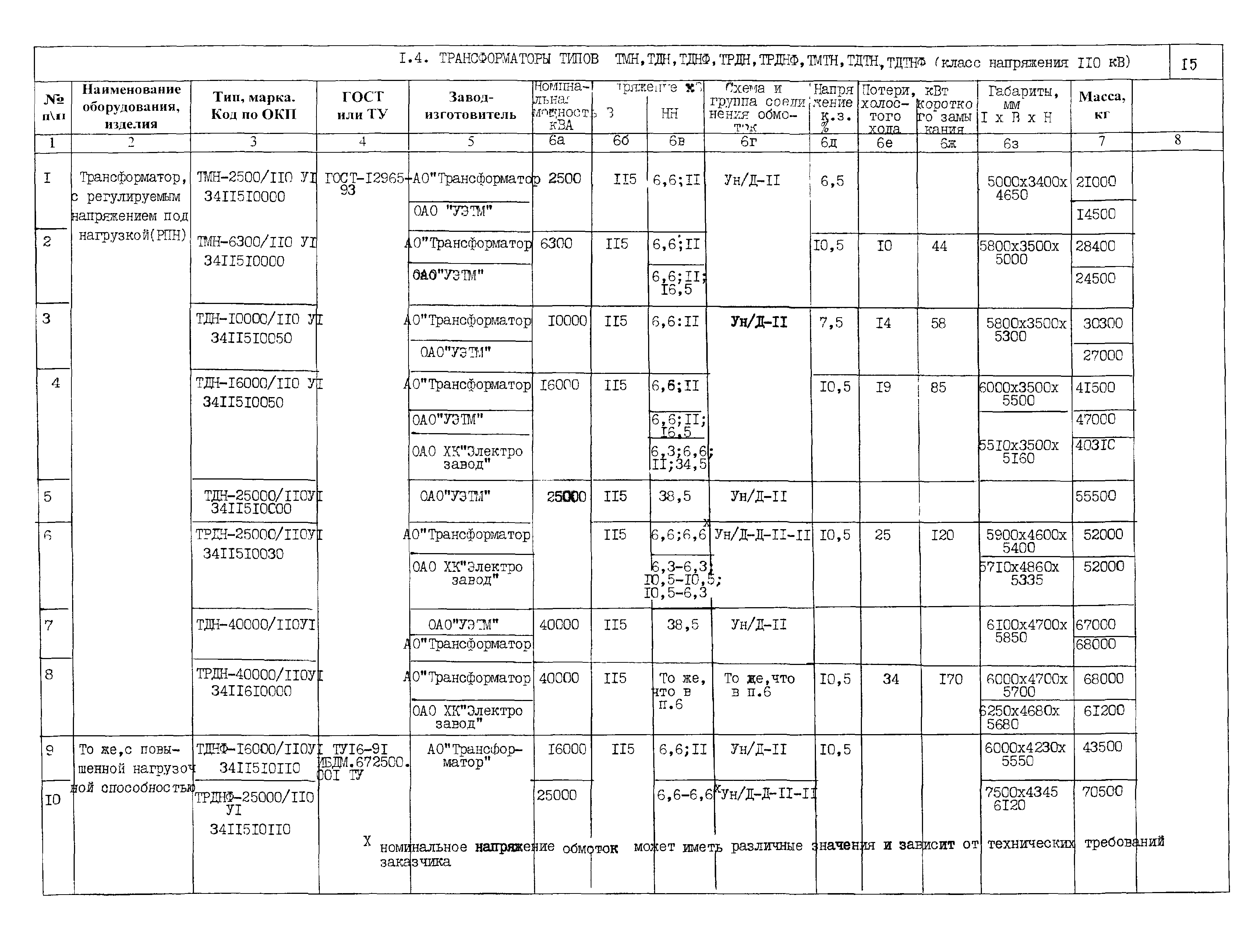
Особые обозначения
В зависимости от категории установки могут применяться особые обозначения. Для трансформатора тока и напряжения они могут не совпадать. Вторая разновидность техники применяется при работе защитных механизмов или для измерения тока. Первая категория приборов предназначается для изменения значения переменного тока.
Трансформаторы напряжения не используют для передачи электричества большой мощности. Они способны создавать развязку от низковольтных коммуникаций. В цепях с напряжением 12В и менее применяется эта категория приборов. Основным их рабочим параметром выступает ток и напряжение первичной обмотки. Именно их величину предоставляет производитель.
Маркировка трансформаторов напряжения начинается с их конструкции. Если это проходная конструкция, она обозначается литерой П. Если её нет, это опорный вид аппаратов. Литой изолятор имеет в маркировке Л, а фарфоровый – Ф. Встроенный изолятор имеет В.
Расшифровка современных трансформаторов тока выполняется в установленной последовательности.![]() Она начинается с Т, которая характеризует представленные приборы. Способ установки может быть проходным (П), опорным (О) или шинным (Ш). Если этот прибор присутствует в аппаратуре силовых трансформаторов, он обозначается как ВТ. Если же он встроен в масляный выключатель, то маркировка будет иметь букву В. При наружной установке прибор будет иметь Н.
Она начинается с Т, которая характеризует представленные приборы. Способ установки может быть проходным (П), опорным (О) или шинным (Ш). Если этот прибор присутствует в аппаратуре силовых трансформаторов, он обозначается как ВТ. Если же он встроен в масляный выключатель, то маркировка будет иметь букву В. При наружной установке прибор будет иметь Н.
Охладительная система
Условное обозначение трансформатора продолжается способом охлаждения. Сегодня существуют сухие, масляные разновидности. Также охладительная установка может иметь в своём составе негорючий текучий диэлектрик.
Масляные разновидности включают в себя около десятка различных конструкций оборудования. Если циркуляция жидкости внутри производится естественным путём, прибор имеет на щитке М. Если же она принудительная, здесь будет присутствовать обозначение Д. Оно соответствует также и сухим разновидностям приборов с представленным устройством внутренней циркуляции.
Если установлено оборудование с естественным движением масла и принудительным течением воды, оно маркируется сочетанием МВ. Для приборов с принудительной циркуляцией ненаправленного потока масла и естественным перемещением воздуха используется комбинация МЦ. Если же в таком устройстве направление масла чётко обозначено, маркировка будет НМЦ.
Для приборов с принудительной циркуляцией ненаправленного потока масла и естественным перемещением воздуха используется комбинация МЦ. Если же в таком устройстве направление масла чётко обозначено, маркировка будет НМЦ.
Для систем с принудительным ненаправленным движением масла и воздуха применяется обозначение ДЦ, а для направленного перемещения – НДЦ. Когда масло движется в пространстве между трубами и перегородками, по которым течёт вода, такой агрегат имеет на щитке букву Ц. Если же масло течёт по направленному вектору, прибор маркируется НЦ.
Охладительная система с жидким диэлектриком
Сегодня в «эксплуатацию» вводят новые разновидности устройств с различными улучшенными охладительными системами. Одной из них являются экземпляры техники с негорючим диэлектриком жидкого типа. Если охлаждение происходит посредством естественной циркуляции, представленная установка обозначается буквой Н. Если же присутствует принудительное движение воздуха, маркировка будет НД.
На табличке агрегатов с направленным потоком жидкого диэлектрика и принудительной циркуляцией воздуха указывается ННД. Это позволяет подобрать правильно тип аппаратуры.
Это позволяет подобрать правильно тип аппаратуры.
Сухие системы
Одной из новых разновидностей являются системы сухого охлаждения. Они просты в эксплуатации и обслуживании, не требовательны и не капризны. Если исполнение установки открытое, а циркуляция воздуха происходит естественным способом, его маркируют как С.
Защищённое исполнение обозначается буквами СЗ. Корпус может быть закрыт от воздействия различных факторов окружающей среды, он называется герметичным. При естественной циркуляции воздуха в нём, маркировка имеет буквы СГ.
В воздушных охладительных системах может присутствовать принудительная циркуляция. В этом случае устройство обозначается буквами СД.
Исполнение
Установки могут отличаться между собой особенностями исполнения. Если в них присутствует принудительная циркуляция воды, это позволит понять присутствующая на корпусе буква В. При наличии защиты от грозы и поражения молнией, конструкция имеет маркировку Г.
Система может обладать естественной циркуляцией масла или негорючего диэлектрика. При этом в некоторых разновидностях используется защита с азотной подушкой. В ней нет расширителей, выводов во фланцах стенок бака. Обозначение имеет букву З.
При этом в некоторых разновидностях используется защита с азотной подушкой. В ней нет расширителей, выводов во фланцах стенок бака. Обозначение имеет букву З.
Литая изоляция обозначается как Л. Подвесное исполнение определяет буква П. Усовершенствованная категория аппаратов обозначается как У. Они могут иметь автоматические РПН.
Оборудование с выводами и расширителем, установленными на фланцах стенках бака, маркируется буквой Ф. Энергосберегающий аппарат имеет пониженные потери энергии на холостом ходу. Его обозначают буквой Э.
Назначение
После категории особенностей исполнения представляется информация о назначении и области применения оборудования. Маркировка с буквой Б говорит о способности конструкции прогревать грунт или бетон зимой. Такое же обозначение может иметь трансформатор, предназначенный для станков буровых.
При электрификации железной дороги нужны установки с особыми свойствами и характеристиками. Они маркируются буквой Ж. Устройства с обозначением М эксплуатируются на металлургических комбинатах.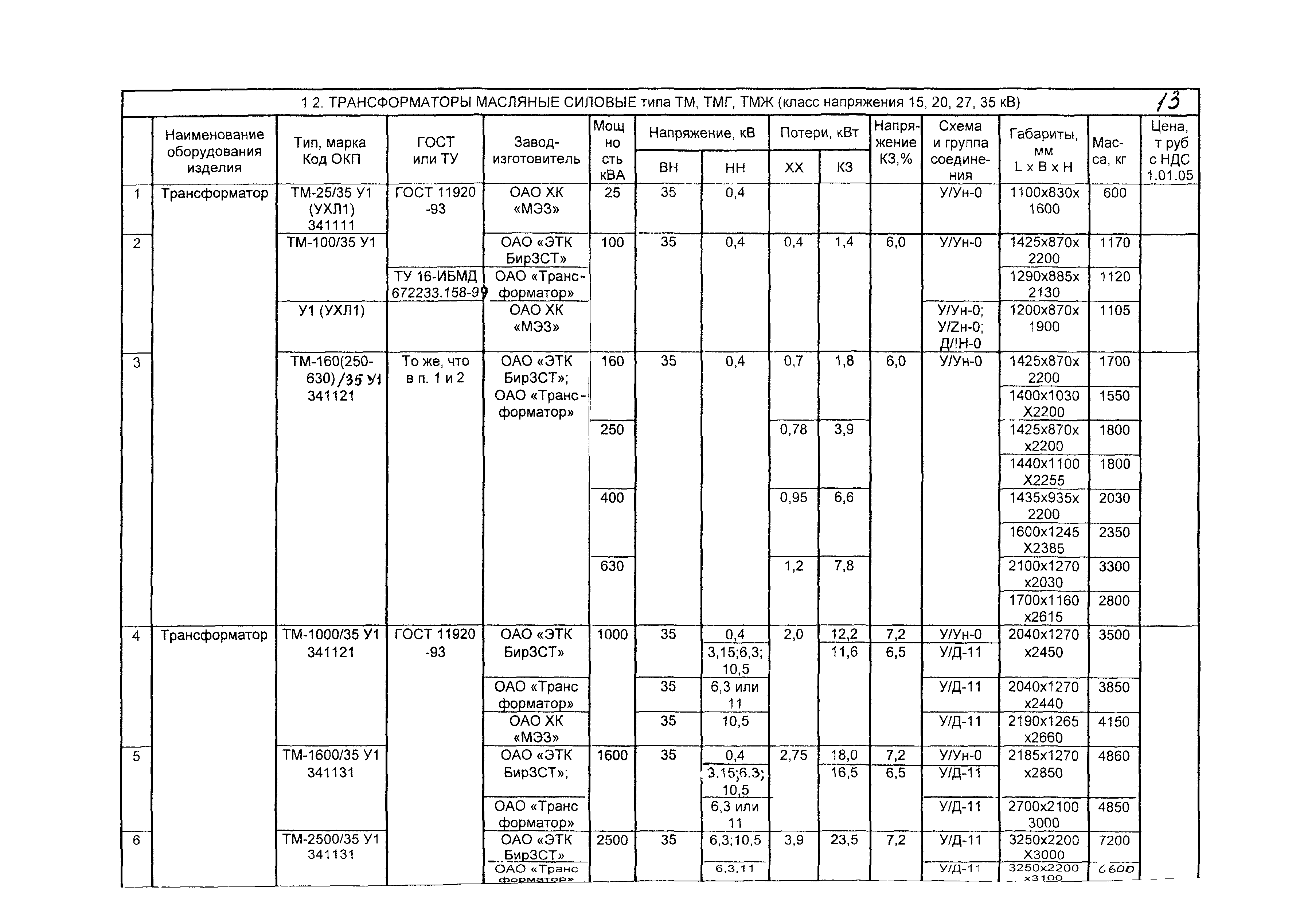
При передаче постоянного тока по линии нужны конструкции класса П. Агрегаты для обеспечения работы погружных насосов обозначаются как ПН.
Если агрегат применяется для собственных нужд электростанции, он относится к категории С. Тип ТО применяется для обработки грунта и бетона при высокой температуре, обеспечения электроэнергией временного освещения и ручного инструмента.
В угольных шахтах применяют трансформаторы разновидности Ш, а в системе питания электричеством экскаватора – Э.
Цифры
После перечисленных обозначений могут следовать числовые значения. Это номинальное напряжение обмотки в кВ, мощность в кВА. Для автотрансформаторов добавляется информация о напряжении обмотки СН.
В маркировке может присутствовать первый год выпуска представленной конструкции. Мощность агрегатов может составлять 20,40, 63, 160, 630, 1600 кВА и т. д. Этот показатель подбирают в соответствии с эксплуатационными условиями. Существует оборудование более высокой мощности. Этот параметр может достигать 200, 500 МВА.
Этот параметр может достигать 200, 500 МВА.
Продолжительность применения трансформаторов советского производства составляет порядка 50 лет. Поэтому в современных энергетических коммуникациях может применяться оборудование, выпущенное до 1968 г. Их периодически совершенствуют и реконструируют при капитальном ремонте.
Примеры
Чтобы понимать, как трактовать информацию на корпусе аппаратуры, следует рассмотреть несколько примеров маркировок. Это могут быть следующие трансформаторы:
- ТДТН-1600/110. Трехфазный класс техники понижающего типа. Он имеет масляное принудительное охлаждение, а также устройство РПН. Номинальная мощность равняется 1600, а напряжение ВН обмотки – 110 кВ.
- АТДЦТН-120000/500/110-85. Автотрансформатор, который применяется в трехфазной сети. Он имеет три обмотки. Масляная система охлаждения имеет принудительную циркуляцию. Есть устройство РПН. Номинальная мощность составляет 120 МВА. Устройство понижает напряжение и работает между сетями 500 и 110 кВ. Разработка 1985 года.
- ТМ-100/10 – двухобмоточный агрегат, который рассчитан для работы в трехфазной сети. Масляная система циркуляции имеет естественное перемещение жидкости. Изменение напряжения происходит при помощи ПБВ узла. Номинальная мощность составляет 100 кВА, а класс обмотки – 10 кВ.
- ТРДНС-25000/35-80. Аппарат для трехфазной сети с двумя расщеплёнными обмотками. Охлаждение производится посредством принудительной циркуляции масла. В конструкции есть регулятор РПН. Применяется для нужд электростанции. Мощность агрегата составляет 25 МВА. Класс напряжения обмотки – 35 кВ. Конструкция разработана в 1980 году.
- ОЦ-350000/500. Двухобмоточное устройство для однофазной сети повышающего класса. Применяется масляное охлаждение при помощи принудительного движения жидкости. Мощность 350 МВА, напряжение обмотки 500 кВ.
- ТСЗ-250/10-79. Экземпляр для трехфазной сети с сухим способом охлаждения. Корпус защищённый. Мощность составляет 250 кВА, а обмотки – 10 кВ. Устройство создано в 1979 г.
- ТДЦТГА-350000/500/110-60. Трехобмоточный прибор для трехфазной сети. Применяется для повышения напряжения. Трансформация происходит по принципу НН-СН и НН-ВН. Конструкция разработана в 1960 году.
 Разработка 1985 года.
Разработка 1985 года. Устройство создано в 1979 г.
Устройство создано в 1979 г.Видео: Классификация трансформаторов
Рассмотрев особенности маркировки различных видов трансформаторов, можно правильно применять их на объекте. Знание обозначений позволяет понимать функции, основные технические характеристики подобного оборудования. Маркировка, включающая в себя буквы и цифры, соответствует ГОСТам, применяемым в процессе изготовления специальной техники.
Трансформаторы — Буквенные обозначения трансформатора
БУКВЕННОЕ ОБОЗНАЧЕНИЕ СИЛОВОГО ТРАНСФОРМАТОРА
ОБЩЕГО И СПЕЦИАЛЬНОГО НАЗНАЧЕНИЯ
Схема буквенного обозначения типов трансформаторов:
Расшифровка буквенного обозначения силового трансформатора:
1 А – автотрансформатор (может отсутствовать)
2 Число фаз:
Т – трёхфазный
О – однофазный
3 Р – с расщеплённой обмоткой (может отсутствовать)
4 Условное обозначения вида охлаждения:
Масляные трансформаторы
М – естественная циркуляция воздуха и масла
Д — принудительная циркуляция воздуха и естественная циркуляция масла
МВ – с принудительной циркуляцией воды и естественной циркуляцией масла
МЦ — естественная циркуляция воздуха и принудительная циркуляция масла с ненаправленным потоком масла
НМЦ — Естественная циркуляция воздуха и принудительная циркуляция масла с направленным потоком масла
ДЦ – Принудительная циркуляция воздуха и масла с ненаправленным потоком масла
НДЦ — Принудительная циркуляция воздуха и масла с направленным потоком масла
Ц — Принудительная циркуляция воды и масла с ненаправленным потоком масла (в охладителях вода движется по трубам, а масло – в межтрубном пространстве, разделённом перегородками)
НЦ — Принудительная циркуляция воды и масла с направленным потоком масла
Трансформаторы с негорючим жидким диэлектриком
Н — Естественное охлаждение негорючим жидким диэлектриком
НД — Охлаждение негорючим жидким диэлектриком с принудительной циркуляцией воздуха
ННД — Охлаждение негорючим жидким диэлектриком с принудительной циркуляцией воздуха и с направленным потоком жидкого диэлектрика
Сухие трансформаторы
С — Естественное воздушное при открытом исполнении
СЗ — Естественное воздушное при защищенном исполнении
СГ — Естественное воздушное при герметичном исполнении
СД — Воздушное с принудительной циркуляцией воздуха
5 Т – трёхобмоточный трансформатор
6 Н – трансформатор с РПН (с регулированием напряжения под нагрузкой)
7 Особенность исполнения (в обозначении может отсутствовать):
В – с принудительной циркуляцией воды
Г – грозозащитное исполнение
Г – трансформатор в гофрированном баке без расширителя — «герметичное исполнение»
З – трансформатор с естественным масляным охлаждением или с охлаждением негорючим жидким диэлектриком с защитой при помощи азотной подушки, без расширителя и выводами,
смонтированными во фланцах на стенках бака
Л — исполнение трансформатора с литой изоляцией
П — подвесного исполнения на опоре ВЛ
У – усовершенствованное (может быть с автоматическим РПН)
У – трансформатор с симметрирующим устройством
Ф – трансформатор с расширителем и выводами, смонтированными во фланцах на стенках бака
э – трансформатор с пониженными потерями холостого хода (энергосберегающий)
8 Назначение (в обозначении может отсутствовать)
Б – для прогрева бетона или грунта в холодное время года (бетоногрейный), с такой же литерой может обозначаться трансформатор для буровых станков
Б – трансформатор для буровых станков
Ж – для электрификации железных дорог
М – для металлургического производства
П – для линий передачи постоянного тока
ПН – исполнение для питания погружных электронасосов
С – для собственных нужд электростанций (в конце буквенного обозначения)
ТО – для термической обработки бетона и грунта, питания ручного инструмента, временного освещения
Ш – шахтные трансформаторы (предназначены для электроснабжения угольных шахт стационарной установки)
Э – для питания электрооборудования экскаваторов (экскаваторный)
Примеры серий силовых трансформаторов общего назначения: TМ, ТМГ, ТМЭ, ТМЭГ, ТМБ, ТМПН, ТМВГ, ТМВЭГ, ТМВБГ, ТМЖ, ТМВЭ, ТМВБ, ТМЗ, ТМФ, ТМЭБ, ТМВМЗ, ТМС, ТСЗ, ТСЗС, ТРДНС, ТМН,
ТДНС, ТДН, ТМН, ТРДН, ТРДЦН
Примеры:
ТМ – Т – трансформатор трехфазный, М – с естественной циркуляцией воздуха и масла
ТМВГ – Т — трансформатор трехфазный, МВ — с естественной циркуляцией масла и принудительной циркуляцией воды, Г — в герметичном исполнении
ТНЗ – Т — трехфазный, Н — с регулированием под нагрузкой (РПН), З — с естественным масляным
ТМВМ – Т- трехфазный, МВ — с естественной циркуляцией масла и принудительной циркуляцией воды, М – для металлургического производства
ТМГ – Т — трехфазный, М — масляный, Г — в герметичном исполнении
ТМВГ – Т — трехфазный, МВ — с естественной циркуляцией масла и принудительной циркуляцией воды, Г — в герметичном исполнении
ТСЗ – Т — трехфазный, С — естественное воздушное охлаждение, З — в защищенном исполнении;
ТСЗС – Т — трехфазный, С — сухой, З — защищенное исполнение, С — для собственных нужд электростанций
Трехобмоточные: ТМТН, ТДТН, ТДЦТН
Т – стоящая после обозначения системы охлаждения обозначает – трехобмоточный.
Автотрансформаторы: АТДТНГ, АТДЦТНГ, АТДЦТН, АОДЦТН
А – автотрансформатор;
О – однофазный,
Г – грозоупорный.
ТМ 1000/10 74 У1 – Т- трехфазный двух обмоточный трансформатор, М – охлаждение естественная циркуляция воздуха и масла, номинальная мощность — 1000 кВА, класс высшего напряжения — 10 кВ, конструкция — 1974 г., У1 — для района с умеренным климатом, для установки на открытом воздухе;
ТРДНС 25000/35 74 Т1 трехфазный двух обмоточный трансформатор, с расщепленной обмоткой НН, с принудительной циркуляцией воздуха в системе охлаждения, с РПН, для собственных нужд электростанций, номинальная мощность 25 МВА, класс высшего напряжения 35 кВ, конструкция 1974 г., тропического исполнения, для установки на открытом воздухе;
ТЦ 1000000/500 83ХЛ1 трехфазный двух обмоточный трансформатор с принудительной циркуляцией масла и воды в системе охлаждения, номинальная мощность 1000 МВА, класс напряжения 500 кВ, конструкция 1983 г., для районов с холодным климатом, для наружной установки.
Для автотрансформаторов при классах напряжения стороны СН (среднее напряжение) или НН (низкое напряжение) 110 кВ и выше после класса напряжения стороны ВН (высокое напряжение) через черту дроби указывают класс напряжения стороны СН или НН.
Примечание. Для трансформаторов, разработанных до 01.07.87, допускается указывать последние две цифры — год выпуска рабочих чертежей.
Автотрансформаторы отличаются добавлением к обозначению трансформаторов буквы А, она может быть первой в буквенном обозначении или последней.
В автотрансформаторах, изготовленных по основному стандарту трансформаторов ГОСТ 1167765, ГОСТ 1167775, ГОСТ 1167785, буква А стоит впереди всех символов
Например: АОДЦТН 417000/750/500 73У1 однофазный трехобмоточный автотрансформатор номинальной (проходной) мощностью 417 МВА, класс напряжения ВН 750 кВ, СН 500 кВ, остальные символы расшифровываются так же, как и в предыдущих примерах.
