


Вводной автомат. Расчет, выбор вводного автомата для квартиры
Вступление
Здравствуйте. Вводной автомат это обязательное устройство электропроводки квартиры предназначенное для защиты всей электропроводки от перегрева и токов короткого замыкания, а также общего отключения электропитания квартиры. О выборе, расчете вводного автомата пойдет речь в этой статье.
Назначение вводного автомата
Вводной автомат должен обеспечить защиту проводов и кабелей от перегрева, способного вызвать их разрушение или пожар. Причинами перегрева могут быть длительные перегрузки или значительные токи короткого замыкания.
Для предотвращения перегрева проводов используют хорошо испытанное решение : вводной автоматический выключатель (автомат защиты), содержит тепловой и электромагнитный расцепитель. Вводной автомат также обеспечивает выполнение функций отключения всей электросети квартиры и разделение питающей линии от групповых электрических цепей квартиры.
Выбор вводного автомата для электропроводки квартиры
Выбор вводного автомата зависит от следующих условий и величин:
- Величины линейного напряжения;
- Режима нейтрали;
- Частоты тока;
- Характеристик токов короткого замыкания;
- Установленной мощности;
Величина линейного напряжения
Для нашей электросети значение фазного и линейного напряжения для квартиры величины постоянные. Это 220 Вольт или 380 Вольт соответственно.
Частота тока
Частоты тока величина тоже постоянная. Это 50 Герц (Гц).
Режим нейтрали
Режим нейтрали это тип заземления, используемый в вашем доме. В подавляющем большинстве это система TN ,система с глухозаземленной нейтралью c различными ее вариациями (TN-C; TN-C-S; TN-S).
Характеристики токов короткого замыкания
Короткое замыкание это несанкционированное соединение двух фазных проводников или фазного и нулевого рабочего проводников или фазного проводника с системой заземления. Самое опасное короткое замыкание (КЗ), которое учитывается в расчетах электросхем, это замыкание трех фазных проводников находящихся под напряжением.
Самое опасное короткое замыкание (КЗ), которое учитывается в расчетах электросхем, это замыкание трех фазных проводников находящихся под напряжением.
Ток короткого замыкания это важная характеристика для выбора автомата защиты. Для выбора вводного автомата рассчитывается ожидаемый ток короткого замыкания.
Расчет ожидаемого тока короткого замыкания для трехфазной сети, короткое замыкание (КЗ) между фазами:
- I-ожидаемый ток короткого замыкания, A.
- U-Линейное напряжение,
- p-Удельное сопротивление жилы кабеля, для меди 0, 018, для алюминия 0,027;
- L-Длина защищаемого провода;
- S-Площадь сечения жилы кабеля, мм2;
Расчет ожидаемого тока короткого замыкания (КЗ) между фазой и нейтралью
- Uo-Напряжение между фазой и нейтралью;
- m-Отношение сопротивления нейтрального провода и сопротивлением фазного проводи или площадью сечения фазного и нейтральных проводов, если они изготовлены из одного материала.

- P-Удельное сопротивление жилы кабеля, для меди 0, 018, для алюминия 0,027

Режим нейтрали для выбора вводного автомата
Для различных режимов нейтрали применяются следующие вводные автоматы
Выбор вводного автомата для системы TN-S:
Вводной автомат для системы TN-S должен быть
- Однополюсной с нулем или двухполюсной,
- Трехполюсной с нейтралью или четырехполюсной.
Это необходимо для одновременного отключения электросети квартиры от нулевого рабочего и фазных проводников со стороны ввода электропитания. так как нулевой и защитный проводники разделены на всем протяжении.
Выбор вводного автомата для системы TN-C:
Для системы питания TN-C вводной автомат защиты устанавливается однополюсной (при электропитании 220 В) или трехполюсной (при питании 380В). Устанавливаются они на фазные рабочие проводники.
Расчет вводного автомата для электросети квартиры
Расчет вводного автомата для электросети квартиры 380 Вольт
Для выбора вводного автомата рассчитываем ток нагрузки:
- Uн-Напряжение сети;
- Pp-Расчетная мощность;
- Cosф-(Косинус фи)Коэффициент мощности;
- Для отстойки от ложного срабатывания номинальный ток теплового расцепителя вводного автомата выбираем на 10% больше:
- Iт. р.=Iр×1,1
 р.=Iр×1,1
р.=Iр×1,1Расчет вводного автомата для электросети квартиры 220 Вольт
- Iр=Pр/Uф×cosф
- Uф –фазное напряжение;
- Iт.р.=Iр×1,1
Примечание: Cosф (Косинус фи) Коэффициент мощности: Безразмерная величина характеризирующая наличие в нагрузке реактивной мощности. По сути отношение активной к реактивной мощности.
©Elesant.ru
Нормативные документы
- ГОСТ Р 50571.5-94 (ГОСТ 30331.5-95) Электроустановки зданий. Часть 4. Требования по обеспечению безопасности. Защита от сверхтока
- ПУЭ, часть 3, (изд.шестое) Защита и автоматика.
Другие статьи раздела: Электромонтаж
Как подобрать автоматический выключатель в дом или квартиру
← Модульные переключатели ввода резерва I-O-II до 125А от Hager || Обеспечение непрерывного электроснабжения коттеджей – ручной и автоматический ввод резервного питания на оборудовании HAGER →
Как подобрать автоматический выключатель в дом или квартиру
Автоматический выключатель или, как часто говорят, автомат – приборы, необходимые для защиты от короткого замыкания или перегрузки любой сети, и конечно же в быту.
Так что самое главное в защите электричества вашего дома, это автоматы. Задача автоматов выключить подачу электрического тока в квартиру при кротком замыкании и перегрузке электросети (см. рис.1). Если такое происходит, необходимо открыть дверь электрощитка, где установлены автоматы и найти тот, у которого рычажок смотрит вниз, как на рисунке, и взвести его вверх. Если автоматический выключатель вновь отключится, можно попробовать достать из розеток вилки тех бытовых приборов (например, электроплита, стиральная или моющая машина, утюг и т.д.), которые защищены этим автоматом. Затем вновь взвести рычажок автомата, и, если он не отключится, пробовать по очереди включать в розетки приборы, чтобы установить возможную причину — неисправность бытовой техники, которая инициирует выключение автомата. Если и здесь вы потерпите неудачу, в любом случае вызывайте специалиста.
Рис.1 Вводной двухполюсный автоматический выключатель производства Hager на 63А.
Наиболее часто встречающиеся неисправности: серьезная поломка бытовой техники, плохой контакт или короткое замыкание в проводах и выход из строя самого автоматического выключателя.
Автоматические выключатели делятся по мощности срабатывания в амперах. Бывают основные и часто используемые в квартирах по шкале номинальных токов: 10 А, 16 А, 25 А, 32 А, 40А, а в последнее время 50А и 63 А. Но есть одно НО. Для того чтобы автоматические выключатели работали эффективно, необходимо правильно подобрать их мощность для соответствующей линии. Лучше всего проконсультироваться со специалистами, но если под рукой их нет, сделаем это сами.
Посчитаем потребляемую мощность электроприборов в квартире.
Пример: у вас стоит электроплита с потребляемой мощностью по паспорту 5 кВт (5000 ватт), микроволновка 1 кВт, электрочайник 1.5 кВт. То есть общая мощность, максимально составит суммарно 7.5 кВт. Теперь давайте переведем полученную мощность в амперы, для этого нам нужна знать сколько в одном киловатте ампер.
1 кВ = 4.5 А
Значит если максимальная мощность 7.5 кВ умножаем на 4.5 А и получаем 33.75 А. Берем шкалу номинальных токов автоматов (см. выше): выше 33.75А ближайший номинал 40А. То есть, если нам необходимо поставить защиту на это электрооборудование, требуется автомат на 40 А.
Рис.2 Автоматический выключатель однополюсный 20А.
Но также необходимо принимать во внимание, что этот расчет мы привели из тех условий, что наше оборудование работает постоянно на полную мощность. В жилых помещениях, простых домах и квартирах полная загрузка сети происходит очень редко, ведь вы не пользуетесь той же электроплитой всегда на полную её мощность и одновременно включаете печь, утюг и электрочайник. Так что постарайтесь решить, какие и сколько приборов обычно бывает включено одновременно, в основном это чайник, электробойлер, пылесос, утюг, несколько конфорок на электроплите, телевизор, компьютер.