В конце 50х годов, когда в СССР впервые появились мощные силовые автотрансформаторы 220/110, 400/220, 400/110, 500/220, 500110 кВ, и в начале 60х годов производили автотрансформаторы двух модификаций повышающей и понижающей. В обозначении повышающей модификации буква А стояла в конце буквенной части; в этих автотрансформаторах обмотку НН выполняли на повышенную мощность и располагали между обмотками СН и ВН, по точной терминологии между общей и последовательной обмотками.
Автотрансформаторы второй модификации понижающей, с буквой А впереди всех символов (как и в новых автотрансформаторах) служат для понижения напряжения, например, с 220 до 110 кВ, или для связи сетей ВН и СН. Обмотка НН в них, как и в новых автотрансформаторах, расположена у стержня, имеет пониженную мощность и несет вспомогательные функции.
Пример обозначения повышающей модификации:
ТДШТА 120000/220, понижающей АТДШТ 120000/220. (Буква Г обозначала грозоупорный, но отменена по мере внедрения ГОСТ 1167765, так как все трансформаторы и автотрансформаторы 110 кВ и выше имеют гарантированную стойкость при грозовых перенапряжениях). В эксплуатации до сих пор встречаются автотрансформаторы обеих модификаций.
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ТРАНСФОРМАТОРА (АВТОТРАНСФОРМАТОРА), УКАЗАННЫЕ НА ЗАВОДСКОМ ЩИТКЕ (ТАБЛИЧКЕ)
Щиток крепится к баку трансформатора, и указаны следующие параметры:
– тип трансформатора
– число фаз
– частота, Гц
– род установки (наружная или внутренняя)
– номинальная мощность, кВА, для трехобмоточных трансформаторов указывают мощность каждой обмотки
– схема и группа соединения обмоток
– напряжения на номинальной ступени и напряжения ответвлений обмоток, кВ
– номинальный ток, А
– напряжение короткого замыкания в процентах (фактически измеренное, для каждого изделия индивидуальное)
– способ охлаждения трансформатора
– полная масса трансформатора, масла и активной части трансформатора.
Трансформатор ТМН расшифровка
Конечно, у нас собстевенное производство, поэтому мы можем производить не стандартные транс р с боковым подключением вводов и выводов высокого и низкого напряжения. Вправо и влево — вверх и вниз, типа НН и ВН и дополнительными опциями! Сборка любых технических параметров первичной и вторичной обмотки
Да, мы сотрудничаем с официальными дилерами, представительство в России, список таких заводов:
Казахстан — Кентауский трансформаторный завод
Белоруссия Минск — Минский электротехнический завод им Козлова
Украина Богдано Хмельницчкий (Запорожский) — Укрэлектроаппарат
Алтайский Барнаул — Барнаульский Алттранс
Тольяттинский
Самарский — Самара ЗАО Электрощит СЭЩ
Санкт Петербург СПБ Невский — Волхов Великий Новгород
Подольский — ЗАО Трансформер
Чеховский Электрощит
Георгиевский ОАО ГТЗ
Компания кубань электрощит
Марки трансформаторов с естественной масляной системой охлаждения обмоток серии ТМ ТМГ ТМЗ ТМФ ТМГФ. Виды баков гофро (гофрированный) и с радиаторами (радиаторный) А так же доступны линейки сухих трансформаторов ТС ТСЗ ТСЛ ТСЛЗ
Производим повышающие и понажающие напряжение заземление тока, большие цеховые, производственные, промышленные и общепромышленные трансформаторы собственных нужд общего назначения внутренней встроенные в помещение ТП и наружной установки закрытого типа. Выбор наминалы мощности 25 40 63 100 160 250 400 630 1000 (1 мВа) 1250 (1 25 мВа) 1600 (1 6 мВа) 2500 4000 6300 кВа и напряжением 6 10 35 110 0.4 кВ кВт. Можем сделать испытание напряжением под заказ, например компоновка новые типовые проекты из аморфной стали или с глухозаземлённой нейтралью каскадные, разделительные, фланцевые с боковыми вводами выводами. Строительство соответствует нормам ПУЭ и ТУ сертификация систем охлаждения. С необходимыми параметрами и тех характеристиками габаритами размерами весом высотой шириной и доп описание из образеца технического задания справочные данные документация условия работы. Прайс каталог с ценами завода производителя. Производство в России! Фото состав (из чего состоит) и чертежи принципиальная однолинейная электрическая схема по запросу. Срок эксплуатации 25 лет
Поставляем в дачный посёлок коттеджные дачи коттеджи, садовые СНТ товарищества, сельские деревенские местности деревни
Трансформаторы. Расшифровка наименований. Примеры — Всё об энергетике
Трансформаторы. Расшифровка наименований. Примеры
Наименование (а точнее, номенклатура) трансформатора, говорит о его конструктивных особенностях и параметрах. При умении читать наименование оборудования можно только по нему узнать количество обмоток и фаз силового трансформатора, тип охлаждения, номинальную мощность и напряжение высшей обмотки.
Общие рекомендации
Номенклатура трансформаторов (расшифровка буквенных и цифровых обозначений наименования) не регламентируется какими-либо нормативными документами, а всецело определяется производителем оборудования. Поэтому, если название Вашего трансформатора не поддаётся расшифровке, то обратитесь к его производителю или посмотрите паспорт изделия. Приведенные ниже расшифровки букв и цифр названия трансформаторов актуальны для отечественных изделий.
Наименование трансформатора состоит из букв и цифр, каждая из которых имеет своё значение. При расшифровке наименования следует учитывать то что некоторые из них могут отсутствовать в нём вообще (например буква «А» в наименовании обычного трансформатора), а другие являются взаимоисключающими (например, буквы «О» и «Т»).
Расшифровка наименований силовых трансформаторов
Для силовых трансформаторов приняты следующие буквенные обозначения [1, c.238]:
| 1. Автотрансформатор | А |
| 2. Число фаз | |
| Однофазный | О |
| Трёхфазный | Т |
| 3. С расщепленной обмоткой | Р |
| 4. Охлаждение | |
| Сухие трансформаторы: | |
| естественное воздушное при открытом исполнении | С |
| естественное воздушное при защищенном исполнении | СЗ |
| естественное воздушное при герметичном исполнении | СГ |
| воздушное с принудительной циркуляцией воздуха | СД |
| Масляные трансформаторы: | |
| естественная циркуляция воздуха и масла | М |
| принудительная циркуляция воздуха и естественная циркуляция масла | Д |
| естественная циркуляция воздуха и принудительная циркуляция масла с ненаправленным потоком масла | МЦ |
| естественная циркуляция воздуха и принудительная циркуляция масла с направленным потоком масла | НМЦ |
| принудительная циркуляция воздуха и масла с ненаправленным потоком масла | ДЦ |
| принудительная циркуляция воздуха и масла с направленным потоком масла | НДЦ |
| принудительная циркуляция воды и масла с ненаправленным потоком масла | Ц |
| принудительная циркуляция воды и масла с направленным потоком масла | НЦ |
| 5. Трёхобмоточный | Т |
| 6. Переключение ответвлений | |
| регулирование под нагрузкой (РПН) | Н |
| автоматическое регулирование под нагрузкой (АРПН) | АН |
| 7. С литой изоляцией | Л |
| 8. Исполнение расширителя | |
| с расширителем | Ф |
| без расширителя, с защитой при помощи азотной подушки | З |
| без расширителя в гофробаке (герметичная упаковка) | Г |
| 9. С симметрирующим устройством | У |
| 10. Подвесного исполнения (на опоре ВЛ) | П |
| 11. Назначение | |
| для собственных нужд электростанций | С |
| для линий постоянного тока | П |
| для металлургического производства | М |
| для питания погружных электронасосов | ПН |
| для прогрева бетона или грунта (бетоногрейный), для буровых станков | Б |
| для питания электрооборудования экскаваторов | Э |
| для термической обработки бетона и грунта, питания ручного инструмента, временного освещения | ТО |
| шахтные трансформаторы | Ш |
| Номинальная мощность, кВА | [число] |
| Класс напряжения обмотки ВН, кВ | [число] |
| Класс напряжения обмотки СН (для авто- и трёхобмоточных тр-ов), кВ | [число] |
Примечание: принудительная циркуляция вохдуха называется дутьем, то есть «с принудительной циркуляцией воздуха» и «с дутьем» равнозначные выражения.
Примеры расшифровки наименований силовых трансформаторов
ТМ — 100/35 — трансформатор трёхфазный масляный с естественной циркуляцией воздуха и масла, номинальной мощностью 0,1 МВА, классом напряжения 35 кВ;
ТДНС — 10000/35 — трансформатор трёхфазный с дутьем масла, регулируемый под нагрузкой для собственных нужд электростанции, номинальной мощностью 10 МВА, классом напряжения 35 кВ;
ТРДНФ — 25000/110 — трансформатор трёхфазный, с расщеплённой обмоткой, масляный с принудительной циркуляцией воздуха, регулируемый под нагрузкой, с расширителем, номинальной мощностью 25 МВА, классом напряжения 110 кВ;
АТДЦТН — 63000/220/110 — автотрансформатор трёхфазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 63 МВА, класс ВН — 220 кВ, класс СН — 110 кВ;
АОДЦТН — 333000/750/330 — автотрансформатор однофазный, масляный с дутьём и принудительной циркуляцией масла, трёхобмоточный, регулируемый под нагрузкой, номинальной мощностью 333 МВА, класс ВН — 750 кВ, класс СН — 500 кВ.
Расшифровка наименований регулировочных (вольтодобавочных) трансформаторов
Для регулировочных трансформаторов приняты следующие сокращения [1, c.238][2, c.150]:
| 1. Вольтодобавочный трансформатор | В |
| 2. Регулировочный трансформатор | Р |
| 3. Линейный регулировочный | Л |
| 4. Трёхфазный | Т |
| 5. Тип охлаждения: | |
| принудительная циркуляция воздуха и естественная циркуляция масла | Д |
| естественная циркуляция воздуха и масла | М |
| 6. Регулирование под нагрузкой (РПН) | Н |
| 7. Поперечное регулирование | П |
| 8. Грозоупорное исполнение | Г |
| 9. С усиленным вводом | У |
| Проходная мощность, кВА | [число] |
| Класс напряжения обомотки возбуждения, кВ | [число] |
| Класс напряжения регулировочной обомотки, кВ | [число] |
Примеры расшифровки наименований регулировочных трансформаторов
ВРТДНУ — 180000/35/35 — трансформатор вольтодобавочный, регулировочный, трёхфазный, с масляным охлаждением типа Д, регулируемый под нагрузкой, с усиленным вводом, проходной мощностью 180 МВА, номинальное напряжение обмотки возбуждения 35 кВ, номинальное напряжения регулировочной обмотки 35 кВ;
ЛТМН — 160000/10 — трансформатор линейный, трёхфазный, с естественной циркуляцией масла и воздуха, регулируемый под нагрузкой, проходной мощностью 160 МВА, номинальным линейным напряжением 10 кВ.
Расшифровка наименований трансформаторов напряжения
Для трансформаторов напряжения приняты следующие сокращения [2, c.200]:
| 1. Конец обмотки ВН заземляется | З |
| 2. Трансформатор напряжения | Н |
| 3. Число фаз: | |
| Однофазный | О |
| Трёхфазный | Т |
| 4. Тип изоляции: | |
| Сухая | С |
| Масляная | М |
| Литая эпоксидная | Л |
| 5. Каскадный (для серии НКФ)(1,2) | К |
| 6. В фарфоровой покрышке | Ф |
| 7. С обмоткой для контроля изоляции сети | И |
| 8. С ёмкостным делителем (серия НДЕ) | ДЕ |
| Номинальное напряжение(3), кВ | [число] |
| Климатическое исполнение | [число] |
- Примечание:
- Комплектующий для серии НОСК;
- С компенсационной обмоткой для серии НТМК;
- Кроме серии НОЛ и ЗНОЛ, в которых:
- 06 — для встраивания в закрытые токопроводы, ЗРУ и КРУ внутренней установки;
- 08 — для ЗРУ и КРУ внутренней и наружной установки;
- 11 — для взрывоопасных КРУ.
Примеры расшифровки наименований трансформаторов напряжения
НОСК-3-У5 — трансформатор напряжения однофазный с сухой изоляцией, комплектующий, номинальное напряжение обмотки ВН 3 кВ, климатическое исполнение — У5;
НОМ-15-77У1 — трансформатор напряжения однофазный с масляной изоляцией, номинальное напряжение обмотки ВН 15 кВ, 1977 года разработки, климатическое исполнение — У1;
ЗНОМ-15-63У2 — трансформатор напряжения с заземляемым концом обмотки ВН, однофазный с масляной изоляцией, номинальное напряжение обмотки ВН 15 кВ, 1963 года разработки, климатическое исполнение — У2;
ЗНОЛ-06-6У3 — трансформатор напряжения с заземляемым концом обмотки ВН, однофазный с литой эпоксидной изоляцией, для встраивания в закрытые токопроводы, ЗРУ и КРУ внутренней установки, климатическое исполнение — У3;
НТС-05-УХЛ4 — трансформатор напряжения трёхфазный с сухой изоляцией, номинальное напряжение обмотки ВН 0,5 кВ, климатическое исполнение — УХЛ4;
НТМК-10-71У3 — трансформатор напряжения трёхфазный с масляной изоляцией и компенсационной обмоткой, номинальное напряжение обмотки ВН 10 кВ, 1971 года разработки, климатическое исполнение — У3;
НТМИ-10-66У3 — трансформатор напряжения трёхфазный с масляной изоляцией и обмоткой для контроля изоляции сети, номинальное напряжение обмотки ВН 10 кВ, 1966 года разработки, климатическое исполнение — У3;
НКФ-110-58У1 — трансформатор напряжения каскадный в фарфоровой покрышке, номинальное напряжение обмотки ВН 110 кВ, 1958 года разработки, климатическое исполнение — У1;
НДЕ-500-72У1 — трансформатор напряжения с ёмкостным делителем, номинальное напряжение обмотки ВН 500 кВ, 1972 года разработки, климатическое исполнение — У1;
Расшифровка наименований трансформаторов тока
Для трансформаторов тока приняты следующие сокращения [2, c.201,206-207,213]:
| 1. Трансформатор тока | Т |
| 2. В фарфоровой покрышке | Ф |
| 3. Тип: | |
| Встроенный(1) | В |
| Генераторный | Г |
| Нулевой последовательности | Н |
| Одновитковый | О |
| Проходной(2) | П |
| Усиленный | У |
| Шинный | Ш |
| 4. Исполнение обмотки: | |
| Звеньевого типа | З |
| U-образного типа | У |
| Рымочного типа | Р |
| 5. Исполнение изоляции: | |
| Литая | Л |
| Масляная | М |
| 6. Воздушное охлаждение(3,4) | В |
| 7. Защита от замыкания на землю отдельных жил кабеля(5) | З |
| 8. Категория исполнения | А,Б |
| Номинальное напряжение(6,7) | [число] |
| Ток термической стойкости(8) | [число] |
| Климатическое исполнение | [число] |
- Примечание:
- Для серии ТВ, ТВТ, ТВС, ТВУ;
- Для серии ТНП, ТНПШ — с подмагничиванием переменным током;
- Для серии ТШВ, ТВГ;
- Для ТВВГ — 24 — водяное охлаждение;
- Для серии ТНП, ТНПШ;
- Для серии ТВ, ТВТ, ТВС, ТВУ — номинальное напряжения оборудования;
- Для серии ТНП, ТНПШ — число обхватываемых жил кабеля;
- Для серии ТНП, ТНПШ — номинальное напряжение.
Примеры расшифровки наименований трансформаторов тока
ТФЗМ — 35А — У1 — трансформатор тока в фарфоровой покрышке, с обмоткой звеньевого исполнения, с масляной изоляцией, номинальным напряжением обмотки ВН 35 кВ, категории А, климатическим исполнением У1;
ТФРМ — 750М — У1 — трансформатор тока в фарфоровой покрышке, с обмоткой рымочного исполнения, с масляной изоляцией, номинальным напряжением обмотки ВН 750 кВ, климатическим исполнением У1;
ТШЛ — 10К — трансформатор тока шинный с литой изоляцией, номинальное напряжением обмотки ВН 10 кВ;
ТЛП — 10К — У3 — трансформатор тока с литой изоляцией, проходной, номинальным напряжением обмотки ВН 10 кВ, климатическое исполнение — У3;
ТПОЛ — 10 — трансформатор тока проходной, одновитковый, с литой изоляцией, номинальным напряжением обмотки ВН 10 кВ;
ТШВ — 15 — трансформатор тока шинный, с воздушным охлаждением, номинальным напряжением обмотки ВН 15 кВ;
ТВГ — 20 — I — трансформатор тока с воздушным охлаждением, генераторный, номинальным напряжением обмотки ВН 20 кВ;
ТШЛО — 20 — трансформатор тока шинный, с литой изоляцией, одновитковый, номинальным напряжением обмотки ВН 20 кВ;
ТВ — 35 — 40У2 — трансформатор тока встроенный, номинальным напряжением обмотки ВН 35 кВ, током термической стойкости 40 кА, климатическое исполнение — У2;
ТНП — 12 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, охватывающий 12 жил кабеля;
ТНПШ — 2 — 15 — трансформатор тока нулевой последовательности, с подмагничиванием переменным током, шинный, охватывающий 2 жилы кабеля, номинальным напряжением обмотки ВН 15 кВ.
Список использованных источников
- Справочник по проектированию электрических сетей / под ред. Д.Л. Файбисовича. — 3-е изд., перераб. и доп. — Москва: ЭНАС, 2009. — 392 с.: ил.
- Справочник по электрическим установкам высокого напряжения / под ред. И.А. Баумштейна, С.А. Баженова. — 3-е изд., перераб. и доп. — Москва: Энергоатомиздат, 1989. — 768 с.: ил.
Трансформатор ТМГ: расшифровка, конструкция, технические характеристики
Электроснабжение крупных предприятий и бытовых потребителей производится за счет трансформаторных и районных подстанций. Преобразование электрической энергии в сетях переменного тока осуществляется за счет силовых трансформаторов. Одним из них является трансформатор ТМГ, достаточно часто используемый в отечественных электроустановках.
Расшифровка
Конструкция любой электрической машины имеет свои особенности и назначение, что позволяет использовать их в тех или иных устройствах, климатических зонах или электрических схемах. Для определения особенностей любой модификации трансформатора, следует ознакомиться с его маркировкой и заводским обозначением. Поэтому далее рассмотрим расшифровку на конкретном примере:
ТМГ-250-10-0,4-Υ/ΥН — 0 — У1
- Т – трехфазный трансформатор;
- М – маслонаполненный;
- Г – герметичное исполнение;
- 250 – номинальная мощность агрегата в кВА, как правило, варьируется в пределах от 16 до 2500кВА;
- 10 – номинальное значение обмотки высокого напряжения, для ТМГ это 10 или 6кВ;
- 0,4 – номинальная величина стороны низкого напряжения, измеряемая в киловольтах;
- Υ/ΥН -0 – схема соединения обмоток, по высокой стороне звездой, по низкой звездой с нулевым выводом, группа подключения нулевая. На практике может применяться и другой тип соединения с отличной от нуля группой.
- У1 – тип климатического исполнения.
Конструкция
Технические параметры предусматривают возможность установки силового масляного агрегата в трехфазную сеть. В виду этого устройство имеет ряд конструктивных особенностей, которые обеспечивают как удобство транспортировки, так и последующей эксплуатации на тяговых и трансформаторных подстанциях.
Конструкция трансформатора ТМГ состоит из следующих компонентов:
- Бак – представляет собой герметичную емкость из стали, на поверхности которой могут монтироваться радиаторные отводы и другое вспомогательное оборудование. Трансформаторы ТМГ, как правило, имеют овальную форму бака для электрических машин до 250кВА и прямоугольную в более мощных моделях.
- Магнитопровод – устройство для передачи магнитного потока. В большинстве случаев у трансформаторов ТМГ он выполнен шихтованными наборными пластинами из холоднокатаной стали. Для снижения потерь пластины набираются в косой стык.
- Обмотки – предназначены для пропуска электрического тока и последующей генерации электродвижущей силы, создающей магнитный поток. Изготавливаются из медных или алюминиевых проводников, сечение и форма провода выбирается в зависимости от величины протекающего тока. Могут иметь переключатель величины напряжения РПН.
- Трансформаторное масло – выступает в роли основной среды для отвода тепловой энергии и изоляции токоведущих частей от корпуса. Уровень масла контролируется посредством маслоуказателя поплавочного типа.
- Высоковольтные ввода – предназначены для прохода токоведущих частей через крышку бака. Его конструкция в ТМГ отличается в зависимости от величины пропускаемого тока, как показано на рисунке:
Технические характеристики
При выборе конкретной модели трансформатора ТМГ необходимо руководствоваться его техническими параметрами.
К основным характеристикам масляных трансформаторов относятся:
- Номинальная мощность – показывает, какой объем электрической энергии способен перерабатывает трансформатор.
- Номинальные напряжения – указывают разность потенциалов, обеспечивающую наиболее эффективный режим работы агрегата. Классы напряжения регламентируются как для низкой, так и для высокой стороны.
- Схема и группа подключения обмоток – определяет как напряжение, которое подается или выдается с соответствующей стороны ТМГ, так и направление векторов действующих электрических величин.
- Ток холостого хода – значение потерь в ненагруженном состоянии;
- Напряжение короткого замыкания – процентная величина от номинальной, при которой в короткозамкнутой вторичке будет протекать номинальный ток.
- Потери мощности на намагничивание – определяется величиной вихревых токов.
- Диапазон рабочих температур – как правило, колеблется в пределах от – 40°С до + 40°С, но некоторые трехфазные масляные ТМГ рассчитаны для холодных зон от – 60°С до +40°С.
- Габаритные размеры и масса, также отдельно учитывается вес трансформаторного масла.
Все значения для трансформатора ТМГ можно увидеть в паспорте или на табличке самого агрегата.
Рис. 4. Пример обозначения характеристик на табличке ТМГУсловия эксплуатации
Для трансформаторов ТМГ важно соблюдать параметры его работы как по отношению к состоянию масляного герметичного агрегата, так и относительно внешних факторов. Поэтому он не должен применяться для преобразования электрической энергии при высоте над уровнем моря более 1000м. Также не рекомендуется использовать трансформатор серии ТМГ в условиях частых отключений питания (от 10 и более за сутки), при наличии вибрации в месте установки, во взрывоопасных и пожароопасных зонах.
Рекомендуется устанавливать как в закрытых распредустройствах, так и на улице. Относительная влажность может составлять до 80%. В ходе эксплуатации обязательно контролируется уровень масла по указателю, как техническая характеристика и ее соответствие реальному температурному режиму. Температура, в которой работает электрическая машина не должна выходить за установленные пределы.
Перемещение трансформатора ТМГ должно производиться исключительно в четко зафиксированном положении на подставках, при необходимости производится увязка. Погрузка и выгрузка осуществляется только за специальные петли.
Техническое обслуживание
Под техническим обслуживанием электротехнического оборудования подразумевается комплекс мер, направленных на осуществление постоянного контроля за состоянием ТМГ, поддержание его работоспособности и своевременного выявления дефектов на ранних стадиях. Для этого производятся ежедневные осмотры, производимые оперативным персоналом, текущий ремонт, межремонтные испытания и капитальный ремонт. Объем задач для каждого вида обслуживания определяется как Правилами технической эксплуатации электроустановок потребителей (ПТЭЭП), так и местными инструкциями.
Периодически осуществляется проверка состояния изоляции при помощи мегаомметра. Согласно приложения 3.1. ПТЭЭП измерения выполняются напряжением в 2500 В, а сопротивление электрической изоляции не должно быть менее 500 МОм. Также проверяется тангенс угла диэлектрических потерь, коэффициент трансформации и омическое сопротивление.
При осмотре обращается внимание на состояние радиаторов охлаждения, корпус бака проверяется на наличие подтеков масла. В отличии от сухого трансформатора, по результатам испытаний отбирается масло для анализа. Проверяется работоспособность встроенных защит, включая встроенные специальные трансформаторы для измерений.