Современное электрооборудование требует повышенных затрат электроэнергии, Поэтому розетки, свет, прямое подключение разделяют на несколько линий (проводов).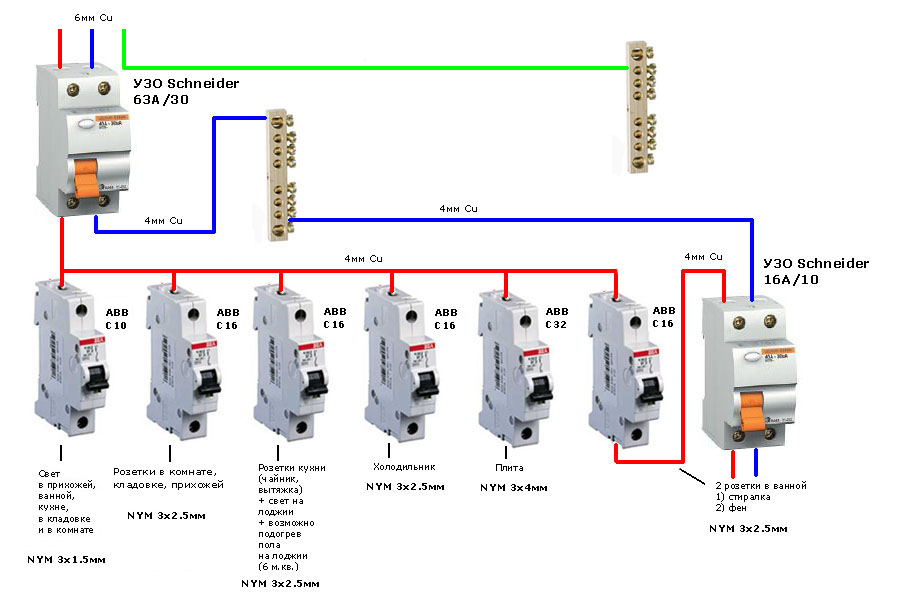
Рис.3 Так выглядит электрический шкаф уже в сборе с автоматическими выключателями.
Вводной автомат для квартиры и дома: как выбрать и установить
Вводный автоматический выключатель являет собой обязательное устройство, которое ставят в щиток для защиты всех проводов объекта от аварийных ситуаций в виде короткого замыкания и перегрузки. Также вводной автомат задействуется, когда надо полностью отключить все электропитание объекта, к примеру, для ремонтных мероприятий, модернизации сети или на время сбоя. Под объектом имеется в виду квартира или дом.
Под объектом имеется в виду квартира или дом.
Когда вы слышите о вводном автомате, не следует представлять себе нечто особенное. Это всем привычный АВ со стандартным функционалом:
- в однофазной сети используют двухполюсные выключатели;
- в трехфазной сети — трех- или четырехполюсники; отличие между ними довольно простое для понимания — первый разрывает только линейные провода, а второй дополнительно и нейтральный проводник.
Отметим, что вводный выключатель чаще всего выносится за пределы квартиры и частного дома. Прибор устанавливается, как правило, на лестничной клетке многоэтажного жилого здания или на улице в частном секторе.
Где и как ставить вводный выключатель
Теоретически вводной автомат можно монтировать как перед счетчиком, так и после него. Монтаж перед счетчиком подлежит обязательной пломбировке. Есть в продаже варианты боксов и распредщитов с продуманной ячейкой для опломбирования вводного автомата.
Большинство специалистов сходятся во мнении, что лучше ставить вводной автоматический выключатель перед устройством учета.
 Нельзя эксплуатировать электропроводку без вводного АВ по правилам ПУЭ.
Нельзя эксплуатировать электропроводку без вводного АВ по правилам ПУЭ.Схемы подключения вводных автоматических выключателей для электросетей 220V и 380V вы сможете рассмотреть далее.
Как определиться с моделью для квартиры
Номинал автоматического выключателя зависит от суммарного тока проводника и линий питания. Произведите расчеты, как будто все электроприборы одновременно включены в сеть и работают на максимальной мощности. Иными словами, представьте ситуацию, когда линия будет предельно нагруженной. Кроме мощности потребления надо обязательно смотреть на фазность питания: два полюса в АВ подходят для сети 220V, три или четыре полюса — для 380V. Напряжение к вводному автомату будет подведено посредством подземной или воздушной линии.
Теперь рассмотрим, какой выбрать вводной автомат в квартиру. Если посмотреть в щиток, то перед счетчиком с большой вероятностью увидим автомат, рассчитанный на номинальный ток 25, 32 либо 50 Ампер.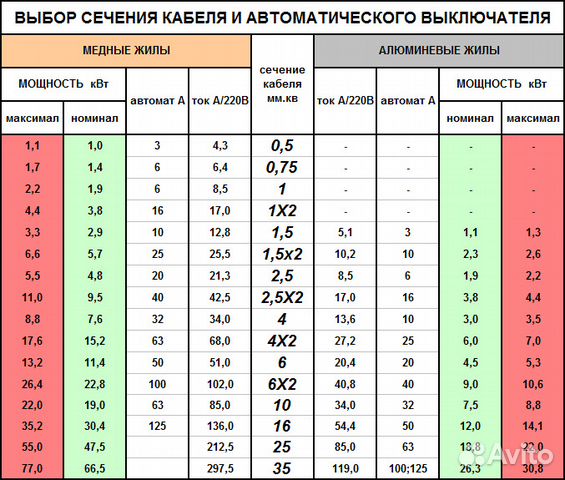 При этом гнаться за максимальным номиналом не советуем, он должен пропорционально соответствовать расчетной суммарной мощности всех потребителей.
При этом гнаться за максимальным номиналом не советуем, он должен пропорционально соответствовать расчетной суммарной мощности всех потребителей.
Вводный двухполюсник для однофазной электросети — это два совмещенных вместе модульных однополюсника, только механизм блокировки и рычаг управления у них общий и единственный. Почему так? Потому что нормативами ПУЭ утвержден запрет на разрыв нейтрального контура. Двухполюсник одновременно монтируется на фазу и ноль, чтобы питание электрическая цепь полностью обесточивалась при срабатывании защиты.
Напоминаем, что нельзя устанавливать вместо двухполюсного вводного автомата пару однополюсных: вы не сможете добиться одновременного отключения двух линий.
Порядок подключения вводного АВ для квартиры выглядит так:
- подключение фазы к первому полюсу, которая потом идет на устройство учета и далее на УЗО и пакетники;
- подключение ноля ко второму полюсу, который потом отходит к счетчику и УЗО по каждой ветке;
- заземление не касается 2-полюсного защитного вводного автомата и подсоединяется к шине РЕ, а потом кабель выводится к приборам в квартире.
По описанной схеме срабатывание АВ обеспечено как на вводной линии, так и на отдельной ветке в качестве перестраховки при поломке выключателя, находящегося в иерархии ниже.
А далее мы расскажем, какие автоматы ставить в частном доме.
Как выбрать автомат на ввод в дом
Питание от трехфазной сети — распространенное явление в частном секторе, поэтому и требования к вводным защитным устройствам особые. В первую очередь обращаем внимание, что выключатель должен быть на 3 или 4 полюса. При коротком замыкании и перегрузке будут отключены все три фазы одномоментно. Четырехполюсное устройство защиты задействует еще и нейтральный провод, что более актуально для 4-фазного подключения. Счетчик подключается после вводного автоматического выключателя.
Нужно знать по поводу вводного автомата для частного дома, сколько ампер в номинале считается оптимальным показателем. Для расчета рабочего тока выполните следующие шаги:
- суммируйте мощность приборов в киловаттах по каждой фазе;
- полученную сумму надо умножить на 4,55 для сети 220V либо на 1,52 для сети с рабочим напряжением 380V;
- просчитанный ампераж укажет, какой автомат на ввод ставить в частный дом, при этом выключатель выбирается с максимально приближенным номиналом, но не меньше рассчитанного числа.

Если предполагается, что мощность по каждой фазе не будет одинаковой, расчеты выполняются по самому большому значению.