Отличия ТМ от ТМГ
Рис. 5. Сравнение трансформаторов ТМГ и ТМТрансформаторы ТМГ нередко сравнивают со схожим по маркировке ТМ, давайте рассмотрим сравнительную характеристику с одним из таких агрегатов на примере следующей таблицы:
Таблица: сравнительные характеристики трансформаторов ТМГ и ТМ
| ТМГ | ТМ |
| Отличается более эффективной конструкцией бака, что позволяет улучшить охлаждение, применяя менее сложную конструкцию | Применяется классический толстостенный бак с радиаторами устаревшего типа. |
| За счет герметизации трансформатора масло не контактирует с атмосферным воздухом, что позволяет сохранять диэлектрические свойства. | На жидкий диэлектрик оказывают воздействие не только внутренние процессы, но и влага из окружающего воздуха. |
| Широко используется конструкция без расширителя. | На крышке устанавливается расширительный бак для обеспечения наполнения емкости. |
| Сигнализатор уровня масла поплавкового типа | Сигнализатор уровня масла трубчатый |
| Проблемы с избыточным давлением из-за отсутствия расширительного бака, газы сбрасываются через клапан. | Избыток газа или масла при нагреве легко перемещается в расширитель или через дыхательный патрон в окружающее пространство. |
| Необходимо постоянно контролировать давление на манометре. | Давление самостоятельно стабилизируется за счет расширителя. |
| Низкие показатели надежности от механических или вибрационных воздействий на трансформатор. | Высокая степень надежности, трансформатор не боится механических воздействий. |
| Непригоден к проведению капитального ремонта со вскрытием крышки, так как затруднена повторная герметизация с закачкой масла. | Капитальный ремонт может производиться любое количество раз. |
| Срок службы от 20 до 30 лет | Срок службы от 40 до 50лет |
Назначение
Трансформатор ТМГ предназначен для питания потребителей различных сфер народного хозяйства, промышленности или бытового сектора. В виду большого разнообразия номинала мощностей ТМГ, их применяют и для электроснабжения отдельных коттеджей, и для работы крупных цехов, подстанций и т.д. Чаще всего применяются как понижающие трансформаторы от сети к потребителю.
Использованная литература
- Э.Л. Мальц, Ю.Н. Мустафаев «Электротехника и электрические машины» 2013
- Почаевец В.С. «Электрические подстанции» 2001
- Марквардт К.Г. «Электроснабжение электрифицированных железных дорог» 1982
- Прохорский А.А. «Тяговые и трансформаторные подстанции» 1983
The Illustrated Transformer — Джей Аламмар — Визуализация машинного обучения по одной концепции за раз.
Обсуждения:
Hacker News (65 баллов, 4 комментария), Reddit r / MachineLearning (29 баллов, 3 комментария)
Переводы: Испанский, Китайский (упрощенный), Корейский, Русский, Вьетнамский, Французский, Японский
Смотреть: лекция MIT по теме «Глубокое обучение» со ссылкой на эту публикацию
В предыдущем посте мы рассмотрели «Внимание» — повсеместный метод в современных моделях глубокого обучения.Внимание — это концепция, которая помогла повысить производительность приложений нейронного машинного перевода. В этом посте мы рассмотрим The Transformer — модель, которая привлекает внимание для повышения скорости обучения этих моделей. Трансформеры превосходят модель нейронного машинного перевода Google в определенных задачах. Однако самое большое преимущество заключается в том, что The Transformer поддается распараллеливанию. Фактически, Google Cloud рекомендует использовать The Transformer в качестве эталонной модели для использования своего предложения Cloud TPU.Итак, давайте попробуем разбить модель на части и посмотрим, как она работает.
Трансформатор был предложен в статье «Внимание — это все, что вам нужно». Его реализация в TensorFlow доступна как часть пакета Tensor2Tensor. Группа НЛП из Гарварда создала руководство с аннотациями к статье с использованием PyTorch. В этом посте мы попытаемся немного упростить вещи и представить концепции одну за другой, чтобы, надеюсь, облегчить понимание людям без глубоких знаний предмета.
2020 Обновление : Я создал видео «Рассказанный трансформер», в котором более мягкий подход к теме:
Взгляд высокого уровня
Давайте начнем с рассмотрения модели как единого черного ящика. В приложении машинного перевода оно берет предложение на одном языке и выводит его перевод на другом.
Раскрывая эту доброту Оптимуса Прайма, мы видим компонент кодирования, компонент декодирования и связи между ними.
Компонент кодирования представляет собой стек кодировщиков (на бумаге шесть из них складываются друг на друга — в числе шесть нет ничего волшебного, можно определенно поэкспериментировать с другими компоновками). Компонент декодирования представляет собой стек декодеров с одинаковым числом.
Все кодировщики идентичны по структуре (но у них нет общих весов). Каждый из них разбит на два подслоя:
Входные данные кодировщика сначала проходят через слой самовнимания — слой, который помогает кодировщику смотреть на другие слова во входном предложении, когда он кодирует определенное слово.Позже мы подробнее рассмотрим самовнимание.
Выходные данные слоя самовнимания передаются в нейронную сеть с прямой связью. Точно такая же сеть прямой связи независимо применяется к каждой позиции.
В декодере есть оба этих уровня, но между ними есть уровень внимания, который помогает декодеру сосредоточиться на соответствующих частях входного предложения (аналогично тому, что делает внимание в моделях seq2seq).
Использование тензоров в картине
Теперь, когда мы увидели основные компоненты модели, давайте начнем смотреть на различные векторы / тензоры и то, как они перемещаются между этими компонентами, чтобы превратить входные данные обученной модели в выходные данные.
Как и в случае с приложениями НЛП в целом, мы начинаем с преобразования каждого входного слова в вектор с помощью алгоритма встраивания.
Каждое слово вложено в вектор размером 512. Мы представим эти векторы этими простыми прямоугольниками.
Встраивание происходит только в самый нижний кодировщик. Абстракция, которая является общей для всех кодировщиков, заключается в том, что они получают список векторов, каждый размером 512. В нижнем кодировщике это будет слово embeddings, но в других кодировщиках это будет выход кодировщика, который находится непосредственно под .Размер этого списка — это гиперпараметр, который мы можем установить — в основном это будет длина самого длинного предложения в нашем наборе обучающих данных.
После встраивания слов в нашу входную последовательность каждое из них проходит через каждый из двух уровней кодировщика.
Здесь мы начинаем видеть одно ключевое свойство преобразователя, а именно то, что слово в каждой позиции проходит свой собственный путь в кодировщике. Между этими путями на уровне самовнимания есть зависимости.Однако слой прямой связи не имеет этих зависимостей, и, таким образом, различные пути могут выполняться параллельно при прохождении через слой прямой связи.
Затем мы заменим пример более коротким предложением и посмотрим, что происходит на каждом подуровне кодировщика.
Теперь мы кодируем!
Как мы уже упоминали, кодировщик получает на вход список векторов. Он обрабатывает этот список, передавая эти векторы в слой «самовнимания», затем в нейронную сеть с прямой связью, а затем отправляет выходные данные вверх следующему кодировщику.
Слово в каждой позиции проходит через процесс самовнимания. Затем каждый из них проходит через нейронную сеть с прямой связью — точно такую же сеть с каждым вектором, протекающим через нее отдельно.
Самовнимание на высоком уровне
Не обманывайтесь, когда я использую слово «самовнимание», как будто это понятие должно быть знакомо каждому. Я лично никогда не сталкивался с этой концепцией до тех пор, пока не прочитал статью «Все, что вам нужно». Давайте разберемся, как это работает.
Скажем, следующее предложение является вводным предложением, которое мы хотим перевести:
” Животное не переходило улицу, потому что оно слишком устало ”
Что означает «оно» в этом предложении? Имеется в виду улица или животное? Это простой вопрос для человека, но не такой простой для алгоритма.
Когда модель обрабатывает слово «оно», самовнимание позволяет ей ассоциировать «это» с «животным».
По мере того, как модель обрабатывает каждое слово (каждую позицию во входной последовательности), самовнимание позволяет ей смотреть на другие позиции во входной последовательности в поисках подсказок, которые могут помочь улучшить кодирование этого слова.
Если вы знакомы с RNN, подумайте о том, как поддержание скрытого состояния позволяет RNN включать свое представление предыдущих слов / векторов, которые она обработала, с текущим, обрабатываемым ею. Самовнимание — это метод, который Трансформер использует для «запекания» других релевантных слов в словах, которые мы обрабатываем в данный момент.
Поскольку мы кодируем слово «оно» в кодировщике №5 (верхний кодировщик в стеке), часть механизма внимания фокусировалась на «Животном» и запекла часть его представления в кодировке «оно».
Обязательно ознакомьтесь с записной книжкой Tensor2Tensor, где вы можете загрузить модель Transformer и изучить ее с помощью этой интерактивной визуализации.
Самостоятельное внимание в деталях
Давайте сначала посмотрим, как вычислить самовнимание с помощью векторов, а затем перейдем к тому, как это на самом деле реализовано — с помощью матриц.
Первый шаг в вычислении самовнимания состоит в том, чтобы создать три вектора из каждого из входных векторов кодировщика (в данном случае — вложение каждого слова).Итак, для каждого слова мы создаем вектор запроса, вектор ключа и вектор значения. Эти векторы создаются путем умножения вложения на три матрицы, которые мы обучили в процессе обучения.
Обратите внимание, что эти новые векторы меньше по размерности, чем вектор внедрения. Их размерность составляет 64, в то время как векторы ввода / вывода встраивания и кодировщика имеют размерность 512. Они НЕ ДОЛЖНЫ быть меньше, это выбор архитектуры, позволяющий сделать вычисление многогранного внимания (в основном) постоянным.
Умножение x1 на весовую матрицу WQ дает q1, вектор «запроса», связанный с этим словом. В итоге мы создаем проекцию «запроса», «ключа» и «значения» для каждого слова во входном предложении.
Что такое векторы «запроса», «ключа» и «значения»?
Это абстракции, которые полезны для вычисления внимания и размышления о нем. После того, как вы перейдете к прочтению того, как рассчитывается внимание ниже, вы будете знать почти все, что вам нужно знать о роли каждого из этих векторов.
Второй шаг в вычислении самовнимания — это подсчет баллов. Предположим, мы рассчитываем самовнимание для первого слова в этом примере «Мышление». Нам нужно сопоставить каждое слово входного предложения с этим словом. Оценка определяет, сколько внимания следует уделять другим частям входного предложения, когда мы кодируем слово в определенной позиции.
Оценка рассчитывается как скалярное произведение вектора запроса на ключевой вектор соответствующего слова, которое мы оцениваем.Итак, если мы обрабатываем самовнимание для слова в позиции №1, первая оценка будет скалярным произведением q1 и k1. Вторая оценка будет скалярным произведением q1 и k2.
Третий и четвертый этапы заключаются в разделении оценок на 8 (квадратный корень из размерности ключевых векторов, используемых в статье — 64. Это приводит к получению более стабильных градиентов. Здесь могут быть другие возможные значения, но это значение по умолчанию), затем передайте результат через операцию softmax.Softmax нормализует оценки, чтобы все они были положительными и в сумме составляли 1.
.Эта оценка softmax определяет, насколько каждое слово будет выражено в этой позиции. Очевидно, что слово в этой позиции будет иметь самый высокий балл softmax, но иногда полезно обратить внимание на другое слово, имеющее отношение к текущему слову.
Пятый шаг — это умножение каждого вектора значений на оценку softmax (при подготовке к их суммированию). Интуиция здесь заключается в том, чтобы сохранить неизменными значения слов, на которых мы хотим сосредоточиться, и заглушить не относящиеся к делу слова (умножив их на крошечные числа, такие как 0.001, например).
Шестой этап заключается в суммировании векторов взвешенных значений. Это производит вывод слоя самовнимания в этой позиции (для первого слова).
На этом расчет самовнимания завершен. Результирующий вектор — это тот, который мы можем отправить в нейронную сеть с прямой связью. Однако в реальной реализации этот расчет выполняется в матричной форме для более быстрой обработки. Итак, давайте посмотрим на это теперь, когда мы увидели интуитивное вычисление на уровне слов.
Матрица расчета самовнимания
Первым шагом является вычисление матриц запроса, ключа и значения. Мы делаем это, упаковывая наши вложения в матрицу X и умножая ее на матрицы весов, которые мы обучили (WQ, WK, WV).
Каждая строка в матрице X соответствует слову во входном предложении. Мы снова видим разницу в размере вектора встраивания (512 или 4 прямоугольника на рисунке) и векторов q / k / v (64 или 3 прямоугольника на рисунке).
Наконец, , поскольку мы имеем дело с матрицами, мы можем объединить шаги со второго по шестой в одну формулу, чтобы вычислить результаты слоя самовнимания.
Расчет самовнимания в матричной форме
Многоголовый зверь
В статье дополнительно усовершенствован слой самовнимания, добавлен механизм, называемый «многоголовым» вниманием. Это улучшает производительность слоя внимания двумя способами:
Расширяет способность модели фокусироваться на разных позициях. Да, в приведенном выше примере z1 содержит немного любой другой кодировки, но в ней может преобладать само слово.Было бы полезно, если бы мы переводили предложение вроде «Животное не перешло улицу, потому что оно слишком устало», мы хотели бы знать, к какому слову «оно» относится.
Он дает слою внимания несколько «подпространств представления». Как мы увидим дальше, с многоголовым вниманием у нас есть не только один, но и несколько наборов весовых матриц запроса / ключа / значения (преобразователь использует восемь головок внимания, поэтому мы получаем восемь наборов для каждого кодировщика / декодера). . Каждый из этих наборов инициализируется случайным образом.Затем, после обучения, каждый набор используется для проецирования входных вложений (или векторов из нижних кодировщиков / декодеров) в другое подпространство представления.
С многоголовым вниманием мы поддерживаем отдельные весовые матрицы Q / K / V для каждой головы, в результате чего получаются разные матрицы Q / K / V. Как и раньше, мы умножаем X на матрицы WQ / WK / WV, чтобы получить матрицы Q / K / V.
Если мы проделаем тот же самый расчет самовнимания, который мы описали выше, всего восемь раз с разными весовыми матрицами, мы получим восемь разных Z-матриц
Это оставляет нам небольшую проблему.Слой прямой связи не ожидает восьми матриц — он ожидает единственную матрицу (вектор для каждого слова). Итак, нам нужен способ сжать эти восемь в единую матрицу.
Как мы это делаем? Мы объединяем матрицы, а затем умножаем их на дополнительную матрицу весов WO.
Вот и все, что нужно для многоглавого самовнимания. Я понимаю, что это довольно много матриц. Позвольте мне попытаться объединить их все в один визуальный ряд, чтобы мы могли рассматривать их в одном месте
Теперь, когда мы коснулись головок внимания, давайте вернемся к нашему предыдущему примеру, чтобы увидеть, где фокусируются различные головы внимания, когда мы кодируем слово «оно» в нашем примере предложения:
Когда мы кодируем слово «оно», одна голова внимания больше всего сосредотачивается на «животном», в то время как другая фокусируется на «усталом» — в некотором смысле, представление модели слова «оно» вписывается в некоторые из представлений. как «животное», так и «уставшее».
Однако, если мы добавим к изображению все внимание, интерпретировать вещи будет сложнее:
Представление порядка последовательности с использованием позиционного кодирования
В модели, которую мы описали до сих пор, отсутствует одна вещь, так это способ учесть порядок слов во входной последовательности.
Чтобы решить эту проблему, преобразователь добавляет вектор к каждому встраиванию входа. Эти векторы следуют определенному шаблону, который модель изучает, что помогает ей определять положение каждого слова или расстояние между разными словами в последовательности.Интуиция здесь заключается в том, что добавление этих значений к вложениям обеспечивает значимые расстояния между векторами встраивания, когда они проецируются в векторы Q / K / V и во время внимания скалярного произведения.
Чтобы дать модели ощущение порядка слов, мы добавляем векторы позиционного кодирования, значения которых следуют определенному шаблону.
Если бы мы предположили, что вложение имеет размерность 4, фактическое позиционное кодирование будет выглядеть так:
Реальный пример позиционного кодирования с размером вложения игрушки 4
Как мог бы выглядеть этот узор?
На следующем рисунке каждая строка соответствует позиционному кодированию вектора.Таким образом, первая строка будет вектором, который мы добавим к встраиванию первого слова во входной последовательности. Каждая строка содержит 512 значений — каждое от 1 до -1. Мы присвоили им цветовую кодировку, чтобы узор был виден.
Реальный пример позиционного кодирования для 20 слов (строк) с размером встраивания 512 (столбцов). Вы можете видеть, что он разделен пополам по центру. Это потому, что значения левой половины генерируются одной функцией (которая использует синус), а правая половина генерируется другой функцией (которая использует косинус).Затем они объединяются, чтобы сформировать каждый из векторов позиционного кодирования.
Формула позиционного кодирования описана в статье (раздел 3.5). Вы можете увидеть код для генерации позиционных кодировок в get_timing_signal_1d () . Это не единственный возможный метод позиционного кодирования. Однако это дает преимущество возможности масштабирования до невидимой длины последовательностей (например, если нашу обученную модель просят перевести предложение длиннее, чем любое из предложений в нашем обучающем наборе).
Июль 2020 Обновление: Позиционное кодирование, показанное выше, взято из реализации преобразователя Tranformer2Transformer. Метод, показанный в статье, немного отличается тем, что он не соединяет напрямую, а переплетает два сигнала. На следующем рисунке показано, как это выглядит. Вот код для его создания:
Остатки
Одна деталь в архитектуре кодера, которую мы должны упомянуть, прежде чем двигаться дальше, заключается в том, что каждый подуровень (самовнимание, ffnn) в каждом кодере имеет остаточное соединение вокруг себя, за которым следует этап нормализации уровня. .
Если мы визуализируем векторы и операцию уровня-нормы, связанную с самовниманием, это будет выглядеть так:
Это также относится к подуровням декодера. Если мы представим себе преобразователь из двух стековых кодировщиков и декодеров, он будет выглядеть примерно так:
Сторона декодера
Теперь, когда мы рассмотрели большинство концепций кодировщика, мы в основном знаем, как работают компоненты декодеров.Но давайте посмотрим, как они работают вместе.
Кодер запускает обработку входной последовательности. Затем выходной сигнал верхнего кодера преобразуется в набор векторов внимания K и V. Они должны использоваться каждым декодером на его уровне «внимание кодер-декодер», который помогает декодеру сосредоточиться на соответствующих местах во входной последовательности:
После завершения этапа кодирования мы начинаем этап декодирования. Каждый шаг на этапе декодирования выводит элемент из выходной последовательности (в данном случае это предложение английского перевода).
Следующие шаги повторяют процесс до тех пор, пока не будет достигнут специальный символ, указывающий, что декодер трансформатора завершил свой вывод. Выходные данные каждого шага поступают в нижний декодер на следующем временном шаге, и декодеры выводят свои результаты декодирования точно так же, как это сделали кодеры. И так же, как мы поступили с входами кодировщика, мы встраиваем и добавляем позиционное кодирование к этим входам декодера, чтобы указать положение каждого слова.
Слои самовнимания в декодере работают немного иначе, чем в кодировщике:
В декодере слой самовнимания может обращать внимание только на более ранние позиции в выходной последовательности.Это делается путем маскировки будущих позиций (установка для них значений -inf ) перед шагом softmax в расчете самовнимания.
Слой «Внимание кодировщика-декодера» работает так же, как многоголовое самовнимание, за исключением того, что он создает свою матрицу запросов из нижележащего уровня и берет матрицу ключей и значений из выходных данных стека кодировщика.
Последний линейный слой и слой Softmax
Стек декодера выводит вектор чисел с плавающей запятой. Как превратить это в слово? Это работа последнего слоя Linear, за которым следует слой Softmax.
Линейный слой — это простая полносвязная нейронная сеть, которая проецирует вектор, созданный стеком декодеров, в гораздо более крупный вектор, называемый вектором логитов.
Предположим, что наша модель знает 10 000 уникальных английских слов («выходной словарь» нашей модели), которые она выучила из набора обучающих данных. Это сделало бы вектор логитов шириной 10 000 ячеек — каждая ячейка соответствует количеству уникального слова. Вот как мы интерпретируем вывод модели, за которой следует линейный слой.
Затем слой softmax превращает эти оценки в вероятности (все положительные, все в сумме дают 1,0). Выбирается ячейка с наибольшей вероятностью, и слово, связанное с ней, создается в качестве выходных данных для этого временного шага.
Этот рисунок начинается снизу с вектора, полученного на выходе стека декодера. Затем оно превращается в выходное слово.
Итоги обучения
Теперь, когда мы рассмотрели весь процесс прямого прохода через обученный преобразователь, было бы полезно взглянуть на интуицию обучения модели.
Во время обучения неподготовленная модель должна пройти точно такой же прямой проход. Но поскольку мы обучаем его на помеченном наборе обучающих данных, мы можем сравнить его выходные данные с фактическими правильными выходными данными.
Для наглядности предположим, что наш выходной словарь содержит только шесть слов («а», «я», «я», «спасибо», «ученик» и «
Выходной словарь нашей модели создается на этапе предварительной обработки еще до того, как мы начинаем обучение.
Как только мы определим наш выходной словарь, мы можем использовать вектор той же ширины для обозначения каждого слова в нашем словаре. Это также называется горячим кодированием. Так, например, мы можем обозначить слово «am» с помощью следующего вектора:
Пример: быстрое кодирование нашего выходного словаря
После этого резюме, давайте обсудим функцию потерь модели — метрику, которую мы оптимизируем на этапе обучения, чтобы привести к обученной и, надеюсь, удивительно точной модели.
Функция потерь
Допустим, мы обучаем нашу модель. Допустим, это наш первый шаг на этапе обучения, и мы обучаем его на простом примере — переводе слова «мерси» в «спасибо».
Это означает, что мы хотим, чтобы на выходе было распределение вероятностей с указанием слова «спасибо». Но поскольку эта модель еще не обучена, это вряд ли произойдет.
Поскольку все параметры модели (веса) инициализируются случайным образом, (необученная) модель создает распределение вероятностей с произвольными значениями для каждой ячейки / слова.Мы можем сравнить его с фактическим результатом, а затем настроить все веса модели с помощью обратного распространения ошибки, чтобы приблизить результат к желаемому результату.
Как сравнить два распределения вероятностей? Мы просто вычитаем одно из другого. Для получения дополнительных сведений см. Кросс-энтропию и расхождение Кульбака – Лейблера.
Но учтите, что это упрощенный пример. Более реалистично, мы будем использовать предложение длиннее одного слова. Например — ввод: «je suis étudiant» и ожидаемый результат: «я студент».На самом деле это означает, что мы хотим, чтобы наша модель последовательно выводила распределения вероятностей, где:
- Каждое распределение вероятностей представлено вектором ширины vocab_size (6 в нашем игрушечном примере, но более реалистично число вроде 30 000 или 50 000)
- Первое распределение вероятностей имеет наивысшую вероятность в ячейке, связанной со словом «i»
- Второе распределение вероятностей имеет самую высокую вероятность в ячейке, связанной со словом «am»
- И так далее, пока пятое выходное распределение не укажет символ «
<конец предложения>», с которым также связана ячейка из словаря из 10 000 элементов.
Целевые распределения вероятностей, с которыми мы будем обучать нашу модель в обучающем примере для одного предложения-образца.
После обучения модели в течение достаточного времени на достаточно большом наборе данных мы надеемся, что полученные распределения вероятностей будут выглядеть так:
Надеемся, что после обучения модель выдаст правильный перевод, который мы ожидаем. Конечно, это не настоящее указание на то, была ли эта фраза частью обучающего набора данных (см .: перекрестная проверка).Обратите внимание, что каждая позиция имеет небольшую вероятность, даже если она вряд ли будет результатом этого временного шага — это очень полезное свойство softmax, которое помогает процессу обучения.
Теперь, поскольку модель производит выходные данные по одному, мы можем предположить, что модель выбирает слово с наибольшей вероятностью из этого распределения вероятностей и отбрасывает остальные. Это один из способов сделать это (называется жадным декодированием). Другой способ сделать это — удержаться, скажем, за два верхних слова (скажем, «I» и «a», например), а затем на следующем шаге дважды запустить модель: однажды предполагая, что первая выходная позиция была слово «I», и в другой раз, предполагая, что первой выходной позицией было слово «а», и какая бы версия ни вызвала меньше ошибок, учитывая обе позиции №1 и №2, сохраняется.Мы повторяем это для позиций №2 и №3… и т. Д. Этот метод называется «поиск луча», где в нашем примере для beam_size было два (это означает, что всегда две частичные гипотезы (незавершенные переводы) сохраняются в памяти), а top_beams также равно двум (что означает, что мы вернем два перевода. ). Это оба гиперпараметра, с которыми вы можете поэкспериментировать.