С точки зрения практики можно сказать, что для сельской местности и дач хватает отключающей способности 4,5 МА, для современной квартиры — около 6 МА. Если подстанция находится возле вас близко, ориентируйтесь на максимальный ток короткого замыкания в 10 МА. По времятоковым характеристикам выбирать автомат на ввод несложно: тип В подойдет при отсутствии в цепи высокомощных электроприборов. Приборы средней мощности, такие как сварочный аппарат, наилучшим образом совместимы с защитой С-класса. А для защиты высокомощного оборудования надо покупать вводной автомат типа D.
Полезные видео
Видеоролики помогут вам еще лучше сориентироваться по данному вопросу.
Как подобрать автоматический выключательВ статье пойдет речь о том, что такое автоматический выключатель, как выбрать номинал и бренд этого защитного устройства. Перед описанием, как сделать подбор автоматических выключателей, напомним немного общей информации и терминологии касательно самого автоматического выключателя.Автоматический выключатель – от чего защищает?Автоматический выключатель – это электрический прибор, который предназначен для защиты питающего провода (кабеля) от тока короткого замыкания и тепловой перегрузки.Короткое замыкание (КЗ) – это соединение двух точек электрической цепи с различными значениями потенциала, не предусмотренное конструкцией устройства и нарушающее его нормальную работу. Другими, более понятными, словами для обычного пользователя, объясним: короткое замыкание – это соединение двух разных токонесущих проводов, например, фазного проводника и нейтрального, или же двух разных фазных.  Короткое замыкание это аварийное состояние, которое может привести к локальному возгоранию проводки и дальнейшему пожару. Тепловая перегрузка – возникает при длительном протекании тока превышающего номинальный, как следствие – расплавленная изоляция проводника, короткое замыкание. Например, если на линии проложен медный кабель с сечением жил 1,5 мм², то по нормам, ток протекающий по нему не должен превышать показаний более 16 Ампер (3500 Ватт). Любое превышение тока на этой линии приводит к тепловой перегрузке, поэтому если вы сознательно решили перегрузить электролинию, например, захотели погреться мощным обогревателем, то советуем учесть все вышенаписанное. Итак, а теперь по порядку: как сделать правильный подбор автоматических выключателей?Необходим автомат защиты, а как выбрать автоматический выключатель по мощности тока и какого производителя?Ниже опишем главные параметры и особенности которые и будут влиять на выбор автоматических выключателей. 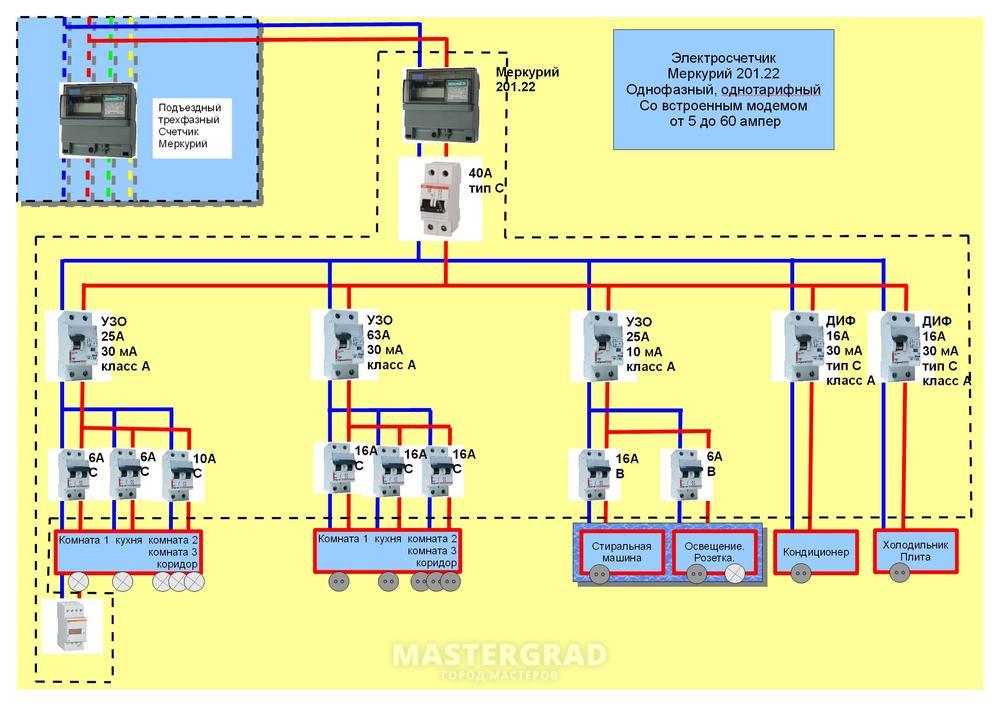 Чтобы правильно выбрать автоматический выключатель нам необходимо определить какую линию он будет защищать, а именно тип провода и сечение проводящей жилы этого провода. Тут все просто – чем больше сечение проводника, тем больше нагрузку он сможет выдержать. | |
| Сечение проводника можно узнать несколькими способами: математическим с вычислением и визуальным методами. Не будем заострять внимание на математическом процессе измерения жилы провода штангенциркулем и вычисление сечения по формуле, так как даже опытные специалисты не всегда могут получить корректные результаты таким образом, а сразу перейдем к простому методу – визуальному. Все упрощается, когда у вас в квартире или доме новая проводка, достаточно прочитать на свежей изоляции кабеля его сечение и через несколько мгновений (используя нашу таблицу, см. ниже) вы уже знаете, наверняка, какой номинальный ток автоматического выключателя будет защищать этот провод. | |
Сложнее в случае, когда проводка старая и большая ее часть замурована в стене, а для визуального определения нам доступен лишь торчащий кусочек кабеля в несколько сантиметров. Действительно, как в этом случае узнать сечение проводника и как к нему выбрать автоматический выключатель? Действительно, как в этом случае узнать сечение проводника и как к нему выбрать автоматический выключатель?Здесь от вас потребуется визуально сравнить жилы кабеля. Например, рядом приставить уже идентифицированную жилу другого кабеля и таким образом, вычислить примерное сечение. Мы понимаем, что такое определение сечения является очень грубым поэтому для страховки, расчет автоматического выключателя к таким проводам необходимо делать с запасом, то есть выбрать автоматический выключатель меньшего максимально допустимого номинала. Обратите внимание, что у нас в статье речь идет о медных кабелях и в таблице приведены данные именно для медных проводников. На всякий случай заметим, что алюминиевые провода, в сравнении с медными, способны к меньшим нагрузкам при равном сечении. | |
Какой автоматический выключатель выбрать по номиналу?Таблица для выбора автоматического выключателя.Выбор автоматического выключателя в зависимости от тока нагрузки, сечения провода/кабеля и способа прокладки.
| |
| |
Таблица для выбора автоматического выключателя по нагрузке. Используйте данные из таблицы, они помогут вам рассчитать автоматический выключатель.
| |
| |
Как подобрать вводной автоматический выключательВводной автоматический выключатель – это автомат защиты, находящийся в цепи самый первый по схеме и подбирается такой автомат по мощности и току исходя из сечения вводного кабеля, то есть вводной автомат защищает вводной кабель. Соответственно необходимо учитывать сечение именно вводного кабеля.Какой производитель автоматического выключателя выбратьВыбор автомата защиты это ответственное занятие, так как речь идет о безопасности. После того, как вы, подобрали автоматический выключатель по току, предварительно учли параметры сечение проводов и нагрузки, остается последний вопрос – какого производителя автоматического выключателя выбрать? Сегодня, рынок перенасыщен предложениями различных производителей, как выбрать автоматический выключатель среди десятков предлагаемых брендов мы опишем ниже. После того, как вы, подобрали автоматический выключатель по току, предварительно учли параметры сечение проводов и нагрузки, остается последний вопрос – какого производителя автоматического выключателя выбрать? Сегодня, рынок перенасыщен предложениями различных производителей, как выбрать автоматический выключатель среди десятков предлагаемых брендов мы опишем ниже.