Двигайтесь вперед и трансформируйте
Я надеюсь, что вы нашли это полезным местом, чтобы начать ломать голову над основными концепциями Трансформера.Если вы хотите глубже, я бы посоветовал следующие шаги:
Доработка:
Благодарности
Благодарим Илью Полосухина, Якоба Ушкорейта, Ллиона Джонса, Лукаша Кайзера, Ники Пармар и Ноама Шазира за отзывы о более ранних версиях этого поста.
Пожалуйста, напишите мне в Твиттер, чтобы я получил любые исправления или отзывы.
Модели кодировщика-декодера на базе трансформатора
Опубликовано 8 октября 2020 г. Обновление на GitHub ! Pip install трансформаторы == 4.2.1
! pip install фраза == 0.1.95 Модель кодера-декодера на базе трансформатора была представлена Васвани. и другие. в знаменитом Attention — это все, что вам нужно бумаги и сегодня де-факто стандартная архитектура кодера-декодера при обработке естественного языка (НЛП).
В последнее время было проведено множество исследований различных предтренировочных объективы для моделей кодеров-декодеров на базе трансформаторов, например Т5, Барт, Пегас, ProphetNet, Мардж, и т. Д. …, но модель архитектуры остался в основном прежним.
Цель сообщения в блоге — дать подробное объяснение , как модели архитектуры кодера-декодера на основе трансформатора последовательность-последовательность проблем. Сфокусируемся на математической модели определяется архитектурой и тем, как модель может использоваться для вывода. Попутно мы дадим некоторую справочную информацию о последовательности в последовательность. модели в NLP и разбить кодер-декодер на основе трансформатора архитектура в его кодер и декодер частей.Мы предоставляем много иллюстрации и установить связь между теорией модели кодеров-декодеров на базе трансформаторов и их практическое применение в 🤗Трансформаторы для вывода. Обратите внимание, что это сообщение в блоге не объясняет , а . как такие модели можно обучить — это тема будущего блога сообщение.
Модели кодировщиков-декодеров на базе трансформаторов являются результатом многолетней Исследование представлений , обучение модели и архитектуры . Этот блокнот содержит краткое изложение истории нейронных кодировщики-декодеры модели.Для получения дополнительной информации читателю рекомендуется прочитать этот замечательный блог опубликовать Себастион Рудер. Кроме того, базовое понимание архитектура самовнимания рекомендуется. Следующее сообщение в блоге автора Джей Аламмар служит хорошим напоминанием об оригинальной модели Transformer. здесь.
На момент написания этого блокнота «Трансформеры включают кодировщик-декодер моделей T5 , Bart , MarianMT и Pegasus , которые кратко описаны в документации по модели резюме.
Ноутбук разделен на четыре части:
- Предпосылки — Краткая история моделей нейронных кодировщиков-декодеров дается с акцентом на модели на основе RNN.
- Кодер-декодер — Модель кодера-декодера на основе трансформатора представлена и объясняется, как модель используется для вывод.
- Энкодер — Энкодер модели поясняется в деталь.
- Декодер — Декодерная часть модели поясняется в деталь.
Каждая часть основана на предыдущей части, но также может быть прочитана на ее собственный.
ФонЗадачи генерации естественного языка (NLG), подполе NLP, являются лучшими выражаются как задачи от последовательности к последовательности. Такие задачи можно определить как поиск модели, которая отображает последовательность входных слов в последовательность целевые слова. Вот некоторые классические примеры: , сводка и перевод . Далее мы предполагаем, что каждое слово закодировано в векторное представление.входные слова nnn могут быть представлены как последовательность входных векторов nnn:
X1: n = {x1,…, xn}. \ Mathbf {X} _ {1: n} = \ {\ mathbf {x} _1, \ ldots, \ mathbf {x} _n \}. X1: n = {x1,…, xn}.
Следовательно, проблемы от последовательности к последовательности могут быть решены путем нахождения отображение fff из входной последовательности nnn векторов X1: n \ mathbf {X} _ {1: n} X1: n в последовательность целевых векторов mmm Y1: m \ mathbf {Y} _ {1: m} Y1: m, тогда как число целевых векторов ммм априори неизвестно и зависит от входных данных последовательность:
f: X1: n → Y1: m.22 для решения задач от последовательности к последовательности следовательно, означает, что количество целевых векторов mmm должно быть известно apriori и должен быть независимым от ввода X1: n \ mathbf {X} _ {1: n} X1: n. Это неоптимально, потому что для задач в NLG количество целевых слов обычно зависит от ввода X1: n \ mathbf {X} _ {1: n} X1: n и не только на входной длине nnn. Например. , статья 1000 слов можно суммировать как до 200 слов, так и до 100 слов в зависимости от его содержание.
В 2014 г. Cho et al.33. После обработки последнего входного вектора xn \ mathbf {x} _nxn, Скрытое состояние кодировщика определяет кодировку ввода c \ mathbf {c} c. Таким образом, кодировщик определяет отображение:
fθenc: X1: n → c. f _ {\ theta_ {enc}}: \ mathbf {X} _ {1: n} \ to \ mathbf {c}. fθenc: X1: n → c.
Затем скрытое состояние декодера инициализируется входной кодировкой. и во время логического вывода декодер RNN используется для авторегрессивного генерировать целевую последовательность. Поясним.
Математически декодер определяет распределение вероятностей целевая последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m с учетом скрытого состояния c \ mathbf {c} c:
pθdec (Y1: m∣c).{m} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}). pθdec (Y1: m ∣c) = i = 1∏m pθdec (yi ∣Y0: i − 1, c).
Таким образом, если архитектура может моделировать условное распределение следующий целевой вектор, учитывая все предыдущие целевые векторы:
pθdec (yi∣Y0: i − 1, c), ∀i∈ {1,…, m}, p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}), \ forall i \ in \ {1, \ ldots, m \}, pθdec (yi ∣Y0: i − 1, c), ∀ i∈ {1,…, m},
, то он может моделировать распределение любой последовательности целевого вектора, заданной скрытое состояние c \ mathbf {c} c путем простого умножения всех условных вероятности.
Так как же модель архитектуры декодера на основе RNN pθdec (yi∣Y0: i − 1, c) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ { 0: i-1}, \ mathbf {c}) pθdec (yi ∣Y0: i − 1, c)?
С точки зрения вычислений, модель последовательно отображает предыдущий внутренний скрытое состояние ci − 1 \ mathbf {c} _ {i-1} ci − 1 и предыдущий целевой вектор yi \ mathbf {y} _iyi до текущего внутреннего скрытого состояния ci \ mathbf {c} _ici и a вектор logit li \ mathbf {l} _ili (показано темно-красным цветом ниже):
fθdec (yi − 1, ci − 1) → li, ci.f _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _ {i-1}, \ mathbf {c} _ {i-1}) \ to \ mathbf {l} _i, \ mathbf {c } _i.fθdec (yi − 1, ci − 1) → li, ci. c0 \ mathbf {c} _0c0 таким образом определяется как c \ mathbf {c} c, являющийся выходом скрытое состояние кодировщика на основе RNN. Впоследствии softmax используется для преобразования вектора логита li \ mathbf {l} _ili в условное распределение вероятностей следующего целевого вектора:
p (yi∣li) = Softmax (li), где li = fθdec (yi − 1, cprev). p (\ mathbf {y} _i | \ mathbf {l} _i) = \ textbf {Softmax} (\ mathbf {l} _i), \ text {with} \ mathbf {l} _i = f _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _ {i-1}, \ mathbf {c} _ {\ text {prev}}).44. Из приведенного выше уравнения мы можно видеть, что распределение текущего целевого вектора yi \ mathbf {y} _iyi напрямую обусловлено предыдущим целевым вектором yi − 1 \ mathbf {y} _ {i-1} yi − 1 и предыдущим скрытым состоянием ci −1 \ mathbf {c} _ {i-1} ci − 1. Поскольку предыдущее скрытое состояние ci − 1 \ mathbf {c} _ {i-1} ci − 1 зависит от всех предыдущие целевые векторы y0,…, yi − 2 \ mathbf {y} _0, \ ldots, \ mathbf {y} _ {i-2} y0,…, yi − 2, он может быть заявлено, что декодер на основе RNN неявно ( например, косвенно ) моделирует условное распределение pθdec (yi∣Y0: i − 1, c) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}) pθdec (yi ∣Y0: i − 1, c).55, которые эффективно выбирают целевой вектор с высокой вероятностью последовательности из pθdec (Y1: m∣c) p _ {\ theta_ {dec}} (\ mathbf {Y} _ {1: m} | \ mathbf {c}) pθdec (Y1: m ∣c).
При таком методе декодирования во время вывода следующий входной вектор yi \ mathbf {y} _iyi может быть выбран из pθdec (yi∣Y0: i − 1, c) p _ {\ theta _ {\ text {dec}} } (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}) pθdec (yi ∣Y0: i − 1, c) и, следовательно, добавляется к входной последовательности, так что декодер Затем RNN моделирует pθdec (yi + 1∣Y0: i, c) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _ {i + 1} | \ mathbf {Y} _ {0: i }, \ mathbf {c}) pθdec (yi + 1 ∣Y0: i, c) для выборки следующего входного вектора yi + 1 \ mathbf {y} _ {i + 1} yi + 1 и так далее в авторегрессивный мода.
Важной особенностью моделей кодеров-декодеров на основе RNN является определение специальных векторов , таких как вектор EOS \ text {EOS} EOS и BOS \ text {BOS} BOS. Вектор EOS \ text {EOS} EOS часто представляет собой окончательный входной вектор xn \ mathbf {x} _nxn, чтобы «указать» кодировщику, что вход последовательность закончилась, а также определяет конец целевой последовательности. В виде как только EOS \ text {EOS} EOS выбирается из вектора логита, генерация завершено. Вектор BOS \ text {BOS} BOS представляет собой входной вектор y0 \ mathbf {y} _0y0, подаваемый в декодер RNN на самом первом этапе декодирования.Для вывода первого логита l1 \ mathbf {l} _1l1 требуется ввод, и поскольку на первом шаге не было создано никаких входных данных. специальный BOS \ text {BOS} BOS входной вектор поступает на декодер RNN. Хорошо — довольно сложно! Давайте проиллюстрируйте и рассмотрите пример.
Развернутый кодировщик RNN окрашен в зеленый цвет, а развернутый RNN декодер окрашен в красный цвет.
Английское предложение «Я хочу купить машину», представленное как x1 = I \ mathbf {x} _1 = \ text {I} x1 = I, x2 = want \ mathbf {x} _2 = \ text {want} x2 = хочу, x3 = to \ mathbf {x} _3 = \ text {to} x3 = to, x4 = buy \ mathbf {x} _4 = \ text {buy} x4 = buy, x5 = a \ mathbf {x} _5 = \ text {a} x5 = a, x6 = car \ mathbf {x} _6 = \ text {car} x6 = car и x7 = EOS \ mathbf {x} _7 = \ text {EOS} x7 = EOS переводится на немецкий: «Ich will ein Auto kaufen «определяется как y0 = BOS \ mathbf {y} _0 = \ text {BOS} y0 = BOS, y1 = Ich \ mathbf {y} _1 = \ text {Ich} y1 = Ich, y2 = will \ mathbf {y} _2 = \ text {will} y2 = will, y3 = ein \ mathbf {y} _3 = \ text {ein} y3 = ein, y4 = Auto, y5 = kaufen \ mathbf {y} _4 = \ text {Auto}, \ mathbf {y} _5 = \ text {kaufen} y4 = Auto, y5 = kaufen и y6 = EOS \ mathbf {y} _6 = \ text {EOS} y6 = EOS. 66.На рисунке выше горизонтальная стрелка, соединяющая развернутый кодировщик RNN представляет собой последовательные обновления скрытых штат. Окончательное скрытое состояние кодировщика RNN, представленное c \ mathbf {c} c, затем полностью определяет кодировку входных данных. последовательность и используется как начальное скрытое состояние декодера RNN. Это можно увидеть как преобразование декодера RNN на закодированный вход.
Для генерации первого целевого вектора в декодер загружается BOS \ text {BOS} BOS вектор, показанный как y0 \ mathbf {y} _0y0 на рисунке выше.Цель вектор RNN затем дополнительно отображается на вектор логита l1 \ mathbf {l} _1l1 с помощью слоя прямой связи LM Head для определения условное распределение первого целевого вектора, как объяснено выше:
pθdec (y∣BOS, c). p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ mathbf {c}). pθdec (y∣BOS, c).
Выбирается слово Ich \ text {Ich} Ich (показано серой стрелкой, соединяющей l1 \ mathbf {l} _1l1 и y1 \ mathbf {y} _1y1) и, следовательно, вторая цель вектор может быть выбран:
будет ∼pθdec (y∣BOS, Ich, c).\ text {will} \ sim p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ text {Ich}, \ mathbf {c}). will∼pθdec (y∣BOS, Ich, c).
И так далее, пока на шаге i = 6i = 6i = 6, вектор EOS \ text {EOS} EOS не будет выбран из l6 \ mathbf {l} _6l6, и декодирование не будет завершено. Результирующая цель последовательность составляет Y1: 6 = {y1,…, y6} \ mathbf {Y} _ {1: 6} = \ {\ mathbf {y} _1, \ ldots, \ mathbf {y} _6 \} Y1: 6 = {y1,…, y6}, что является «Ich will ein Auto kaufen» в нашем примере выше.
Подводя итог, модель кодера-декодера на основе RNN, представленная fθencf _ {\ theta _ {\ text {enc}}} fθenc и pθdec p _ {\ theta _ {\ text {dec}}} pθdec, определяет распределение p (Y1: m∣X1: n) p (\ mathbf {Y} _ {1: m} | \ mathbf {X} _ {1: n}) p (Y1: m ∣X1: n) по факторизация:
pθenc, θdec (Y1: m∣X1: n) = ∏i = 1mpθenc, θdec (yi∣Y0: i − 1, X1: n) = ∏i = 1mpθdec (yi∣Y0: i − 1, c), с c = fθenc (X).{m} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {c}), \ text {with} \ mathbf {c} = f _ {\ theta_ {enc}} (X). pθenc, θdec (Y1: m ∣X1: n) = i = 1∏m pθenc, θdec (yi ∣Y0: i − 1, X1: n) = i = 1 ∏m pθdec (yi ∣Y0: i − 1, c), где c = fθenc (X).
Во время вывода эффективные методы декодирования могут авторегрессивно сгенерировать целевую последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m.
Модель кодера-декодера на основе RNN взяла штурмом сообщество NLG. В В 2016 г. компания Google объявила о полной замене разработанной услуги перевода с помощью единой модели кодировщика-декодера на основе RNN (см. здесь).44 Нейронная сеть может определять распределение вероятностей по всем слова, то есть p (y∣c, Y0: i − 1) p (\ mathbf {y} | \ mathbf {c}, \ mathbf {Y} _ {0: i-1}) p (y∣c , Y0: i − 1) как следует. Сначала сеть определяет отображение входов c, Y0: i − 1 \ mathbf {c}, \ mathbf {Y} _ {0: i-1} c, Y0: i − 1 во встроенное векторное представление y ′ \ Mathbf {y ‘} y ′, что соответствует целевому вектору RNN. Встроенный векторное представление y ′ \ mathbf {y ‘} y ′ затем передается «языку модель головы «, что означает, что он умножается на слово. матрица вложения , i.66 Sutskever et al. (2014) меняет порядок ввода так, чтобы в приведенном выше примере ввод векторы будут соответствовать x1 = car \ mathbf {x} _1 = \ text {car} x1 = car, x2 = a \ mathbf {x} _2 = \ text {a} x2 = a, x3 = buy \ mathbf { x} _3 = \ text {buy} x3 = buy, x4 = to \ mathbf {x} _4 = \ text {to} x4 = to, x5 = want \ mathbf {x} _5 = \ text {want} x5 = Хочу, x6 = I \ mathbf {x} _6 = \ text {I} x6 = I и x7 = EOS \ mathbf {x} _7 = \ text {EOS} x7 = EOS. В мотивация состоит в том, чтобы обеспечить более короткую связь между соответствующими пары слов, такие как x6 = I \ mathbf {x} _6 = \ text {I} x6 = I и y1 = Ich \ mathbf {y} _1 = \ text {Ich} y1 = Ich.Исследовательская группа подчеркивает, что обращение входной последовательности было ключевой причиной того, что их модель улучшена производительность машинного перевода.
Кодер-декодерВ 2017 г. Vaswani et al. представил Transformer и тем самым дал Рождение модели кодировщика-декодера на базе трансформатора.
Аналогичен моделям кодировщика-декодера на базе RNN, трансформаторный Модели кодировщика-декодера состоят из кодировщика и декодера, которые обе стопки из блока остаточного внимания .Ключевое нововведение трансформаторные модели кодировщика-декодера заключается в том, что такое остаточное внимание блоки могут обрабатывать входную последовательность X1: n \ mathbf {X} _ {1: n} X1: n переменной длина nnn без отображения повторяющейся структуры. Не полагаясь на рекуррентная структура позволяет преобразователям кодировщиков-декодеров быть высокая степень распараллеливания, что делает модель на порядки больше вычислительно эффективен, чем модели кодировщика-декодера на основе RNN на современное оборудование.
Напоминаем, что для решения задачи от последовательности к последовательности нам необходимо найти отображение входной последовательности X1: n \ mathbf {X} _ {1: n} X1: n на выход последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m переменной длины mmm.Посмотрим как модели кодеров-декодеров на базе трансформаторов используются для поиска такого отображение.
Подобно моделям кодировщика-декодера на основе RNN, трансформатор на основе модели кодировщика-декодера определяют условное распределение целевых векторы Y1: n \ mathbf {Y} _ {1: n} Y1: n с заданной входной последовательностью X1: n \ mathbf {X} _ {1: n} X1: n:
pθenc, θdec (Y1: m∣X1: n). p _ {\ theta _ {\ text {enc}}, \ theta _ {\ text {dec}}} (\ mathbf {Y} _ {1: m} | \ mathbf {X} _ {1: n}). pθenc, θdec (Y1: m ∣X1: n).
Кодер на основе трансформатора кодирует входную последовательность X1: n \ mathbf {X} _ {1: n} X1: n в последовательность из скрытых состояний X‾1: n \ mathbf {\ overline { X}} _ {1: n} X1: n, таким образом определяя отображение:
fθenc: X1: n → X‾1: n.f _ {\ theta _ {\ text {enc}}}: \ mathbf {X} _ {1: n} \ to \ mathbf {\ overline {X}} _ {1: n}. fθenc: X1: n → X1: n.
Затем часть декодера на основе трансформатора моделирует условное распределение вероятностей последовательности целевых векторов Y1: n \ mathbf {Y} _ {1: n} Y1: n с учетом последовательности закодированных скрытых состояний X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n:
pθdec (Y1: n∣X‾1: n). p _ {\ theta_ {dec}} (\ mathbf {Y} _ {1: n} | \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: n ∣X1: n ).
По правилу Байеса это распределение можно разложить на множители условное распределение вероятностей целевого вектора yi \ mathbf {y} _iyi учитывая закодированные скрытые состояния X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и все предыдущие целевые векторы Y0: i − 1 \ mathbf {Y} _ {0: i-1} Y0: i − 1:
pθdec (Y1: n∣X‾1: n) = ∏i = 1npθdec (yi∣Y0: i − 1, X‾1: n).{n} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: n ∣X1: n) = i = 1∏n pθdec (yi ∣Y0: i − 1, X1: n).
Трансформаторный декодер тем самым отображает последовательность закодированных скрытых указывает X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и все предыдущие целевые векторы Y0: i − 1 \ mathbf {Y} _ {0: i-1} Y0: i − 1 в вектор logit li \ mathbf {l} _ili. Логит вектор li \ mathbf {l} _ili затем обрабатывается операцией softmax для определить условное распределение pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i -1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n), так же, как это делается для декодеров на основе RNN.Однако в отличие от Декодеры на основе RNN, распределение целевого вектора yi \ mathbf {y} _iyi является явно (или напрямую) обусловленным всеми предыдущими целевыми векторами y0,…, yi − 1 \ mathbf {y} _0, \ ldots, \ mathbf {y} _ {i-1} y0,…, yi − 1 Как мы увидим позже деталь. 0-й целевой вектор y0 \ mathbf {y} _0y0 настоящим представлен специальный «начало предложения» BOS \ text {BOS} вектор BOS.
Определив условное распределение pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0 : i-1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n), теперь мы можем авторегрессивно сгенерировать вывод и, таким образом, определить отображение входной последовательности X1: n \ mathbf {X} _ {1: n} X1: n в выходную последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m при выводе.
Давайте визуализируем полный процесс авторегрессивного поколения на базе трансформатора кодировщика-декодера модели.
Трансформаторный энкодер окрашен в зеленый цвет, а Трансформаторный декодер окрашен в красный цвет. Как и в предыдущем разделе, мы показываем, как английское предложение «Я хочу купить машину», представленное как x1 = I \ mathbf {x} _1 = \ text {I} x1 = I, x2 = want \ mathbf {x} _2 = \ text { want} x2 = want, x3 = to \ mathbf {x} _3 = \ text {to} x3 = to, x4 = buy \ mathbf {x} _4 = \ text {buy} x4 = buy, x5 = a \ mathbf {x} _5 = \ text {a} x5 = a, x6 = car \ mathbf {x} _6 = \ text {car} x6 = car и x7 = EOS \ mathbf {x} _7 = \ text {EOS} x7 = EOS переводится на немецкий: «Ich will ein Auto kaufen «определяется как y0 = BOS \ mathbf {y} _0 = \ text {BOS} y0 = BOS, y1 = Ich \ mathbf {y} _1 = \ text {Ich} y1 = Ich, y2 = will \ mathbf {y} _2 = \ text {will} y2 = will, y3 = ein \ mathbf {y} _3 = \ text {ein} y3 = ein, y4 = Auto, y5 = kaufen \ mathbf {y} _4 = \ text {Auto}, \ mathbf {y} _5 = \ text {kaufen} y4 = Auto, y5 = kaufen и y6 = EOS \ mathbf {y} _6 = \ text {EOS} y6 = EOS.
Сначала кодировщик обрабатывает всю входную последовательность X1: 7 \ mathbf {X} _ {1: 7} X1: 7 = «Я хочу купить машину» (представлен светом зеленые векторы) в контекстуализированную кодированную последовательность X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7. Например. x‾4 \ mathbf {\ overline {x}} _ 4×4 определяет кодировка, которая зависит не только от ввода x4 \ mathbf {x} _4x4 = «buy», но и все остальные слова «я», «хочу», «к», «а», «машина» и «EOS», то есть контекст.
Затем входная кодировка X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7 вместе с BOS вектор, i.е. y0 \ mathbf {y} _0y0, подается на декодер. Декодер обрабатывает входные данные X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7 и y0 \ mathbf {y} _0y0, чтобы первый логит l1 \ mathbf {l} _1l1 (показан более темным красным) для определения условное распределение первого целевого вектора y1 \ mathbf {y} _1y1:
pθenc, dec (y∣y0, X1: 7) = pθenc, dec (y∣BOS, я хочу купить автомобиль EOS) = pθdec (y∣BOS, X‾1: 7). p _ {\ theta_ {enc, dec}} (\ mathbf {y} | \ mathbf {y} _0, \ mathbf {X} _ {1: 7}) = p _ {\ theta_ {enc, dec}} (\ mathbf {y} | \ text {BOS}, \ text {Я хочу купить машину EOS}) = p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ mathbf {\ overline { X}} _ {1: 7}).pθenc, dec (y∣y0, X1: 7) = pθenc, dec (y∣BOS, я хочу купить машину EOS) = pθdec (y∣BOS, X1: 7).
Затем выбирается первый целевой вектор y1 \ mathbf {y} _1y1 = Ich \ text {Ich} Ich из распределения (обозначено серыми стрелками) и теперь может быть снова подается на декодер. Теперь декодер обрабатывает как y0 \ mathbf {y} _0y0 = «BOS» и y1 \ mathbf {y} _1y1 = «Ich» для определения условного распределение второго целевого вектора y2 \ mathbf {y} _2y2:
pθdec (y∣BOS Ich, X‾1: 7). p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich}, \ mathbf {\ overline {X}} _ {1: 7}).pθdec (y∣BOS Ich, X1: 7).
Мы можем снова выполнить выборку и создать целевой вектор y2 \ mathbf {y} _2y2 = «буду». Мы продолжаем в авторегрессивном режиме, пока на шаге 6 не появится EOS. вектор выбирается из условного распределения:
EOS∼pθdec (y∣BOS Ich will ein Auto kaufen, X‾1: 7). \ text {EOS} \ sim p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich будет ein Auto kaufen}, \ mathbf {\ overline {X}} _ {1: 7}). EOS∼pθdec (y∣BOS Ich будет ein Auto kaufen, X1: 7).
И так далее в авторегрессивном режиме.
Важно понимать, что энкодер используется только в первом прямой переход к карте X1: n \ mathbf {X} _ {1: n} X1: n в X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n. Начиная со второго прямого прохода, декодер может напрямую использовать ранее рассчитанная кодировка X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n. Для ясности, давайте проиллюстрируем первый и второй прямой проход для нашего пример выше.
Как видно, только на шаге i = 1i = 1i = 1 мы должны кодировать «Я хочу купить автомобиль EOS «на X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7.На шаге i = 2i = 2i = 2 контекстные кодировки «Я хочу купить машину EOS» просто повторно используется декодером.
В 🤗Трансформаторах это авторегрессивное поколение выполняется под капотом.
при вызове метода .generate () . Воспользуемся одним из наших переводов
модели, чтобы увидеть это в действии.
из трансформаторов импортных MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
model = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»).input_ids
output_ids = model.generate (input_ids) [0]
печать (tokenizer.decode (output_ids)) Выход:
Ich will ein Auto kaufen Вызов .generate () многое делает скрытно. Сначала проходит input_ids в кодировщик. Во-вторых, он передает предварительно определенный токен, которым является символ MarianMTModel вместе с закодированными input_ids в декодер.11. Более подробно о том, как работает декодирование с поиском луча, можно
посоветовал прочитать этот блог
сообщение.
В приложение мы включили фрагмент кода, показывающий, как простая Метод генерации может быть реализован «с нуля». Чтобы полностью понять, как авторегрессивное поколение работает под капотом, это Настоятельно рекомендуется прочитать Приложение.
Подводя итог:
- Кодировщик на основе трансформатора определяет отображение от входа последовательность X1: n \ mathbf {X} _ {1: n} X1: n в контекстуализированную последовательность кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n.
- Трансформаторный декодер определяет условное распределение pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n).
- При соответствующем механизме декодирования выходная последовательность Y1: m \ mathbf {Y} _ {1: m} Y1: m может быть автоматически выбран из pθdec (yi∣Y0: i − 1, X‾1: n), ∀i∈ {1,…, m} p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf { Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}), \ forall i \ in \ {1, \ ldots, m \} pθdec (yi ∣ Y0: i − 1, X1: n), ∀i∈ {1,…, m}.
Отлично, теперь, когда мы получили общий обзор того, как на базе трансформатора моделей кодировщика-декодера работают, мы можем глубже погрузиться в
как кодировщик, так и декодер части модели. В частности, мы
увидит, как именно кодировщик использует слой самовнимания
чтобы получить последовательность контекстно-зависимых векторных кодировок и как
Уровни самовнимания позволяют эффективно распараллеливать. Тогда мы будем
подробно объясните, как слой самовнимания работает в декодере
модель и как декодер зависит от выхода кодировщика с перекрестное внимание слоев для определения условного распределения pθdec (yi∣Y0: i − 1, X‾1: n) p _ {\ theta _ {\ text {dec}}} (\ mathbf {y} _i | \ mathbf { Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}) pθdec (yi ∣Y0: i − 1, X1: n).11 В случае "Helsinki-NLP / opus-mt-en-de" декодирование
параметры доступны
здесь,
где мы видим, что модель применяет поиск луча с num_beams = 6 .
Как упоминалось в предыдущем разделе, энкодер на базе трансформатора отображает входную последовательность в контекстуализированную последовательность кодирования:
fθenc: X1: n → X‾1: n. 11.Двунаправленный Слой самовнимания помещает каждый входной вектор x′j, ∀j∈ {1,…, n} \ mathbf {x ‘} _ j, \ forall j \ in \ {1, \ ldots, n \} x′j, ∀j∈ {1,…, n} по отношению ко всем входные векторы x′1,…, x′n \ mathbf {x ‘} _ 1, \ ldots, \ mathbf {x’} _ nx′1,…, x′n и тем самым преобразует входной вектор x′j \ mathbf {x ‘} _ jx′j в более «изысканный» контекстное представление самого себя, определяемое как x′′j \ mathbf {x »} _ jx′′j. Таким образом, первый блок кодера преобразует каждый входной вектор входная последовательность X1: n \ mathbf {X} _ {1: n} X1: n (показана светло-зеленым цветом ниже) из контекстно-независимое представление вектора в контекстно-зависимое векторное представление, и следующие блоки кодировщика дополнительно уточняют это контекстное представление до тех пор, пока последний блок кодера не выдаст окончательное контекстное кодирование X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n (показано более темным зеленый внизу).22.
Наш примерный энкодер на базе трансформатора состоит из трех энкодеров. блоков, тогда как второй блок кодировщика показан более подробно в красный прямоугольник справа для первых трех входных векторов x1, x2andx3 \ mathbf {x} _1, \ mathbf {x} _2 и \ mathbf {x} _3x1, x2 иx3. Двунаправленный Механизм самовнимания проиллюстрирован полносвязным графом в показаны нижняя часть красного поля и два слоя прямой связи. в верхней части красного квадрата.Как было сказано ранее, мы сосредоточимся только на о механизме двунаправленного самовнимания.
Как видно, каждый выходной вектор слоя самовнимания x′′i, ∀i∈ {1,…, 7} \ mathbf {x »} _ i, \ forall i \ in \ {1, \ ldots, 7 \} x′′i, ∀i∈ {1,…, 7} зависит напрямую, от все входных вектора x′1,…, x′7 \ mathbf {x ‘} _ 1, \ ldots, \ mathbf {x’} _ 7x′1,…, x′7. Это означает, например , что входное векторное представление слова «хочу», то есть x′2 \ mathbf {x ‘} _ 2x′2, находится в прямой связи со словом «купить», и.е. x′4 \ mathbf {x ‘} _ 4x′4, но также со словом «I», то есть x′1 \ mathbf {x’} _ 1x′1. Выходное векторное представление «хочу», , то есть x′′2 \ mathbf {x »} _ 2x′′2, таким образом, представляет более уточненный контекстный представление слова «хочу».
Давайте подробнее рассмотрим, как работает двунаправленное самовнимание. Каждый входной вектор x′i \ mathbf {x ‘} _ ix′i входной последовательности X′1: n \ mathbf {X’} _ {1: n} X′1: n блока кодера проецируется на ключевой вектор ki \ mathbf {k} _iki, вектор значений vi \ mathbf {v} _ivi и вектор запроса qi \ mathbf {q} _iqi (показаны ниже оранжевым, синим и фиолетовым соответственно) с помощью трех обучаемых весовых матриц Wq, Wv, Wk \ mathbf {W} _q, \ mathbf {W} _v, \ mathbf {W} _kWq, Wv, Wk:
qi = Wqx′i, \ mathbf {q} _i = \ mathbf {W} _q \ mathbf {x ‘} _ i, qi = Wq x′i, vi = Wvx′i, \ mathbf {v} _i = \ mathbf {W} _v \ mathbf {x ‘} _ i, vi = Wv x′i, ki = Wkx′i, \ mathbf {k} _i = \ mathbf {W} _k \ mathbf {x ‘} _ i, ki = Wk x′i, ∀i∈ {1,… n}.\ forall i \ in \ {1, \ ldots n \}. ∀i∈ {1,… n}.
Обратите внимание, что одинаковых весовых матриц применяются к каждому входному вектору xi, ∀i∈ {i,…, n} \ mathbf {x} _i, \ forall i \ in \ {i, \ ldots, n \} xi, ∀i∈ {i,…, n}. После проецирования каждого входной вектор xi \ mathbf {x} _ixi для запроса, ключа и вектора значений, каждый вектор запроса qj, ∀j∈ {1,…, n} \ mathbf {q} _j, \ forall j \ in \ {1, \ ldots, n \} qj, ∀j∈ {1,…, n} равен в сравнении ко всем ключевым векторам k1,…, kn \ mathbf {k} _1, \ ldots, \ mathbf {k} _nk1,…, kn. Чем больше похожий один из ключевых векторов k1,… kn \ mathbf {k} _1, \ ldots \ mathbf {k} _nk1,… kn должен вектор запроса qj \ mathbf {q} _jqj, тем важнее соответствующий вектор значений vj \ mathbf {v} _jvj для выходного вектора x′′j \ mathbf {x »} _ jx′′j.\ intercal \ mathbf {q} _j) Softmax (K1: n⊺ qj) как показано в уравнении ниже. Для полного описания слой самовнимания, читателю рекомендуется взглянуть на это сообщение в блоге или исходная бумага.
Хорошо, это звучит довольно сложно. Проиллюстрируем
двунаправленный слой самовнимания для одного из векторов запросов нашего
пример выше. Для простоты предполагается, что наш примерный
Декодер на базе трансформатора использует только одну концентрирующую головку конфиг.num_heads = 1 и что нормализация не применяется.
Слева показан ранее проиллюстрированный второй блок кодера. снова и справа, детальная визуализация двунаправленного Механизм самовнимания дан для второго входного вектора x′2 \ mathbf {x ‘} _ 2x′2, который соответствует входному слову «хочу». Сначала проецируются все входные векторы x′1,…, x′7 \ mathbf {x ‘} _ 1, \ ldots, \ mathbf {x’} _ 7x′1,…, x′7 к соответствующим векторам запросов q1,…, q7 \ mathbf {q} _1, \ ldots, \ mathbf {q} _7q1,…, q7 (вверху фиолетовым цветом показаны только первые три вектора запроса), значение векторы v1,…, v7 \ mathbf {v} _1, \ ldots, \ mathbf {v} _7v1,…, v7 (показаны синим) и ключ векторы k1,…, k7 \ mathbf {k} _1, \ ldots, \ mathbf {k} _7k1,…, k7 (показаны оранжевым).{\ intercal} K1: 7⊺ и q2 \ mathbf {q} _2q2, таким образом, делает его можно сравнить векторное представление «хочу» со всеми другими входные векторные представления «Я», «К», «Купить», «А», «Автомобиль», «EOS», чтобы веса самовнимания отражали важность каждого из другие входные векторные представления x′j, с j ≠ 2 \ mathbf {x ‘} _ j \ text {, с} j \ ne 2x′j, с j = 2 для уточненного представления x′′2 \ mathbf { x »} _ 2x′′2 слова «хочу».
Чтобы лучше понять значение двунаправленного слой самовнимания, предположим, что следующее предложение обрабатывается: « Красивый дом удачно расположен в центре города. где до него легко добраться на общественном транспорте ».Слово «это» относится к «дому», который находится на расстоянии 12 «позиций». В энкодеры на основе трансформатора, двунаправленный слой самовнимания выполняет одну математическую операцию, чтобы поместить входной вектор «дом» во взаимосвязи с входным вектором «оно» (сравните с первая иллюстрация этого раздела). Напротив, в RNN на основе кодировщик, слово, которое находится на расстоянии 12 «позиций», потребует не менее 12 математические операции, означающие, что в кодировщике на основе RNN линейный количество математических операций не требуется.Это делает его много кодировщику на основе RNN сложнее моделировать контекстные представления. Также становится ясно, что энкодер на основе трансформатора гораздо менее склонен к потере важной информации, чем основанный на RNN модель кодировщика-декодера, поскольку длина последовательности кодирования равна оставил то же самое, , т.е. len (X1: n) = len (X‾1: n) = n \ textbf {len} (\ mathbf {X} _ {1: n}) = \ textbf {len} (\ mathbf {\ overline {X}} _ {1: n}) = nlen (X1: n) = len (X1: n) = n, в то время как RNN сжимает длину из ∗ len ((X1: n) = n * \ textbf {len} ((\ mathbf {X} _ {1: n}) = n ∗ len ((X1: n) = n просто len (c) = 1 \ textbf {len} (\ mathbf {c}) = 1len (c) = 1, что очень затрудняет работу RNN для эффективного кодирования дальнодействующих зависимостей между входными словами.\ intercal \ mathbf {K} _ {1: n}) + \ mathbf {X ‘} _ {1: n}. X′′1: n = V1: n Softmax (Q1: n⊺ K1: n) + X′1: n.
Выходные данные X′′1: n = x′′1,…, x′′n \ mathbf {X »} _ {1: n} = \ mathbf {x »} _ 1, \ ldots, \ mathbf { x »} _ nX′′1: n = x′′1,…, x′′n вычисляется с помощью серии умножений матриц и softmax операция, которую можно эффективно распараллелить. Обратите внимание, что в Модель кодировщика на основе RNN, вычисление скрытого состояния c \ mathbf {c} c должно выполняться последовательно: вычисление скрытого состояния первый входной вектор x1 \ mathbf {x} _1x1, затем вычислить скрытое состояние второй входной вектор, который зависит от скрытого состояния первого скрытого вектор и др.Последовательный характер RNN не позволяет эффективно распараллеливание и делает их более неэффективными по сравнению с модели кодировщиков на базе трансформаторов на современном оборудовании GPU.
Отлично, теперь мы должны лучше понять а) как модели кодировщиков на основе трансформаторов эффективно моделируют контекстные представления и б) как они эффективно обрабатывают длинные последовательности входные векторы.
Теперь давайте напишем небольшой пример кодирующей части нашего MarianMT модели кодировщика-декодера для проверки того, что объясненная теория
выполняется на практике.11 Подробное объяснение роли слоев прямой связи
в трансформаторных моделях выходит за рамки этого ноутбука. это
утверждал в Yun et. al, (2017)
что уровни прямой связи имеют решающее значение для сопоставления каждого контекстного вектора x′i \ mathbf {x ‘} _ ix′i индивидуально с желаемым выходным пространством, которое самовнимание слой самостоятельно не справляется. Должен быть
здесь отмечено, что каждый выходной токен x ′ \ mathbf {x ‘} x ′ обрабатывается
тот же слой прямой связи. Подробнее читателю рекомендуется прочитать
бумага.22 Однако входной вектор EOS необязательно добавлять к
входная последовательность, но, как было показано, во многих случаях улучшает производительность.
В отличие от 0-й BOS \ text {BOS} целевой вектор BOS
декодер на основе трансформатора требуется как начальный входной вектор для
предсказать первый целевой вектор.
из трансформаторов импортных MarianMTModel, MarianTokenizer
импортный фонарик
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
модель = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
вложения = модель.get_input_embeddings ()
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»). input_ids
encoder_hidden_states = model.base_model.encoder (input_ids, return_dict = True) .last_hidden_state
input_ids_perturbed = tokenizer («Я хочу купить дом», return_tensors = «pt»). input_ids
encoder_hidden_states_perturbed = model.base_model.encoder (input_ids_perturbed, return_dict = True) .last_hidden_state
print (f "Длина вложений ввода {вложений (input_ids).форма [1]}. Длина encoder_hidden_states {encoder_hidden_states.shape [1]} ")
print ("Кодировка для` I` равна его возмущенной версии ?: ", torch.allclose (encoder_hidden_states [0, 0], encoder_hidden_states_perturbed [0, 0], atol = 1e-3)) Выходы:
Длина вложений ввода 7. Длина encoder_hidden_states 7
Кодировка для `I` равна его возмущенной версии ?: False Сравниваем длину вложений входного слова, i.е. вложений (input_ids) , соответствующие X1: n \ mathbf {X} _ {1: n} X1: n, с
длина encoder_hidden_states , соответствующая X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n. Кроме того, мы перенаправили последовательность слов
«Хочу купить машину» и слегка возмущенный вариант «Хочу
купить дом «через кодировщик, чтобы проверить, есть ли первая выходная кодировка,
соответствует «I», отличается, когда в
входная последовательность.
Как и ожидалось, выходная длина вложений входного слова и кодировщика выходные кодировки, i.е. len (X1: n) \ textbf {len} (\ mathbf {X} _ {1: n}) len (X1: n) и len (X‾1: n) \ textbf {len} (\ mathbf { \ overline {X}} _ {1: n}) len (X1: n), равно. Во-вторых, это может быть отметил, что значения закодированного выходного вектора x‾1 = «I» \ mathbf {\ overline {x}} _ 1 = \ text {«I»} x1 = «I» отличаются, когда последнее слово меняется с «автомобиль» на «дом». Однако это не должно вызывать сюрприз, если кто-то понял двунаправленное самовнимание.
Кстати, модели с автокодированием , такие как BERT, имеют точно такие же Архитектура на базе трансформатора модели кодировщика . Автокодирование модели используют эту архитектуру для массового самоконтроля предварительное обучение текстовых данных в открытом домене, чтобы они могли сопоставить любое слово последовательность к глубокому двунаправленному представлению. В Devlin et al. (2018) авторы показывают, что предварительно обученная модель BERT с одним классификационным слоем для конкретной задачи сверху может достичь результатов SOTA по одиннадцати задачам НЛП. Все автокодирование модели 🤗Трансформаторов можно найти здесь.
ДекодерКак упоминалось в разделе Кодер-декодер , преобразователь на основе преобразователя декодер определяет условное распределение вероятностей цели последовательность с учетом контекстуализированной кодирующей последовательности:
pθdec (Y1: m∣X‾1: n), p _ {\ theta_ {dec}} (\ mathbf {Y} _ {1: m} | \ mathbf {\ overline {X}} _ {1: n} ), pθdec (Y1: m ∣X1: n),
, который по правилу Байеса может быть разложен на продукт условного распределения следующего целевого вектора с учетом контекстуализированного кодирующая последовательность и все предыдущие целевые векторы:
pθdec (Y1: m∣X‾1: n) = ∏i = 1mpθdec (yi∣Y0: i − 1, X‾1: n).{m} p _ {\ theta_ {dec}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: m ∣X1: n) = i = 1∏m pθdec (yi ∣Y0: i − 1, X1: n).
Давайте сначала разберемся, как декодер на основе трансформатора определяет распределение вероятностей. Трансформаторный декодер представляет собой набор блоки декодера , за которыми следует плотный слой, «голова LM». Стек блоков декодера сопоставляет контекстуализированную последовательность кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и последовательность целевого вектора с добавлением вектор BOS \ text {BOS} BOS и переход к последнему целевому вектору i.е. Y0: i − 1 \ mathbf {Y} _ {0: i-1} Y0: i − 1, в закодированную последовательность целевых векторов Y‾0: i − 1 \ mathbf {\ overline {Y}} _ {0: i-1} Y0: i-1. Затем «голова LM» отображает закодированные последовательность целевых векторов Y‾0: i − 1 \ mathbf {\ overline {Y}} _ {0: i-1} Y0: i − 1 до a последовательность логит-векторов L1: n = l1,…, ln \ mathbf {L} _ {1: n} = \ mathbf {l} _1, \ ldots, \ mathbf {l} _nL1: n = l1,…, ln, тогда как размерность каждого логит-вектора li \ mathbf {l} _ili соответствует размер словарного запаса. Таким образом, для каждого i∈ {1,…, n} i \ in \ {1, \ ldots, n \} i∈ {1,…, n} a распределение вероятностей по всему словарю может быть получено с помощью применение операции softmax к li \ mathbf {l} _ili. {\ intercal} \ mathbf {\ overline {y}} _ {i-1 }) = Softmax (Wemb⊺ y i − 1) = Softmax (li).= \ text {Softmax} (\ mathbf {l} _i). = Softmax (li).
Собираем все вместе, чтобы смоделировать условное распределение последовательности целевых векторов Y1: m \ mathbf {Y} _ {1: m} Y1: m, целевые векторы Y1: m − 1 \ mathbf {Y} _ {1: m-1} Y1: m − 1 Предваряется специальным вектором BOS \ text {BOS} BOS, , то есть y0 \ mathbf {y} _0y0, сначала отображаются вместе с контекстуализированными кодирующая последовательность X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n в вектор логита последовательность L1: m \ mathbf {L} _ {1: m} L1: m. Следовательно, каждый целевой вектор логита li \ mathbf {l} _ili преобразуется в условную вероятность распределение целевого вектора yi \ mathbf {y} _iyi с использованием softmax операция.{m} p _ {\ theta_ {dec}} (\ mathbf {y} _i | \ mathbf {Y} _ {0: i-1}, \ mathbf {\ overline {X}} _ {1: n}). pθdec (Y1: m ∣X1: n) = i = 1∏m pθdec (yi ∣Y0: i − 1, X1: n).
В отличие от трансформаторных энкодеров, в трансформаторных декодеры, закодированный выходной вектор y‾i \ mathbf {\ overline {y}} _ iy i должен быть хорошее представление следующего целевого вектора yi + 1 \ mathbf {y} _ {i + 1} yi + 1 и не самого входного вектора. Кроме того, закодированный выходной вектор y‾i \ mathbf {\ overline {y}} _ iy i должен быть обусловлен всеми контекстными кодирующая последовательность X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n.22. Слой однонаправленного самовнимания. ставит каждый из своих входных векторов y′j \ mathbf {y ‘} _ jy′j только во взаимосвязь с все предыдущие входные векторы y′i, с i≤j \ mathbf {y ‘} _ i, \ text {with} i \ le jy′i, с i≤j для все j∈ {1,…, n} j \ in \ {1, \ ldots, n \} j∈ {1,…, n} для моделирования распределения вероятностей следующие целевые векторы. Слой перекрестного внимания помещает каждый из входные векторы y′′j \ mathbf {y »} _ jy′′j во взаимосвязи со всеми контекстуализированными кодирующие векторы X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n, чтобы обусловить распределение вероятностей следующих целевых векторов на входе кодировщик тоже.
Хорошо, давайте визуализируем декодер на основе трансформатора для нашего Пример перевода с английского на немецкий.
Мы видим, что декодер отображает вход Y0: 5 \ mathbf {Y} _ {0: 5} Y0: 5 «BOS», «Ich», «will», «ein», «Auto», «kaufen» (показаны светло-красным) вместе с контекстуализированной последовательностью «я», «хочу», «к», «купить», «а», «автомобиль», «EOS», т.е. X‾1: 7 \ mathbf {\ overline {X}} _ {1: 7} X1: 7 (показано темно-зеленым) в векторы логита L1: 6 \ mathbf {L} _ {1: 6} L1: 6 (показано на темно-красный).
Применение операции softmax к каждому l1, l2,…, l5 \ mathbf {l} _1, \ mathbf {l} _2, \ ldots, \ mathbf {l} _5l1, l2,…, l5 может таким образом определить условные распределения вероятностей:
pθdec (y∣BOS, X‾1: 7), p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS}, \ mathbf {\ overline {X}} _ {1: 7} ), pθdec (y∣BOS, X1: 7), pθdec (y∣BOS Ich, X‾1: 7), p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich}, \ mathbf {\ overline {X}} _ {1: 7 }), pθdec (y∣BOS Ich, X1: 7), …, \ Ldots,…, pθdec (y∣BOS Ich будет ein Auto kaufen, X‾1: 7). p _ {\ theta_ {dec}} (\ mathbf {y} | \ text {BOS Ich будет ein Auto kaufen}, \ mathbf {\ overline {X}} _ {1: 7}).pθdec (y∣BOS Ich будет ein Auto kaufen, X1: 7).
Общая условная вероятность:
pθdec (Ich будет ein Auto kaufen EOS∣X‾1: n) p _ {\ theta_ {dec}} (\ text {Ich будет ein Auto kaufen EOS} | \ mathbf {\ overline {X}} _ {1: n }) pθdec (Ich будет ein Auto kaufen EOS∣X1: n)
Следовательно,может быть вычислено как следующее произведение:
pθdec (Ich∣BOS, X‾1: 7) ×… × pθdec (EOS∣BOS Ich будет ein Auto kaufen, X‾1: 7). p _ {\ theta_ {dec}} (\ text {Ich} | \ text {BOS}, \ mathbf {\ overline {X}} _ {1: 7}) \ times \ ldots \ times p _ {\ theta_ {dec} } (\ text {EOS} | \ text {BOS Ich будет ein Auto kaufen}, \ mathbf {\ overline {X}} _ {1: 7}).pθdec (Ich∣BOS, X1: 7) ×… × pθdec (EOS∣BOS Ich будет использовать Auto kaufen, X1: 7).