Начав подбор автоматического выключателя по бренду, поинтересуйтесь у продавца, где сделан выключатель, и не забудьте спросить про документы подтверждающие качество устройства. Все современные качественные автоматические выключатели имеют сертификацию независимых лабораторий, что дает косвенный показатель оригинальности и надежности изделия. Если обратить внимание на автоматические выключатели Abb, то они имеют сразу несколько сертификатов качества таких лабораторий, их отметку можно найти на корпусе каждого защитного изделия Abb. Например, сертификат CEBEC (Бельгийская инспекция по электротехнической стандартизации, основывается на результатах международных стандартов). 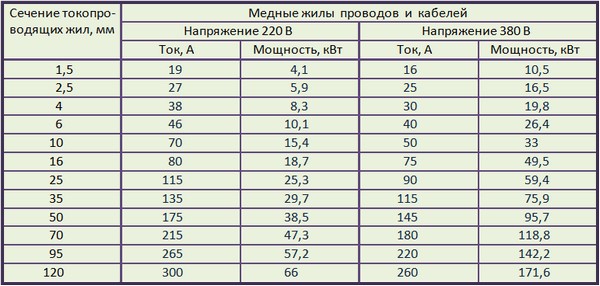 Изделия прошедшие стандартизацию лаборатории CEBEC, перед разрешением продаж, подвергаются тщательным испытаниям в Бельгии. Вот такой автомат защиты можно с уверенностью выбирать, он обеспечит правильную и надежную защиту. Изделия прошедшие стандартизацию лаборатории CEBEC, перед разрешением продаж, подвергаются тщательным испытаниям в Бельгии. Вот такой автомат защиты можно с уверенностью выбирать, он обеспечит правильную и надежную защиту.Стоит заметить, что стоимость автоматических выключателей, прямо пропорционально количеству регалий (отметок лабораторий), поэтому если вы хотите выбрать качественный, надежный и в то же время относительно недорогой автоматический выключатель, советуем выбрать фирменный автоматы самой бюджетной серии, например, автоматические выключатели Hager. Очень важно не купить кустарную подделку, по этому приобретайте автоматические выключатели в специализированных магазинах или у официальных дистрибьюторов. Интернет-магазин «Электрика-Шоп» является специализированным магазином электрики. Наша компания официальная точка продажи продукции таких фирм, как Abb, Hager, Moeller / Eaton, Schneider Electric, Doepke, Legrand. Обращайтесь к нам, мы проконсультируем вас и поможем правильно выбрать автоматический выключатель для вашего дома или квартиры.  | |

 ГОСТ Р 50345-2010 (МЭК 60364-5-52).
ГОСТ Р 50345-2010 (МЭК 60364-5-52).Вводные автоматические выключатели: что это, какие бывают? | ENARGYS.RU
Автоматические выключатели служат для отключения объекта от электроэнергии при возникновение в сети повышенных нагрузок. Благодаря этому удается обезопасить помещение от возникновения пожаров вызванных коротким замыканием и выхода из строя электрооборудования.
Самым первым из таких устройств, которые устанавливаются непосредственно при подводе проводов к квартире, дому или иному помещению является – вводный автомат (рис.1).
Рис. 1. Вводный автомат
Если его сравнивать с автоматами, которые будут установлены дальше по цепи, то у вводного автомата намного выше показания номинального тока. К тому же у него есть еще одна функция, кроме защиты, с помощью него очень удобно отключать систему для проведения в ней ремонтных или профилактических работ.
Также ввиду того, что данный автомат находиться наиболее близко к подстанции, которая осуществляет питание объекта, то у него наблюдается повышенная предельная отключающая способность.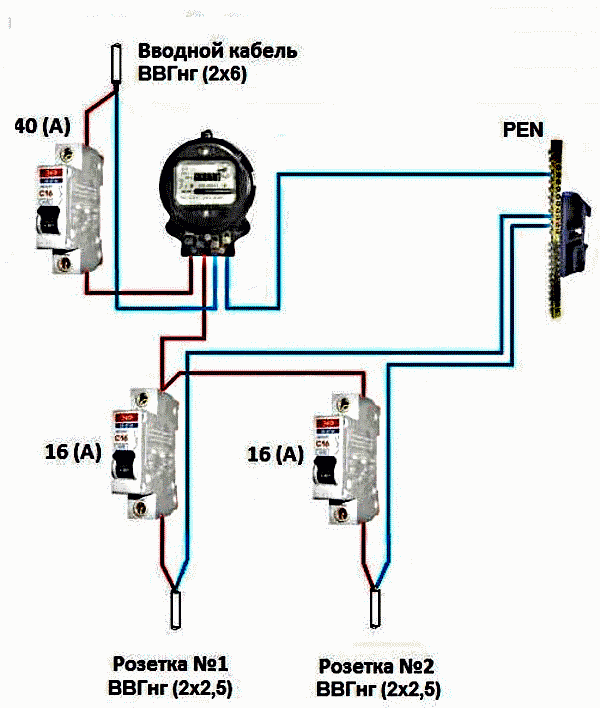 Которая намного выше, чем у других устройств автоматического отключения.