В красном поле справа показан блок декодера для первых трех целевые векторы y0, y1, y2 \ mathbf {y} _0, \ mathbf {y} _1, \ mathbf {y} _2y0, y1, y2. В нижнем части, механизм однонаправленного самовнимания проиллюстрирован и в в центре проиллюстрирован механизм перекрестного внимания. Давай сначала сосредоточьтесь на однонаправленном самовнимании.
Как при двунаправленном самовнимании, при однонаправленном самовнимании, векторы запросов q0,…, qm − 1 \ mathbf {q} _0, \ ldots, \ mathbf {q} _ {m-1} q0,…, qm − 1 (показаны на фиолетовый внизу), ключевые векторы k0,…, km − 1 \ mathbf {k} _0, \ ldots, \ mathbf {k} _ {m-1} k0,…, km − 1 (показаны оранжевым ниже), и векторы значений v0,…, vm − 1 \ mathbf {v} _0, \ ldots, \ mathbf {v} _ {m-1} v0,…, vm − 1 (показаны на синий ниже) проецируются из соответствующих входных векторов y′0,…, y′m − 1 \ mathbf {y ‘} _ 0, \ ldots, \ mathbf {y’} _ {m-1} y′0,…, y′m −1 (показано светло-красным цветом ниже).Однако при однонаправленном самовнимании каждый вектор запроса qi \ mathbf {q} _iqi сравнивается только с его соответствующим ключевым вектором и все предыдущие, а именно k0,…, ki \ mathbf {k} _0, \ ldots, \ mathbf {k} _ik0,…, ki, чтобы получить соответствующие веса внимания . Это предотвращает включение любой информации в выходной вектор y′′j \ mathbf {y »} _ jy′′j (показан темно-красным цветом ниже) о следующем входном векторе yi, с i> j \ mathbf {y} _i, \ text {с} i> jyi, с i> j для все j∈ {0,…, m − 1} j \ in \ {0, \ ldots, m — 1 \} j∈ {0,…, m − 1}.\ intercal \ mathbf {q} _i) + \ mathbf {y ‘} _ i. y′′i = V0: i Softmax (K0: i⊺ qi) + y′i.
Обратите внимание, что диапазон индекса векторов ключей и значений равен 0: i0: i0: i вместо 0: m − 10: m-10: m − 1, который будет диапазоном ключевых векторов в двунаправленное самовнимание.
Давайте проиллюстрируем однонаправленное самовнимание для входного вектора y′1 \ mathbf {y ‘} _ 1y′1 для нашего примера выше.
Как видно, y′′1 \ mathbf {y »} _ 1y′′1 зависит только от y′0 \ mathbf {y ‘} _ 0y′0 и y′1 \ mathbf {y’} _ 1y′1 .Поэтому положим векторное представление слова «Ich», то есть y′1 \ mathbf {y ‘} _ 1y′1 только в отношении самого себя и Целевой вектор «BOS», , т.е. y′0 \ mathbf {y ‘} _ 0y′0, но не с векторное представление слова «воля», т.е. y′2 \ mathbf {y ‘} _ 2y′2.
Итак, почему так важно, чтобы мы использовали однонаправленное самовнимание в декодер вместо двунаправленного самовнимания? Как указано выше, декодер на основе трансформатора определяет отображение из последовательности ввода вектор Y0: m − 1 \ mathbf {Y} _ {0: m-1} Y0: m − 1 в логиты, соответствующие следующим входные векторы декодера, а именно L1: m \ mathbf {L} _ {1: m} L1: m.В нашем примере это означает, например, , что входной вектор y1 \ mathbf {y} _1y1 = «Ich» сопоставлен в вектор логита l2 \ mathbf {l} _2l2, который затем используется для прогнозирования входной вектор y2 \ mathbf {y} _2y2. Таким образом, если y′1 \ mathbf {y ‘} _ 1y′1 будет иметь доступ к следующим входным векторам Y′2: 5 \ mathbf {Y ‘} _ {2: 5} Y′2: 5, декодер будет просто скопируйте векторное представление «воли», то есть y′2 \ mathbf {y ‘} _ 2y′2, чтобы получить его выход y′′1 \ mathbf {y’ ‘} _ 1y′′1. Это было бы перенаправлен на последний уровень, так что закодированный выходной вектор y‾1 \ mathbf {\ overline {y}} _ 1y 1 по существу просто соответствовал бы векторное представление y2 \ mathbf {y} _2y2.
Это явно невыгодно, поскольку декодер на основе трансформатора никогда не учись предсказывать следующее слово, учитывая все предыдущие слова, а просто скопируйте целевой вектор yi \ mathbf {y} _iyi через сеть в y‾i − 1 \ mathbf {\ overline {y}} _ {i-1} y i − 1 для всех i∈ {1,… , m} i \ in \ {1, \ ldots, m \} i∈ {1,…, m}. В чтобы определить условное распределение следующего целевого вектора, распределение не может быть обусловлено следующим целевым вектором. Нет смысла предсказывать yi \ mathbf {y} _iyi из p (y∣Y0: i, X‾) p (\ mathbf {y} | \ mathbf {Y} _ {0: i}, \ mathbf {\ overline {X}}) p (y∣Y0: i, X), поскольку распределение обусловлено целевым вектором, который предполагается модель.Следовательно, однонаправленная архитектура самовнимания позволяет нам определить причинное распределение вероятностей , которое необходимо для эффективного моделирования условного распределения следующих целевой вектор.
Отлично! Теперь мы можем перейти к слою, который соединяет кодировщик и декодер — механизм перекрестного внимания !
Слой перекрестного внимания принимает в качестве входных данных две векторные последовательности: выходы однонаправленного слоя самовнимания, i.е. Y′′0: m − 1 \ mathbf {Y »} _ {0: m-1} Y′′0: m − 1 и контекстуализированные векторы кодирования X‾1: n \ mathbf {\ overline {X }} _ {1: n} X1: n. Как и в слое самовнимания, запрос векторы q0,…, qm − 1 \ mathbf {q} _0, \ ldots, \ mathbf {q} _ {m-1} q0,…, qm − 1 являются проекциями выходные векторы предыдущего слоя, , то есть Y′′0: m − 1 \ mathbf {Y »} _ {0: m-1} Y′′0: m − 1. Однако векторы ключа и значения k0,…, km − 1 \ mathbf {k} _0, \ ldots, \ mathbf {k} _ {m-1} k0,…, km − 1 и v0,…, vm −1 \ mathbf {v} _0, \ ldots, \ mathbf {v} _ {m-1} v0,…, vm − 1 — проекции контекстуализированные векторы кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n.Имея определены векторы ключа, значения и запроса, вектор запроса qi \ mathbf {q} _iqi затем сравнивается с все ключевых вектора и используется соответствующая оценка для взвешивания соответствующих векторов значений, как и в случае двунаправленное самовнимание, чтобы дать выходной вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i для всех i∈0,…, m − 1i \ in {0, \ ldots , m-1} i∈0,…, m − 1. \ intercal \ mathbf {q} _i) + \ mathbf {y »} _ я.y ′ ′ ′ i = V1: n Softmax (K1: n⊺ qi) + y′′i.
Обратите внимание, что диапазон индекса векторов ключей и значений равен 1: n1: n1: n соответствует количеству контекстуализированных векторов кодирования.
Давайте визуализируем механизм перекрестного внимания Давайте для ввода вектор y′′1 \ mathbf {y »} _ 1y′′1 для нашего примера выше.
Мы видим, что вектор запроса q1 \ mathbf {q} _1q1 (показан фиолетовым цветом) равен получено из y′′1 \ mathbf {y »} _ 1y′′1 (показано красным) и, следовательно, полагается на вектор представление слова «Ич».Вектор запроса q1 \ mathbf {q} _1q1 затем сравнивается с ключевыми векторами k1,…, k7 \ mathbf {k} _1, \ ldots, \ mathbf {k} _7k1,…, k7 (показаны желтым цветом), соответствующими представление контекстного кодирования всех входных векторов кодировщика X1: n \ mathbf {X} _ {1: n} X1: n = «Я хочу купить автомобиль EOS». Это ставит вектор представление «Ich» в прямую связь со всеми входами кодировщика векторов. Наконец, веса внимания умножаются на значение векторы v1,…, v7 \ mathbf {v} _1, \ ldots, \ mathbf {v} _7v1,…, v7 (показаны бирюзой) в вывести в дополнение к входному вектору y′′1 \ mathbf {y »} _ 1y′′1 выходной вектор y ′ ′ ′ 1 \ mathbf {y » ‘} _ 1y ′ ′ ′ 1 (показан темно-красным ).
Итак, интуитивно, что именно здесь происходит? Каждый выходной вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i является взвешенной суммой всех проекций значений входы кодировщика v1,…, v7 \ mathbf {v} _ {1}, \ ldots, \ mathbf {v} _7v1,…, v7 плюс вход вектор y′′i \ mathbf {y »} _ iy′′i ( см. формулу , проиллюстрированную выше). Ключ механизм понимания следующий: в зависимости от того, насколько похож проекция запроса входного вектора декодера qi \ mathbf {q} _iqi на проекция ключа входного вектора кодировщика kj \ mathbf {k} _jkj, тем более важна проекция значения входного вектора кодировщика vj \ mathbf {v} _jvj.Говоря простым языком, это означает, что чем больше «связанных» входное представление декодера относится к входному представлению кодировщика, больше влияет ли входное представление на выход декодера представление.
Круто! Теперь мы можем видеть, как эта архитектура хорошо обрабатывает каждый вывод. вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i на взаимодействии между входом кодировщика векторы X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n и входной вектор y′′i \ mathbf {y »} _ iy′′i. Еще одно важное наблюдение на этом этапе: архитектура полностью не зависит от количества nnn контекстуализированные векторы кодирования X‾1: n \ mathbf {\ overline {X}} _ {1: n} X1: n, на которых выходной вектор y ′ ′ ′ i \ mathbf {y » ‘} _ iy ′ ′ ′ i обусловлен.{\ text {cross}} _ {v} Wvcross для получения ключевых векторов k1,…, kn \ mathbf {k} _1, \ ldots, \ mathbf {k} _nk1,…, kn и векторов значений v1 ,…, Vn \ mathbf {v} _1, \ ldots, \ mathbf {v} _nv1,…, vn соответственно используются всеми позиции 1,…, n1, \ ldots, n1,…, n и все векторы значений v1,…, vn \ mathbf {v} _1, \ ldots, \ mathbf {v} _n v1,…, vn суммируются к единственному взвешенный усредненный вектор. Теперь также становится очевидным, почему декодер на базе трансформатора не страдает зависимостью от дальнего действия Проблема, от которой страдает декодер на основе RNN.Потому что каждый декодер логит вектор напрямую зависит от каждого отдельного закодированного выходного вектора, количество математических операций для сравнения первого закодированного выходной вектор и последний логит-вектор декодера составляют по существу только один.
В заключение, однонаправленный слой самовнимания отвечает за согласование каждого выходного вектора со всеми предыдущими входными векторами декодера а текущий вектор ввода и слой перекрестного внимания — отвечает за дальнейшее кондиционирование каждого выходного вектора на всех закодированных входных данных векторов.22 Опять же, подробное объяснение роли прямого игра слоев в моделях на основе трансформатора выходит за рамки этого ноутбук. Это утверждается в Yun et. аль, (2017), что слои с прямой связью имеют решающее значение для сопоставления каждого контекстного вектора x′i \ mathbf {x ‘} _ ix′i индивидуально в желаемое пространство вывода, которое слой с самовниманием не может справиться самостоятельно. Здесь следует отметить, что каждый выходной токен x ‘\ mathbf {x’} x ‘обрабатывается одним и тем же уровнем прямой связи. Для большего Подробности, читателю рекомендуется прочитать статью.
из трансформаторов импортных MarianMTModel, MarianTokenizer
импортный фонарик
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
model = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
вложения = модель.get_input_embeddings ()
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»). input_ids
decoder_input_ids = tokenizer (" Ich will ein", return_tensors = "pt", add_special_tokens = False) .input_ids
decoder_output_vectors = модель.base_model.decoder (decoder_input_ids) .last_hidden_state
lm_logits = torch.nn.functional.linear (decoder_output_vectors, embeddings.weight, bias = model.final_logits_bias)
decoder_input_ids_perturbed = tokenizer (" Ich will das", return_tensors = "pt", add_special_tokens = False) .input_ids
decoder_output_vectors_perturbed = model.base_model.decoder (decoder_input_ids_perturbed) .last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear (decoder_output_vectors_perturbed, embeddings.weight, bias = model.final_logits_bias)
print (f "Форма входных векторов декодера {embeddings (decoder_input_ids) .shape}. Форма логитов декодера {lm_logits.shape}")
print ("Кодировка для` Ich` равна его измененной версии ?: ", torch.allclose (lm_logits [0, 0], lm_logits_perturbed [0, 0], atol = 1e-3)) Выход:
Форма входных векторов декодера torch.Size ([1, 5, 512]). Форма декодера logits torch.Size ([1, 5, 58101])
Кодировка Ich равна его измененной версии ?: True Мы сравниваем выходную форму вложений входных слов декодера, i.е. вложений (decoder_input_ids) (соответствует Y0: 4 \ mathbf {Y} _ {0: 4} Y0: 4,
здесь соответствует BOS, а «Ich will das» токенизируется до 4
токены) с размерностью lm_logits (соответствует L1: 5 \ mathbf {L} _ {1: 5} L1: 5). Также мы передали последовательность слов
« {= html} Ich will das» и слегка измененная версия
« {= html} Ich will das» вместе с encoder_output_vectors через кодировщик, чтобы проверить, есть ли второй lm_logit , соответствующий «Ich», отличается, когда только последнее слово
изменено во входной последовательности («ein» -> «das»).
Как и ожидалось, выходные формы вложений входных слов декодера и
lm_logits, то есть размерность Y0: 4 \ mathbf {Y} _ {0: 4} Y0: 4 и L1: 5 \ mathbf {L} _ {1: 5} L1: 5 в последнем измерение. В то время как
длина последовательности такая же (= 5), размерность входа декодера
вложение слов соответствует model.config.hidden_size , тогда как
размерность lm_logit соответствует размеру словаря model.config.vocab_size , как описано выше.Во-вторых, можно отметить
что значения закодированного выходного вектора l1 = «Ich» \ mathbf {l} _1 = \ text {«Ich»} l1 = «Ich» совпадают при изменении последнего слова
от «эйн» до «дас». Однако это не должно вызывать удивления, если
человек понял однонаправленное самовнимание.
В заключение отметим, что модели с авторегрессией , такие как GPT2, имеют та же архитектура, что и на базе трансформатора модели декодера , если один удаляет слой перекрестного внимания, потому что автономный авторегрессивный модели не привязаны к каким-либо выходам энкодера.Так авторегрессивный модели по сути такие же, как модели с автокодированием , но заменяют двунаправленное внимание с однонаправленным вниманием. Эти модели также можно предварительно обучить работе с массивными текстовыми данными в открытом домене, чтобы показывать впечатляющая производительность в задачах генерации естественного языка (NLG). В Radford et al. (2019), авторы показывают, что предварительно обученная модель GPT2 может достичь SOTA или закрыть к результатам SOTA по разнообразным задачам NLG без особой настройки. Все авторегрессивных моделей 🤗Трансформаторов можно найти здесь.
Хорошо, вот и все! Теперь вы должны хорошо понимать на базе трансформатора модели кодировщика-декодера и как их использовать с 🤗Библиотека трансформеров.
Большое спасибо Виктору Саню, Саше Рашу, Сэму Шлейферу, Оливеру Остранду, Теду Московицу и Кристиану Кивику за ценные отзывы.
Приложение Как упоминалось выше, следующий фрагмент кода показывает, как можно программировать
простой метод генерации кодера-декодера на базе трансформатора модели.Здесь мы реализуем простой жадный метод декодирования , используя torch.argmax для выборки целевого вектора.
из трансформаторов импортных MarianMTModel, MarianTokenizer
импортный фонарик
tokenizer = MarianTokenizer.from_pretrained («Хельсинки-НЛП / opus-mt-en-de»)
model = MarianMTModel.from_pretrained ("Хельсинки-НЛП / opus-mt-en-de")
input_ids = tokenizer («Я хочу купить машину», return_tensors = «pt»). input_ids
decoder_input_ids = tokenizer ("", add_special_tokens = False, return_tensors = "pt").input_ids
assert decoder_input_ids [0, 0] .item () == model.config.decoder_start_token_id, "` decoder_input_ids` должен соответствовать `model.config.decoder_start_token_id`"
output = model (input_ids, decoder_input_ids = decoder_input_ids, return_dict = True)
encoded_sequence = (outputs.encoder_last_hidden_state,)
lm_logits = outputs.logits
next_decoder_input_ids = torch.argmax (lm_logits [:, -1:], ось = -1)
decoder_input_ids = torch.cat ([decoder_input_ids, next_decoder_input_ids], axis = -1)
lm_logits = модель (Нет, encoder_outputs = encoded_sequence, decoder_input_ids = decoder_input_ids, return_dict = True).логиты
next_decoder_input_ids = torch.argmax (lm_logits [:, -1:], ось = -1)
decoder_input_ids = torch.cat ([decoder_input_ids, next_decoder_input_ids], axis = -1)
lm_logits = модель (Нет, encoder_outputs = encoded_sequence, decoder_input_ids = decoder_input_ids, return_dict = True) .logits
next_decoder_input_ids = torch.argmax (lm_logits [:, -1:], ось = -1)
decoder_input_ids = torch.cat ([decoder_input_ids, next_decoder_input_ids], axis = -1)
print (f "Создано на данный момент: {tokenizer.decode (decoder_input_ids [0], skip_special_tokens = True)}")
Выходы:
На данный момент создано: Ich Ich В этом примере кода мы показываем именно то, что было описано ранее.Мы
передайте ввод «Я хочу купить машину» вместе с BOS \ text {BOS} BOS
токен модели кодировщика-декодера и выборка из первого логита l1 \ mathbf {l} _1l1 (, т.е. первая строка lm_logits ). Настоящим наша выборка
стратегия проста — жадно выбрать следующий входной вектор декодера, который
имеет наибольшую вероятность. Затем авторегрессивным образом мы передаем
выбранный входной вектор декодера вместе с предыдущими входами для
модель кодера-декодера и снова образец.Повторяем это в третий раз.
В результате модель сгенерировала слова «Ич Ич». Первый
слово точное! Второе слово не очень хорошее. Мы можем видеть здесь,
что хороший метод декодирования является ключом к успешной генерации последовательности
из заданного модельного распределения.
На практике используются более сложные методы декодирования для выборки lm_logits . Большинство из них покрыто
это сообщение в блоге.
Иллюстрированное руководство по трансформаторам — пошаговое объяснение | Майкл Фи
Трансформаторы штурмом захватывают мир обработки естественного языка.Эти невероятные модели бьют множество рекордов НЛП и продвигают новейшие разработки. Они используются во многих приложениях, таких как машинный перевод, разговорные чат-боты и даже для улучшения поисковых систем. Трансформаторы сейчас в моде в глубоком обучении, но как они работают? Почему они превзошли предыдущего короля проблем последовательности, такого как рекуррентные нейронные сети, GRU и LSTM? Вы, наверное, слышали о различных известных моделях трансформеров, таких как BERT, GPT и GPT2.В этом посте мы сосредоточимся на одной статье, с которой все началось: «Внимание — это все, что вам нужно».
Перейдите по ссылке ниже, если вы хотите вместо этого посмотреть видеоверсию.
Чтобы понять трансформаторов, мы сначала должны понять механизм внимания. Механизм внимания позволяет трансформаторам иметь чрезвычайно долгую память. Модель-трансформер может «присутствовать» или «фокусироваться» на всех ранее сгенерированных токенах.
Давайте рассмотрим пример. Допустим, мы хотим написать небольшой научно-фантастический роман с генеративным преобразователем.Мы можем сделать это с помощью приложения Write With Transformer от Hugging Face. Мы заполним модель нашими входными данными, а модель сгенерирует все остальное.
Наш ввод: «Когда пришельцы вошли на нашу планету».
Вывод трансформатора: «и начала колонизацию Земли, определенная группа инопланетян начала манипулировать нашим обществом через свое влияние определенного числа элиты, чтобы удерживать и жестко контролировать население».
Итак, история немного мрачная, но что интересно, так это то, как модель ее сгенерировала.По мере того как модель генерирует текст слово за словом, она может «следить» или «фокусироваться» на словах, которые имеют отношение к сгенерированному слову. Способность знать, какие слова следует посещать, тоже приобретается во время обучения посредством обратного распространения ошибки.
Механизм внимания, фокусирующийся на разных токенах при генерации слов 1 на 1Рекуррентные нейронные сети (RNN) также могут просматривать предыдущие входные данные. Но сила механизма внимания в том, что он не страдает от кратковременной памяти. У RNN более короткое окно для ссылки, поэтому, когда история становится длиннее, RNN не может получить доступ к словам, сгенерированным ранее в последовательности.Это по-прежнему верно для сетей Gated Recurrent Units (GRU) и Long-Short Term Memory (LSTM), хотя они обладают большей емкостью для достижения более долгосрочной памяти, следовательно, имеют более длительное окно для ссылки. Механизм внимания теоретически и при наличии достаточных вычислительных ресурсов имеет бесконечное окно, из которого можно ссылаться, поэтому он может использовать весь контекст истории при генерации текста.
Гипотетическое справочное окно внимания, RNN, ГРУ и LSTMСила механизма внимания была продемонстрирована в статье «Внимание — это все, что вам нужно», где авторы представили новую новую нейронную сеть под названием Трансформеры, которая является кодировщиком на основе внимания. архитектура типа декодера.
Модель преобразователяНа высоком уровне кодировщик преобразует входную последовательность в абстрактное непрерывное представление, которое содержит всю изученную информацию этого входа. Затем декодер принимает это непрерывное представление и шаг за шагом генерирует один вывод, одновременно передавая предыдущий вывод.
Давайте рассмотрим пример. В статье модель Transformer применялась к задаче нейронного машинного перевода. В этом посте мы продемонстрируем, как это работает для разговорного чат-бота.
Наш ввод: «Привет, как дела»
Выход трансформатора: «Я в порядке»
Первым шагом является подача ввода в слой встраивания слов. Слой встраивания слов можно рассматривать как таблицу поиска, чтобы получить изученное векторное представление каждого слова. Нейронные сети обучаются с помощью чисел, поэтому каждое слово отображается в вектор с непрерывными значениями для представления этого слова.
преобразование слов во входные вложенияСледующим шагом является введение позиционной информации во вложения.Поскольку кодировщик-преобразователь не имеет повторения, как рекуррентные нейронные сети, мы должны добавить некоторую информацию о позициях во входные вложения. Это делается с помощью позиционного кодирования. Авторы придумали хитрый трюк, используя функции sin и косинус.
Мы не будем вдаваться в математические подробности позиционного кодирования, но вот основы. Для каждого нечетного индекса входного вектора создайте вектор с помощью функции cos. Для каждого четного индекса создайте вектор с помощью функции sin.Затем добавьте эти векторы к их соответствующим входным вложениям. Это успешно дает сети информацию о положении каждого вектора. Функции sin и косинус были выбраны в тандеме, потому что они обладают линейными свойствами, которым модель может легко научиться уделять внимание.
Теперь у нас есть слой кодировщика. Задача слоев Encoders состоит в том, чтобы отобразить все входные последовательности в абстрактное непрерывное представление, которое содержит изученную информацию для всей этой последовательности. Он содержит 2 подмодуля, многоголовое внимание, за которым следует полностью подключенная сеть.Также существуют остаточные связи вокруг каждого из двух подслоев, за которыми следует нормализация уровня. Подмодули уровня кодировщика
Чтобы разобраться в этом, давайте сначала рассмотрим модуль многоголового внимания.
Многоголовое внимание в кодировщике применяет особый механизм внимания, называемый самовниманием. Самовнимание позволяет моделям связывать каждое слово во входных данных с другими словами. Итак, в нашем примере наша модель может научиться ассоциировать слово «вы» с «как» и «есть».Также возможно, что модель узнает, что слова, структурированные по этому шаблону, обычно являются вопросом, поэтому отвечайте соответствующим образом.
Encoder Self-Attention Operations. Ссылка на это при просмотре иллюстраций ниже.Векторы запросов, ключей и значений
Чтобы добиться самовнимания, мы передаем входные данные в 3 отдельных полностью связанных слоя для создания векторов запроса, ключа и значения.
Что именно это за векторы? Я нашел хорошее объяснение по обмену стеком, в котором говорится….
«Концепция ключа и значения запроса исходит из поисковых систем. Например, когда вы вводите запрос для поиска некоторого видео на Youtube, поисковая система сопоставляет ваш запрос с набором ключей (заголовок видео, описание и т. Д.), Связанных с видео кандидатов в базе данных, а затем представим вам наиболее подходящие видео ( значения ).
Точечное произведение запроса и ключа
После подачи вектора запроса, ключа и значения через линейный слой запросы и ключи подвергаются умножению матрицы скалярного произведения для создания матрицы оценок.
Умножение скалярного произведения запроса и ключаМатрица оценок определяет, насколько большое внимание следует уделять слову другие слова. Таким образом, каждое слово будет иметь оценку, соответствующую другим словам на временном шаге. Чем выше оценка, тем больше внимания. Вот как запросы сопоставляются с ключами.
Оценка внимания от скалярного произведения.Уменьшение оценок внимания
Затем оценки уменьшаются путем деления на квадратный корень из измерения запроса и ключа.Это сделано для обеспечения более стабильных градиентов, так как умножение значений может иметь взрывной эффект.
Уменьшение оценок вниманияSoftmax масштабированных оценок
Затем вы берете softmax масштабированной оценки, чтобы получить веса внимания, что дает вам значения вероятности от 0 до 1. Выполняя softmax, повышаются более высокие оценки, и более низкие баллы подавлены. Это позволяет модели быть более уверенным в том, какие слова следует использовать.
Взятие softmax масштабированных оценок для получения значений вероятностиУмножение выходных данных Softmax на вектор значений
Затем вы берете веса внимания и умножаете их на свой вектор значений, чтобы получить вектор выходных данных.Более высокие баллы softmax сохранят ценность слов, которые модель выучила более важными. Более низкие оценки заглушают неуместные слова. Затем вы передаете результат в линейный слой для обработки.
Чтобы сделать это вычисление многоголового внимания, вам необходимо разделить запрос, ключ и значение на N векторов, прежде чем применять самовнимание. Затем расщепленные векторы индивидуально проходят процесс самовнимания. Каждый процесс самовнимания называется головой. Каждая голова создает выходной вектор, который объединяется в один вектор перед прохождением последнего линейного слоя.Теоретически каждая голова будет изучать что-то свое, что дает модели кодировщика большую репрезентативную способность.
Разделение Q, K, V, N раз перед применением самовниманияПодводя итог, многоголовое внимание — это модуль в трансформаторной сети, который вычисляет веса внимания для входа и создает выходной вектор с закодированной информацией о том, как каждое слово должно соответствовать всем остальным словам в последовательности.
Выходной вектор многоголового внимания добавляется к исходному позиционному встраиванию входных данных.Это называется остаточной связью. Вывод остаточного соединения проходит через нормализацию слоя.
Остаточное соединение позиционного встраивания ввода и вывода многоголового вниманияНормализованный остаточный вывод проецируется через точечную сеть с прямой связью для дальнейшей обработки. Точечная сеть с прямой связью представляет собой пару линейных слоев с активацией ReLU между ними. Выходной сигнал затем снова добавляется к входу точечной сети с прямой связью и далее нормализуется.
Остаточное соединение входа и выхода точечного прямого слоя.Остаточные соединения помогают обучению сети, позволяя градиентам проходить через сети напрямую. Нормализация слоев используется для стабилизации сети, что приводит к существенному сокращению необходимого времени обучения. Слой точечной упреждающей связи используется для проецирования результатов внимания, которые потенциально могут дать более богатое представление.
Это завершает слой кодировщика. Все эти операции предназначены для кодирования входных данных в непрерывное представление с информацией о внимании.Это поможет декодеру сосредоточиться на соответствующих словах во вводе во время процесса декодирования. Вы можете складывать кодер N раз для дальнейшего кодирования информации, при этом каждый уровень имеет возможность изучать различные представления внимания, что потенциально увеличивает предсказательную мощность трансформаторной сети.
Задача декодера — генерировать текстовые последовательности. Декодер имеет такой же подуровень, что и кодер. он имеет два многоголовых слоя внимания, слой с точечной прямой связью и остаточные связи, а также нормализацию уровня после каждого подуровня.Эти подуровни ведут себя аналогично уровням в кодировщике, но каждый многоглавый уровень внимания выполняет свою работу. Декодер завершается линейным слоем, который действует как классификатор, и softmax для получения вероятностей слов.
Слой декодера. Ссылка на эту диаграмму при чтении.Декодер является авторегрессионным, он начинается со стартового токена и принимает список предыдущих выходов в качестве входов, а также выходы кодировщика, которые содержат информацию о внимании из входа.Декодер прекращает декодирование, когда генерирует токен в качестве вывода.
Декодер является авторегрессионным, поскольку он генерирует токен 1 за раз, подавая его на предыдущие выходы.Давайте пройдемся по этапам декодирования.
Начало декодера почти такое же, как и у кодировщика. Входные данные проходят через слой внедрения и слой позиционного кодирования, чтобы получить позиционные вложения. Позиционные вложения вводятся в первый слой внимания с несколькими головами, который вычисляет оценки внимания для входных данных декодера.
Этот многоглавый слой внимания работает несколько иначе. Поскольку декодер является авторегрессионным и генерирует последовательность слово за словом, вам необходимо предотвратить его преобразование в будущие токены. Например, при вычислении оценки внимания к слову «я» у вас не должно быть доступа к слову «отлично», потому что это слово является будущим словом, которое было сгенерировано после. Слово «am» должно иметь доступ только к самому себе и к словам перед ним. Это верно для всех других слов, где они могут относиться только к предыдущим словам.
Изображение первого многоголового внимания декодера по шкале оценки внимания. Слово «am» не должно иметь никаких значений для слова «штраф». Это верно для всех остальных слов.Нам нужен метод, предотвращающий вычисление оценок внимания для будущих слов. Этот метод называется маскировкой. Чтобы декодер не смотрел на будущие токены, вы применяете маску просмотра вперед. Маска добавляется перед вычислением softmax и после масштабирования оценок. Давайте посмотрим, как это работает.
Маска упреждения
Маска — это матрица того же размера, что и оценки внимания, заполненная значениями 0 и отрицательной бесконечностью.Когда вы добавляете маску к масштабированным оценкам внимания, вы получаете матрицу оценок с верхним правым треугольником, заполненным бесконечностями негатива.
Добавление маски упреждающего просмотра к масштабированным оценкамПричина использования маски в том, что как только вы берете softmax замаскированных оценок, отрицательные бесконечности обнуляются, оставляя нулевые оценки внимания для будущих токенов. Как вы можете видеть на рисунке ниже, оценка внимания для «am» имеет значения для себя и всех слов перед ним, но равна нулю для слова «хорошо».По сути, это говорит модели не акцентировать внимание на этих словах.
Эта маскировка — единственное отличие в том, как рассчитываются оценки внимания в первом многоглавом слое внимания. Этот слой по-прежнему имеет несколько головок, к которым применяется маска, прежде чем они будут объединены и пропущены через линейный слой для дальнейшей обработки. Результатом первого многоголового внимания является замаскированный выходной вектор с информацией о том, как модель должна присутствовать на входе декодера.
Многоголовое внимание с маскированиемВторой слой многоголового внимания.Для этого уровня выходными данными кодировщика являются запросы и ключи, а выходными данными первого многоголового слоя внимания являются значения. Этот процесс сопоставляет вход кодера со входом декодера, позволяя декодеру решить, на каком входе кодера следует сосредоточить внимание. Результат второго многоголового внимания проходит через точечный слой прямой связи для дальнейшей обработки.
Выходные данные последнего поточечного слоя с прямой связью проходят через последний линейный слой, который действует как классификатор.Классификатор такой же большой, как и количество ваших классов. Например, если у вас есть 10 000 классов для 10 000 слов, вывод этого классификатора будет иметь размер 10 000. Выходные данные классификатора затем передаются в слой softmax, который дает оценки вероятности от 0 до 1. Мы берем индекс наивысшей оценки вероятности, который равен нашему предсказанному слову.
Линейный классификатор с Softmax для получения вероятностей выводаЗатем декодер берет вывод, добавляет его в список входов декодера и снова продолжает декодирование, пока не будет предсказан токен.В нашем случае предсказание с наивысшей вероятностью — это последний класс, который назначается конечному токену.
Декодер также может быть составлен из N уровней, каждый из которых принимает входные данные от кодера и предшествующих ему слоев. Сложив слои, модель может научиться извлекать и сосредотачиваться на различных комбинациях внимания из своих головок внимания, потенциально повышая ее способность к прогнозированию.
Кодировщик и декодер с накоплениемИ все! Такова механика трансформаторов.Трансформаторы используют силу механизма внимания, чтобы делать более точные прогнозы. Рекуррентные нейронные сети пытаются добиться аналогичных результатов, но потому, что страдают от кратковременной памяти. Трансформаторы могут быть лучше, особенно если вы хотите кодировать или генерировать длинные последовательности. Благодаря архитектуре преобразователя индустрия обработки естественного языка может достичь беспрецедентных результатов.
Посетите michaelphi.com, чтобы найти больше подобного контента.
nlp — повторно использует ли декодер преобразователя промежуточные состояния предыдущих токенов, такие как GPT2?
Насколько я понимаю, трансформаторные декодеры и модели трансформаторных кодеров-декодеров обычно работают так же, как GPT-2, т.е.е., представления в сгенерированной последовательности вычисляются один раз, а затем повторно используются для будущих шагов. Но вы правы в том, что это не единственный способ сделать что-то. Можно пересчитать представления для всех токенов в частично сгенерированной последовательности, используя полное самовнимание над токенами в последовательности, сгенерированной на данный момент (для этого нет математических препятствий — это похоже на запуск типичного кодировщика-преобразователя над последовательностью слова в частично сгенерированной последовательности).
Но, насколько я могу судить по литературе, эти дополнительные вычисления обычно не выполняются. Думаю, есть как минимум две причины. Во-первых, как отмечали другие, с вычислительной точки зрения дешевле использовать ранее вычисленные представления из более ранних временных шагов (хотя это приводит к другим результатам, и я не видел эмпирического сравнения ни в одной статье). Во-вторых, это соответствует тому, как проводится обучение. Во время обучения следствием маскировки при самовнимании является то, что представление в выходной позиции i вычисляется с использованием представлений в выходных позициях <= i.Это означает, что во время обучения вычисляется только одно представление для выходной позиции i для каждого слоя. Это соответствует тому, что происходит во время вывода с использованием стандартного подхода, который мы обсуждали и который используется в GPT-2.
Если бы мы хотели обучить модель, в которой представление для выходной позиции было вычислено на основе всех доступных выходных представлений (конечно, всегда за исключением тех, которые еще не были «сгенерированы»), то нам нужно было бы вычислить несколько представлений для каждая позиция вывода во время обучения, по одной для каждого возможного непокрытого частичного правого контекста.Например, если мы обучаем языковую модель в окнах размером 512, нам нужно будет вычислить (около) 512 представлений для первого слова, которое соответствует потерям для генерации каждого последующего слова в окне. Это привело бы к очень большому графу вычислений и замедлению обучения. Однако он может работать лучше, поскольку приводит к более богатому отображению выходных данных, поэтому, пожалуйста, попробуйте его и дайте нам знать. 🙂
Что такое трансформатор ?. Введение в трансформаторы и… | Максим | Машинное обучение изнутри
Новые модели глубокого обучения внедряются все чаще, и иногда бывает сложно уследить за всеми новинками.Тем не менее, одна конкретная модель нейронной сети оказалась особенно эффективной для общих задач обработки естественного языка. Модель называется Transformer, и в ней используются несколько методов и механизмов, которые я здесь расскажу. Статьи, на которые я ссылаюсь в посте, предлагают более подробное и количественное описание.
В документе «Внимание — это все, что вам нужно» описываются трансформаторы и так называемая архитектура «последовательность-последовательность». Sequence-to-Sequence (или Seq2Seq) — это нейронная сеть, которая преобразует заданную последовательность элементов, например последовательность слов в предложении, в другую последовательность.(Что ж, это может не удивить вас, учитывая название.)
Модели Seq2Seq особенно хороши при переводе, когда последовательность слов одного языка преобразуется в последовательность разных слов на другом языке. Популярным выбором для этого типа моделей являются модели на основе Long-Short-Term-Memory (LSTM). С данными, зависящими от последовательности, модули LSTM могут придавать значение последовательности, запоминая (или забывая) те части, которые он считает важными (или неважными). Например, предложения зависят от последовательности, поскольку порядок слов имеет решающее значение для понимания предложения.LSTM — естественный выбор для этого типа данных.
Модели Seq2Seq состоят из кодировщика и декодера. Кодировщик берет входную последовательность и отображает ее в пространство более высокой размерности (n-мерный вектор). Этот абстрактный вектор подается в декодер, который превращает его в выходную последовательность. Последовательность вывода может быть на другом языке, символах, копии ввода и т. Д.
Представьте себе кодировщик и декодер как переводчиков, говорящих только на двух языках. Их первый язык — их родной язык, который у них обоих разный (e.г. Немецкий и французский) и их второй общий язык — воображаемый. Чтобы перевести немецкий на французский, Encoder преобразует немецкое предложение на другой язык, который он знает, а именно в воображаемый язык. Поскольку декодер может читать этот воображаемый язык, теперь он может переводить с этого языка на французский. Вместе модель (состоящая из кодировщика и декодера) может переводить с немецкого на французский!
Предположим, что изначально ни кодировщик, ни декодер не очень хорошо владеют воображаемым языком.Чтобы научиться этому, мы обучаем их (модель) на множестве примеров.
Самый простой выбор для кодировщика и декодера модели Seq2Seq — это один LSTM для каждого из них.
Вам интересно, когда же Трансформер наконец войдет в игру, не так ли?
Нам нужна еще одна техническая деталь, чтобы упростить понимание трансформаторов: Внимание . Механизм внимания смотрит на входную последовательность и на каждом этапе решает, какие другие части последовательности важны.Это звучит абстрактно, но позвольте мне уточнить простой пример: читая этот текст, вы всегда сосредотачиваетесь на прочитанном слове, но в то же время ваш разум по-прежнему удерживает в памяти важные ключевые слова текста, чтобы обеспечить контекст.
Механизм внимания работает аналогично для данной последовательности. Для нашего примера с человеческим кодировщиком и декодером представьте, что вместо того, чтобы записывать только перевод предложения на воображаемом языке, кодировщик также записывает ключевые слова, которые важны для семантики предложения, и передает их декодеру в дополнение к обычному переводу.Эти новые ключевые слова значительно упрощают перевод для декодера, поскольку он знает, какие части предложения важны и какие ключевые термины задают контекст предложения.
Другими словами, для каждого входа, который считывает LSTM (кодировщик), механизм внимания одновременно учитывает несколько других входов и решает, какие из них важны, присваивая этим входам разные веса. Затем декодер примет на вход закодированное предложение и веса, предоставленные механизмом внимания.Чтобы узнать больше о внимании, прочтите эту статью. А для более научного подхода, чем предложенный, прочтите о различных подходах, основанных на внимании к моделям «последовательность-последовательность», в этой замечательной статье под названием «Эффективные подходы к нейронному машинному переводу на основе внимания».
В статье «Внимание — это все, что вам нужно» представлена новая архитектура под названием Transformer. Как видно из названия, он использует механизм внимания, который мы видели ранее. Как и LSTM, Transformer — это архитектура для преобразования одной последовательности в другую с помощью двух частей (кодировщика и декодера), но она отличается от ранее описанных / существующих моделей последовательностей, поскольку не подразумевает никаких рекуррентных сетей ( ГРУ, LSTM и др.).
Рекуррентные сети до сих пор были одним из лучших способов фиксировать своевременные зависимости в последовательностях. Однако команда, представившая документ, доказала, что архитектура только с механизмами внимания без каких-либо RNN (рекуррентных нейронных сетей) может улучшить результаты в задаче перевода и других задачах! Одно улучшение в задачах естественного языка представлено командой, представляющей BERT: BERT: предварительное обучение глубоких двунаправленных преобразователей для понимания языка.
Итак, что такое трансформатор?
Изображение стоит тысячи слов, поэтому начнем с него!
Рис. 1. Из статьи Vaswani et al.Кодировщик находится слева, а декодер — справа. И кодировщик, и декодер состоят из модулей, которые можно устанавливать друг на друга несколько раз, что описано на рисунке как Nx . Мы видим, что модули состоят в основном из слоев Multi-Head Attention и Feed Forward. Входы и выходы (целевые предложения) сначала встраиваются в n-мерное пространство, поскольку мы не можем использовать строки напрямую.
Одна небольшая, но важная часть модели — позиционное кодирование различных слов.Поскольку у нас нет повторяющихся сетей, которые могут запомнить, как последовательности вводятся в модель, нам нужно каким-то образом присвоить каждому слову / части в нашей последовательности относительное положение, поскольку последовательность зависит от порядка ее элементов. Эти позиции добавляются к встроенному представлению (n-мерному вектору) каждого слова.
Давайте внимательнее рассмотрим эти блоки Multi-Head Attention в модели:
Рисунок 2. Из «Attention Is All You Need» Vaswani et al.Начнем с описания механизма внимания слева.Это не очень сложно и может быть описано следующим уравнением:
Q — матрица, содержащая запрос (векторное представление одного слова в последовательности), K — все ключи (векторные представления всех слов в последовательности) и V — значения, которые снова являются векторными представлениями всех слов в последовательности. Для кодера и декодера, модулей внимания с несколькими головами, V состоит из той же последовательности слов, что и Q. Однако для модуля внимания, который принимает во внимание последовательности кодера и декодера, V отличается от последовательности, представленной Q.
Чтобы немного упростить это, мы могли бы сказать, что значения в V умножаются и суммируются с некоторыми весами внимания a, , где наши веса определяются как:
Это означает, что веса a определяются как как на каждое слово последовательности (представленной Q) влияют все другие слова в последовательности (представленные K). Кроме того, функция SoftMax применяется к весам и , чтобы иметь распределение между 0 и 1. Эти веса затем применяются ко всем словам в последовательности, которые вводятся в V (те же векторы, что и Q для кодера и декодера, но разные для модуля, имеющего входы кодировщика и декодера).
На рисунке справа показано, как этот механизм внимания можно распараллелить на несколько механизмов, которые можно использовать бок о бок. Механизм внимания повторяется несколько раз с линейными проекциями Q, K и V. Это позволяет системе учиться на различных представлениях Q, K и V, что полезно для модели. Эти линейные представления выполняются путем умножения Q, K и V на весовые матрицы W, которые изучаются во время обучения.
Эти матрицы Q, K и V различны для каждой позиции модулей внимания в структуре в зависимости от того, находятся ли они в кодере, декодере или промежуточном кодере и декодере.Причина в том, что мы хотим обработать либо всю входную последовательность кодера, либо часть входной последовательности декодера. Модуль внимания с несколькими головами, который соединяет кодер и декодер, будет следить за тем, чтобы входная последовательность кодера учитывалась вместе с входной последовательностью декодера до заданной позиции.
После головок с множественным вниманием в кодировщике и декодере у нас есть точечный слой прямой связи. Эта небольшая сеть с прямой связью имеет идентичные параметры для каждой позиции, которые можно описать как отдельное идентичное линейное преобразование каждого элемента из данной последовательности.
ОбучениеКак дрессировать такого «зверя»? Обучение и вывод на основе моделей Seq2Seq немного отличается от обычной задачи классификации. То же самое и с Трансформерами.
Мы знаем, что для обучения модели задачам перевода нам нужны два предложения на разных языках, которые являются переводами друг друга. Когда у нас будет много пар предложений, мы можем приступить к обучению нашей модели. Допустим, мы хотим перевести с французского на немецкий. Наш закодированный ввод будет предложением на французском языке, а ввод для декодера будет предложением на немецком языке.Однако вход декодера будет смещен вправо на одну позицию. .. Подождите, а почему?
Одна из причин заключается в том, что мы не хотим, чтобы наша модель училась копировать входные данные декодера во время обучения, но мы хотим узнать, что с учетом последовательности кодера и конкретной последовательности декодера, которая уже была замечена моделью, мы прогнозируем следующее слово / символ.
Если мы не сдвинем последовательность декодера, модель научится просто «копировать» вход декодера, поскольку целевым словом / символом для позиции i будет слово / символ i на входе декодера.Таким образом, сдвигая ввод декодера на одну позицию, наша модель должна предсказать целевое слово / символ для позиции i , увидев только слово / символы 1,…, i-1 в последовательности декодера. Это мешает нашей модели изучить задачу копирования / вставки. Мы заполняем первую позицию ввода декодера токеном начала предложения, поскольку в противном случае это место было бы пустым из-за сдвига вправо. Точно так же мы добавляем маркер конца предложения во входную последовательность декодера, чтобы отметить конец этой последовательности, и он также добавляется к целевому выходному предложению.Через мгновение мы увидим, насколько это полезно для вывода результатов.
Это верно для моделей Seq2Seq и для трансформатора. В дополнение к сдвигу вправо, Трансформатор применяет маску к входу в первом модуле внимания с несколькими головами, чтобы не видеть потенциальных «будущих» элементов последовательности. Это характерно для архитектуры Transformer, потому что у нас нет RNN, в которые мы можем вводить нашу последовательность последовательно. Здесь мы вводим все вместе, и если бы не было маски, внимание с несколькими головками рассматривало бы всю входную последовательность декодера в каждой позиции.
Процесс подачи правильного сдвинутого ввода в декодер также называется принудительной подачей учителя, как описано в этом блоге.
Целевая последовательность, которую мы хотим для наших расчетов потерь, — это просто вход декодера (немецкое предложение) без его сдвига и с маркером конца последовательности в конце.
ВыводВывод с помощью этих моделей отличается от обучения, что имеет смысл, потому что в конце концов мы хотим перевести французское предложение, не имея немецкого предложения.Уловка здесь заключается в том, чтобы повторно загружать нашу модель для каждой позиции выходной последовательности, пока мы не встретим токен конца предложения.
Более пошаговый метод:
- Введите полную последовательность кодировщика (французское предложение), и в качестве входных данных декодера мы берем пустую последовательность только с токеном начала предложения на первой позиции. Это выведет последовательность, в которой мы возьмем только первый элемент.
- Этот элемент будет заполнен во второй позиции нашей входной последовательности декодера, которая теперь имеет маркер начала предложения и первое слово / символ в нем.
- Введите в модель как последовательность кодировщика, так и новую последовательность декодера. Возьмите второй элемент вывода и поместите его во входную последовательность декодера.
- Повторяйте это, пока не найдете маркер конца предложения, который отмечает конец перевода.
Мы видим, что нам нужно несколько прогонов нашей модели для перевода нашего предложения.
Я надеюсь, что эти описания сделали архитектуру Transformer немного понятнее для всех, кто начинает с Seq2Seq и структур кодер-декодер.
Мы видели архитектуру Transformer и знаем из литературы и авторов «Attention is All you Need», что модель очень хорошо справляется с языковыми задачами. Давайте теперь протестируем Transformer на примере использования.
Вместо задачи перевода давайте реализуем прогноз временных рядов для почасового потока электроэнергии в Техасе, предоставленный Советом по надежности электроснабжения Техаса (ERCOT). Здесь вы можете найти почасовые данные.
Прекрасное подробное объяснение трансформатора и его реализации предоставлено harvardnlp.Если вы хотите глубже изучить архитектуру, я рекомендую пройти через эту реализацию.
Поскольку мы можем использовать последовательные модели на основе LSTM для составления многошаговых прогнозов, давайте взглянем на Трансформатор и его возможности для таких прогнозов. Однако сначала нам нужно внести несколько изменений в архитектуру, поскольку мы работаем не с последовательностями слов, а со значениями. Кроме того, мы делаем авторегрессию, а не классификацию слов / символов.
ДанныеИмеющиеся данные дают нам почасовую нагрузку для всей области управления ERCOT. Я использовал данные с 2003 по 2015 год в качестве обучающей выборки и 2016 года в качестве тестовой. Имея только значение нагрузки и метку времени загрузки, я расширил метку времени на другие функции. Из метки времени я извлек день недели, которому он соответствует, и закодировал его в горячем режиме. Кроме того, я использовал год (2003, 2004,…, 2015) и соответствующий час (1, 2, 3,…, 24) как само значение.Это дает мне в общей сложности 11 функций на каждый час дня. В целях сходимости я также нормализовал нагрузку ERCOT, разделив ее на 1000.
Чтобы предсказать заданную последовательность, нам нужна последовательность из прошлого. Размер этих окон может варьироваться от варианта к варианту использования, но здесь, в нашем примере, я использовал почасовые данные за предыдущие 24 часа, чтобы спрогнозировать следующие 12 часов. Помогает то, что мы можем регулировать размер этих окон в зависимости от наших потребностей. Например, мы можем изменить это на ежедневные данные вместо почасовых данных.
Изменения в модели из бумагиВ качестве первого шага нам нужно удалить вложения, так как у нас уже есть числовые значения во входных данных. Вложение обычно отображает данное целое число в n-мерное пространство. Здесь вместо использования встраивания я просто использовал линейное преобразование для преобразования 11-мерных данных в n-мерное пространство. Это похоже на вложение со словами.
Нам также необходимо удалить слой SoftMax из выходных данных Transformer, потому что наши выходные узлы являются не вероятностями, а реальными значениями.
После этих незначительных изменений можно начинать обучение!
Как уже упоминалось, я использовал принуждение учителя для обучения. Это означает, что кодер получает окно из 24 точек данных в качестве входных данных, а входные данные декодера представляют собой окно из 12 точек данных, где первая представляет собой значение «начала последовательности», а следующие точки данных представляют собой просто целевую последовательность. Введя значение «начало последовательности» в начале, я сдвинул ввод декодера на одну позицию относительно целевой последовательности.
Я использовал 11-мерный вектор только с -1 в качестве значений «начала последовательности». Конечно, это можно изменить, и, возможно, было бы полезно использовать другие значения в зависимости от варианта использования, но для этого примера это работает, поскольку у нас никогда не бывает отрицательных значений ни в одном из измерений последовательностей ввода / вывода.
Функция потерь для этого примера — это просто среднеквадратичная ошибка.
РезультатыДва графика ниже показывают результаты. Я взял среднее значение почасовых значений за день и сравнил его с правильными значениями.Первый график показывает 12-часовые прогнозы, сделанные за 24 предыдущих часа. Для второго графика мы предсказали один час с учетом предыдущих 24 часов. Мы видим, что модель очень хорошо улавливает некоторые колебания. Среднеквадратичная ошибка для обучающего набора составляет 859, а для набора проверки — 4 106 для 12-часовых прогнозов и 2583 для 1-часовых прогнозов. Это соответствует средней абсолютной процентной ошибке прогноза модели 8,4% для первого графика и 5,1% для второго.
Рисунок 3: 12-часовой прогноз с учетом предыдущих 24 часов за один год Рисунок 4: 1-часовой прогноз с учетом предыдущих 24 часов за один годРезультаты показывают, что можно было бы использовать архитектуру Transformer для прогнозирования временных рядов. Однако во время оценки это показывает, что чем больше шагов мы хотим спрогнозировать, тем выше будет ошибка. Первый график (рис. 3) выше был получен с использованием 24 часов для прогнозирования следующих 12 часов. Если мы спрогнозируем только один час, результаты будут намного лучше, как мы видим на втором графике (рисунок 4).
Есть много места, где можно поиграть с параметрами преобразователя, такими как количество слоев декодера и кодировщика и т. Д. Это не было задумано как идеальная модель, и при лучшей настройке и обучении результаты, вероятно, улучшатся.
Это может быть большим подспорьем для ускорения обучения с использованием графических процессоров. Я использовал локальную платформу Watson Studio для обучения моей модели с помощью графических процессоров, и я позволил ей работать там, а не на моем локальном компьютере. Вы также можете ускорить обучение с помощью графических процессоров Watson Machine Learning, которые бесплатны до определенного времени! Прочтите мой предыдущий блог, чтобы узнать, как это можно легко интегрировать в ваш код.
Большое спасибо за то, что прочитали это, и я надеюсь, что смог прояснить несколько понятий людям, которые только начинают изучать глубокое обучение!
Сделайте Pytorch Transformer в два раза быстрее при генерации последовательности.
В Scale AI мы используем модели машинного обучения в широком спектре приложений, чтобы расширить возможности конвейера маркировки данных. Мы стремимся к скорости и эффективности и всегда стараемся максимально использовать возможности моделей. Здесь мы обсудим некоторые обнаруженные нами уловки, которые значительно улучшают реализацию PyTorch Transformer всего в нескольких строках кода.
Трансформеры здесь, чтобы остаться
Трансформаторы стали повсеместными. Впервые они были представлены в Attention is All You Need (Vaswani et al., 2017) и быстро добавлены в Pytorch. Их популярность еще больше возросла с развитием HuggingFace, который сделал большие предварительно обученные модели НЛП, такие как BERT (Devlin et al., 2018), широко доступными, и создал рецепты, позволяющие выполнять простую тонкую настройку для широкого круга задач. Они были успешно применены к широкому спектру задач от последовательности к последовательности (Seq2Seq), включая машинный перевод, обобщение текста или даже создание подписей к изображениям (изображение — это всего лишь последовательность пикселей!).Эта популярность полностью оправдана, потому что у Трансформеров есть несколько существенных плюсов:
Архитектура трансформатора не является последовательной, что делает его распространяемым. Другие традиционные методы моделирования последовательности, такие как RNN, ограничиваются обработкой последовательностей по одному токену за раз. Такой последовательный характер предотвращает распараллеливание и замедляет обучение. Трансформаторы обрабатывают целые последовательности одновременно в очень параллельной манере. Это делает их невероятно быстрыми на графических процессорах и помогает элегантно обрабатывать дальнодействующие зависимости.
Трансформаторы делают несколько предположений относительно данных. Традиционно специалисты по машинному обучению настраивают свои сети для обработки определенных типов данных. Такие ограничения, как принуждение RNN к последовательной обработке текста слева направо, позволили этим сетям хорошо работать даже с ограниченными данными для обучения, что стало прорывом. Однако эти ограничения вносят систематические ошибки в модель, поскольку последовательное упорядочение редко бывает наиболее оптимальным способом понимания текста. Трансформаторы сохраняют представления данных в общих чертах, что позволяет им изучать более тонкие взаимодействия между словами.Недавние статьи (Алексей Досовицкий и др., 2020) показывают, что та же история может быть верной и в области компьютерного зрения, когда преобразователи превосходят давно созданные CNN, когда-то обученные на огромных наборах данных, которые были недавно собраны. Имея достаточно данных, Transformers изучают более сложные и точные представления, чем ограниченные сети, которые раньше были единственным жизнеспособным вариантом.
Последовательность с трансформаторами
Но у Трансформеров есть и свои недостатки.При генерации последовательностей для задач Seq2Seq во время вывода преобразователи ограничены, потому что каждый элемент в выходной последовательности может быть предсказан только по одному за раз. Это в сочетании с квадратичной сложностью внимания может сделать их медленнее, чем их коллеги. (Для обучения это не проблема, благодаря принуждению учителя).
МоделиSeq2Seq обычно создают внутреннее высокоуровневое представление входной последовательности, а затем декодируют (т. Е. Генерируют) выходное предложение. Учитывая высокоуровневое представление входного предложения и уже декодированных слов, модели Seq2Seq оценивают наиболее вероятные слова для завершения предложения.Это явление называется авторегрессией , а фаза, соответствующая генерации нового слова (или токена), — это временной шаг .
Когда в качестве модели Seq2Seq используется преобразователь, входная последовательность проходит через кодировщик, а выходная последовательность затем генерируется декодером, как показано на рисунках 1 и 2.Неэффективность декодирования преобразователей
PyTorchКласс Transformer в Pytorch является универсальным, и это здорово, потому что он дает исследователям машинного обучения в Scale AI точный контроль, но это также означает, что он не оптимизирован для скорости.Давайте посмотрим глубже.
Во-первых, на рисунке 1 можно увидеть, что выходной сигнал кодера можно вычислить отдельно от декодера. Это означает, что выходные данные кодера могут быть вычислены один раз и впоследствии повторно использованы для каждого временного шага. Но Pytorch НЕ сохраняет это для вас — и фактически тратит впустую вычислительные ресурсы для каждого временного шага декодирования. Чтобы исправить это, всегда следует разделять кодировщик трансформатора и декодер.
# ЭТО НАЙДЕННЫЙ СПОСОБ ИСПОЛЬЗОВАНИЯ ТРАНСФОРМАТОРОВ
# ИНИЦИАЛИЗАЦИЯ
трансформатор = nn.Трансформатор (
d_model = hdim,
nhead = nhead,
num_encoder_layers = num_layers,
num_decoder_layers = num_layers,
dim_feedforward = dim_feedforward,
) .to (устройство = устройство)
transformer.eval ()
# ВЫВОД ПЕТЛИ
decoded_tokens = первый токен
for i in range (len_output_to_decode): # генерировать токены `len_output_to_decode`
mask_dec = generate_square_subsequent_mask (
я + 1, устройство = first_token.device
) # создать маску для авторегрессионного декодирования
decoded_embeddings = встраивание (decoded_tokens)
output = трансформатор (src, decoded_embeddings, tgt_mask = mask_dec)
logits = to_vocab (output) # проекция на размер словаря
# сохранить наиболее вероятные токены
top_indices = факел.argmax (логиты, dim = -1)
# нас интересует только последний токен, который был декодирован
top_indices_last_token = top_indices [-1:]
# добавить наиболее вероятный токен к уже декодированным токенам
decoded_tokens = torch.cat (
[decoded_tokens, top_indices_last_token], dim = 0
)
Приведенный ниже код представляет собой гораздо более эффективный способ получить те же результаты путем разделения кодировщика и декодера. Обратите внимание, что код, соответствующий циклу вывода, практически не меняется.
# ИНИЦИАЛИЗАЦИЯ
кодировщик = nn.TransformerEncoder (
nn.TransformerEncoderLayer (
d_model = hdim, nhead = nhead, dim_feedforward = dim_feedforward
),
num_layers = num_layers,
) .to (устройство = устройство)
encoder.eval ()
decoder = nn.TransformerDecoder (
nn.TransformerDecoderLayer (
d_model = hdim, nhead = nhead, dim_feedforward = dim_feedforward
),
num_layers = num_layers,
) .to (устройство = устройство)
decoder.eval ()
# ВЫВОД ПЕТЛИ
decoded_tokens = first_token
src_embeddings = кодировщик (src)
для i в диапазоне (lenoutput_to_decode):
mask_dec = generate_square_subsequent_mask (
я + 1, устройство = first_token.устройство
) # создать маску для авторегрессионного декодирования
decoded_embeddings = встраивание (decoded_tokens)
# декодер использует вывод кодировщика `src_embeddings`
вывод = декодер (decoded_embeddings, src_embeddings, tgt_mask = mask_dec)
logits = to_vocab (output) # проекция на размер словаря
# сохранить наиболее вероятные токены
top_indices = torch.argmax (логиты, dim = -1)
# нас интересует только последний токен, который был декодирован
top_indices_last_token = top_indices [-1:]
# добавить наиболее вероятный токен к уже декодированным токенам
decoded_tokens = факел.Кот(
[decoded_tokens, top_indices_last_token], dim = 0
)
Основная неэффективность распространяется на предыдущий пункт. На рисунке 2 можно увидеть, что встраивание декодированного токена зависит только от токенов, которые были декодированы до него. Это прямое преимущество авторегрессионной модели Transformer. Таким образом, нет необходимости повторно вычислять вложения уже декодированных токенов, и вместо этого мы можем снова их кэшировать. Таким образом, каждый временной шаг состоит только из вычисления внимания к встраиванию новейшего токена.
Рисунок 3: Ссылки на самовнимание декодера при декодировании токенов . Поля внизу представляют вложения выходных токенов до самовнимания, верхние блоки представляют встраивания выходных токенов после самовнимания. Используя наш трюк (правая сторона), большинство вложений не пересчитываются, поскольку они кэшируются. Количество учитываемых ссылок становится линейным, а не квадратичным.
С точки зрения сложности, генерация n-го выходного токена без наших уловок включает в себя вычисление внимания к себе по всему текущему выходу ( O (n²)) и вычисление внимания кодера-декодера между всем входом (размера, который мы будем примечание M) с токовым выходом ( O (Mn)).Следовательно, сложность каждого временного шага составляет O (Mn + n²). Учитывая, что мы хотим декодировать N токенов, необходимо N временных шагов, а окончательная сложность составит O (MN² + N³).
Наш трюк ускоряется с каждым временным шагом. Вычисляются только те части самовнимания и внимания кодировщика-декодера, которые отвечают за обновление последнего токена. На рисунке 3 показано, как это работает с самовниманием. Новая сложность каждого временного шага составляет O (M + N), поэтому с N временными шагами окончательная сложность увеличивается до O (MN + N²).
Не предполагается, что архитектура декодера PyTorch Transformer является авторегрессионной. Однако, унаследовав уровень TransformerDecoder, мы вводим CausalTransformerDecoder, который использует кеш для реализации описанного выше улучшения. Наш код отличается от реализации Pytorch всего на несколько строк. Наш новый декодер работает аналогично оригинальному TransformerDecoder, за исключением того, что теперь мы должны учитывать кеш:
causal_decoder = CausalTransformerDecoder (
CausalTransformerDecoderLayer (
d_model = hdim,
nhead = nhead,
dim_feedforward = dim_feedforward,
),
num_layers = 6,
).к (устройство = устройство)
causal_decoder.eval ()
decoded_tokens = first_token
src_embeddings = кодировщик (src)
cache = None
для i в диапазоне (len_output_to_decode):
mask_dec = generate_square_subsequent_mask (
я + 1, устройство = first_token.device
) # создать маску для авторегрессионного декодирования
decoded_embeddings = встраивание (decoded_tokens)
# только здесь меняем: добавляем кеш как дополнительный параметр
вывод, cache = causal_decoder (decoded_embeddings, src_embeddings, кеш)
logits = to_vocab (output) # проекция на размер словаря
# сохранить наиболее вероятные токены
top_indices = факел.argmax (логиты, dim = -1)
# нас интересует только последний токен, который был декодирован
top_indices_last_token = top_indices [-1:]
# добавить наиболее вероятный токен к уже декодированным токенам
decoded_tokens = torch.cat (
[decoded_tokens, top_indices_last_token], dim = 0
)
Эксперименты
Мы проверили наши изменения, чтобы увидеть, насколько быстрее мы можем работать. Мы представляем два разных сценария: перевод и создание длинных текстов.
Мы сравниваем наши три разные реализации (подробности см. В сносках):
- Самая наивная реализация Pytorch (определенная в первом фрагменте кода), в которой используется nn.Трансформатор
- Реализация кодировщика-декодера Pytorch (вторая часть кода).
- Наш CausalTransformerDecoder (третий фрагмент кода).
Напоминаем, что это три разные реализации одной и той же модели. При инициализации с одинаковыми весами они возвращают одинаковые выходные данные.
Перевод текста
Первая настройка соответствует переводу. В этой настройке входные и выходные последовательности, как правило, короткие и одинаковой длины.
Нелинейные кривые показывают, что механизмы внимания постепенно становятся наиболее ресурсоемкими частями модели по мере увеличения количества входных и выходных токенов. Наша причинная реализация на 40% быстрее, чем реализация Pytorch Encoder-Decoder, и на 150% быстрее, чем реализация Pytorch nn.Transformer для 500 токенов ввода / вывода.Генерация длинного текста
Теперь мы просим модель генерировать длинные последовательности из входных данных фиксированного размера. Такая ситуация может возникнуть при создании истории из изображения или из первоначальной подсказки.
Приведенные ниже результаты были получены при фиксированном размере ввода 500 токенов. Увеличение количества входных токенов замедляет работу моделей, но не меняет наблюдаемых общих тенденций.
Наша причинно-следственная модель в два раза быстрее, чем реализация кодировщика-декодера PyTorch, когда количество токенов для генерации превышает 1000. При декодировании более 500 токенов соотношение времени между причинной моделью и другими реализациями становится линейным. Это подтверждает теорию, согласно которой общая сложность декодирования была уменьшена в N.Наконец, наш CausalTransformerDecoder также может использоваться без какого-либо входного предложения (т.е. без кодировщика), как это имеет место в некоторых общих настройках генерации. Модель обычно просят написать рассказ или статью. Более подробную информацию об этом типе генерации можно найти в статьях GPT (Alec Radford et al., 2018). Результаты, которые мы находим для этого случая, аналогичны приведенным выше.
Копаем глубже …
Можно заметить, что кэширование вывода каждого слоя неоптимально.Действительно, первая стадия уровней внимания состоит из проецирования вложений в области ключей, значений и запросов. В реализации PyTorch и предлагаемой реализации одни и те же вложения проецируются повторно. Вместо этого запросы, ключи и значения можно напрямую кэшировать. Однако для этого потребуется значительно больше изменений, которые могут стать нестабильными с новыми обновлениями Pytorch. Более того, предполагаемый выигрыш незначителен — менее 5% от наших экспериментов.
Для стандартных случаев использования NLP репозиторий HuggingFace уже включает эти оптимизации.В частности, он кэширует ключи и значения. Он также имеет различные варианты декодирования, такие как поиск луча или выборка ядра.
Заключение
Предлагаемые простые приемы используют тот факт, что общая реализация Transformer в Pytorch слишком универсальна. Изменения обеспечивают скромное повышение скорости при генерации нескольких сотен токенов, что может стать значительным приростом по сравнению с исходной реализацией PyTorch, когда длина вывода приближается к тысяче токенов.Эти выигрыши, естественно, прямо пропорциональны количеству выходных токенов для декодирования. И что лучше всего, они могут быть реализованы всего в нескольких строках с помощью нашего репо.
Ссылки:
Ашиш Васвани, Ноам Шазир, Ники Пармар, Якоб Ушкорейт, Ллион Джонс, Эйдан Н. Гомес, Лукаш Кайзер и Илья Полосухин. Внимание — это все, что вам нужно . В достижениях в системах обработки нейронной информации 30, стр. 5998–6008. Curran Associates, Inc., 2017. URL: https: // Протоколы.nerips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Джейкоб Девлин, Мин-Вэй Чанг, Кентон Ли и Кристина Тутанова. BERT: предварительная подготовка глубоких двунаправленных преобразователей для понимания языка . CoRR, abs / 1810.04805, 2018. URL: http://arxiv.org/abs/1810.04805.
Алексей Досовицкий, Лукас Бейер, Александр Колесников, Дирк Вайссенборн, Сяохуа Чжай, Томас Унтертинер, Мостафа Дехгани и др. Изображение стоит 16×16 слов: преобразователи для распознавания изображений в масштабе. препринт arXiv 2020 URL: https://arxiv.org/pdf/2010.11929
Томас Вольф, Лисандра Дебют, Виктор Сань, Жюльен Шомон, Клемент Деланге, Энтони Мои, Пьеррик Систак и другие. Трансформеры: современная обработка естественного языка препринт arXiv 2019 URL: https://arxiv.org/pdf/1910.03771.pdf
Алек Рэдфорд, Картик Нарасимхан, Тим Салиманс и Илья Суцкевер. Улучшение понимания языка с помощью генеративного предварительного обучения. arXiv препринт 2018 URL: https: // www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
1 — Объем словарного запаса, использованного для этого эксперимента, составлял 30 000. Он соответствует размеру словаря, выбранному в исходной статье BERT, в которой используется токенизация BPE. Мы также провели те же эксперименты с гораздо меньшим словарным запасом (128 жетонов), чтобы имитировать настройку уровня персонажа, которая не показала значительных преимуществ.
2 — Гиперпараметры, используемые для архитектуры Transformer, соответствуют оригинальной статье (6 слоев, 8 голов, 512 скрытых измерений, 2048 скрытых измерений с прямой связью для кодировщика / декодера).Результаты должны быть аналогичны другим конфигурациям при условии, что кодер и декодер имеют одинаковый размер.
3 — Отображаемые результаты соответствуют размеру пакета из 8 последовательностей, но мы убедились, что размер пакета, равный 1, дает ту же тенденцию. Размер пакета, равный 1, обычно является наиболее распространенным при выводе, поскольку запросы отправляются асинхронно. Однако в нашей конкретной настройке модели требуется несколько секунд для генерации предложений, поэтому более естественно использовать пакетные запросы.
3 — Для проверки безопасности мы сравнили реализацию GPT-2 HuggingFace с нашим причинным декодером.Для этого мы использовали тот же набор гиперпараметров. Мы сгенерировали до 1000 токенов с помощью двух моделей. Передаточное число между этими двумя моделями было близко к 1, колеблясь между 0,85 и 1,10.
4 — Все эксперименты проводились на графическом процессоре V100.
Двустороннее авторегрессионное декодирование на основе трансформатора в нейронном машинном переводе
@inproceedings {imamura-sumita-2020-transformer,
title = "Двустороннее авторегрессионное декодирование на основе трансформатора в нейронном машинном переводе",
author = "Имамура, Кенджи и
Сумита, Эйитиро ",
booktitle = "Труды 7-го семинара по азиатскому переводу",
месяц = декабрь,
год = "2020",
address = "Сучжоу, Китай",
publisher = "Ассоциация компьютерной лингвистики",
url = "https: // аклантология.org / 2020.wat-1.3 ",
pages = "50-57",
abstract = "В этой статье представлен простой метод, который расширяет стандартный авторегрессионный декодер на основе трансформатора для ускорения декодирования. Предлагаемый метод генерирует токен из начала и конца предложения (всего два токена) на каждом шаге. Одновременно генерируя несколько токенов, которые редко зависят друг от друга, скорость декодирования увеличивается, а ухудшение качества перевода сводится к минимуму. В наших экспериментах предложенный метод увеличил скорость перевода примерно на 113 {\%} - 155 {\%} по сравнению со стандартным авторегрессивным декодером, при этом баллы BLEU ухудшаются не более чем на 1.03. Во многих условиях он был быстрее, чем итеративный неавторегрессивный декодер. ",
}
<моды> Двунаправленное авторегрессионное декодирование на основе двух токенов в нейронном машинном переводе Кенджи Имамура <роль>автор Эйитиро Сумита <роль>автор декабрь 2020 г. текст Материалы 7-го семинара по азиатскому переводу Ассоциация компьютерной лингвистики <место>Сучжоу, Китай публикация конференции В этой статье представлен простой метод, расширяющий стандартный авторегрессионный декодер на основе Transformer для ускорения декодирования.Предлагаемый метод генерирует токен из начала и конца предложения (всего два токена) на каждом шаге. За счет одновременной генерации нескольких токенов, которые редко зависят друг от друга, скорость декодирования увеличивается, а ухудшение качества перевода сводится к минимуму. В наших экспериментах предложенный метод увеличил скорость трансляции примерно на 113% -155% по сравнению со стандартным авторегрессионным декодером, при этом снизив оценку BLEU не более чем на 1,03. Во многих условиях он был быстрее, чем итеративный неавторегрессивный декодер. imamura-sumita-2020-transformer <местоположение>https://aclanthology.org/2020.wat-1.3 декабрь 2020 50 57
% 0 Материалы конференции Двунаправленное авторегрессионное декодирование на основе трансформатора% T в нейронном машинном переводе % А Имамура, Кендзи % А Сумита, Эйитиро % S Труды 7-го семинара по азиатскому переводу % D 2020 % 8 дек % I Ассоциация компьютерной лингвистики % C Сучжоу, Китай % F imamura-sumita-2020-трансформатор % X В этой статье представлен простой метод, расширяющий стандартный авторегрессивный декодер на основе трансформатора для ускорения декодирования.Предлагаемый метод генерирует токен из начала и конца предложения (всего два токена) на каждом шаге.