Которая намного выше, чем у других устройств автоматического отключения.
Могут использоваться вводные автоматы – двухполюсные, четырехполюсные (рис.2) или наименее распространенные трехполюсные, все это зависит от той системы электроснабжения, которая выбрана для конкретного объекта.
Рис 2. Четырехполюсной автомат
Так, например, при питании маломощного помещения с использованием одной фазы, устанавливают вводный однополюсной прибор автоматического отключения. Но так поступать неправильно, ведь чтобы обеспечить полный разрыв фазы и нейтрали придется дополнительно устанавливать – выключатель нагрузки.
Вводный автомат и расчет номинала
Чтобы рассчитать номинал вводного автомата нужно произвести в принципе такие же действия, что и при расчете других автоматических выключателей. Для этого нужно взять сумму токов линий, который используются для питания и рабочий ток кабеля.
С помощью таких вычислений происходит нахождение нужного номинального тока вводного автомата.
Важно! У вводного автомата номинальный ток должен быть в соответствии рабочему току проводки (для ее защиты), которая от него отходит. А также учитывать все показания мощностей подключенных нагрузок.
Так же при расчете необходимого номинала нужно учесть, что может случиться ситуация во время которой произойдет включение всех нагрузок одномоментно, появление максимально потребляемого тока. Исходя из этих показаний тока, производится расчет рабочего тока и отходящей от вводного автоматического выключателя проводки, и нужного номинала автомата.
Вводный автомат и его мощность
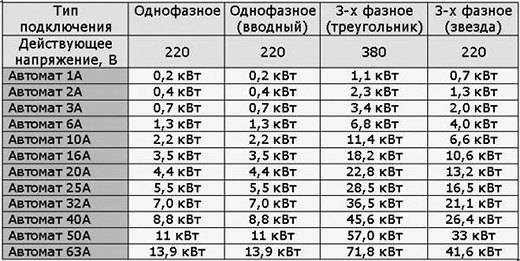
Мощность будет прямо пропорциональная имеющемуся номиналу вводного автомата. Так при одном и тоже номинале автоматического выключателя в зависимости от используемой системы мощность может быть совершенно различной. В однофазной системе для подсчета мощности нужно номинал автомата умножить на 220 и таким образом получиться значение мощности в Ваттах.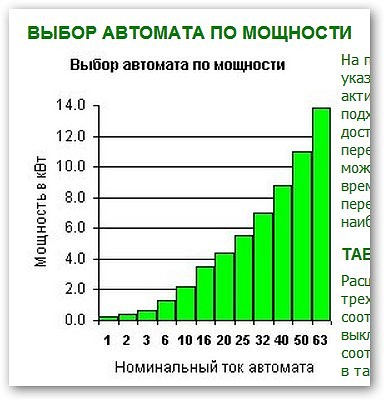 В трехфазной системе, мощность будет зависеть от той схемы, которая применяется при подключении нагрузки.
В трехфазной системе, мощность будет зависеть от той схемы, которая применяется при подключении нагрузки.
Что нужно знать при выборе вводного автомата
При выборе такого вида устройств надо опираться на один из главных параметров – какой может быть максимальный ток при возникновение короткого замыкания. Исходя из знания данного параметра, нужно и выбирать автомат, который будет превышать данное значение. Оптимальным будет, если превышение максимального тока при коротком замыкании будет составлять примерно от 1000-1500А. К тому же важным аспектом будет являться удаленность вводного автомата от трансформатора. И мощности, которую он выделяет.
Не маловажным будет и знание потребляемой мощности запитываемого объекта и фазность питания. При трех фазах следует применять трехфазный автомат, трех или четырехполюсной. Если имеет место быть однофазное питание, то автомат двухполюсной.
Советы по установке вводного автомата
В принципе установка вводного автомата происходит по стандартной схеме, как и установка других устройств в системе.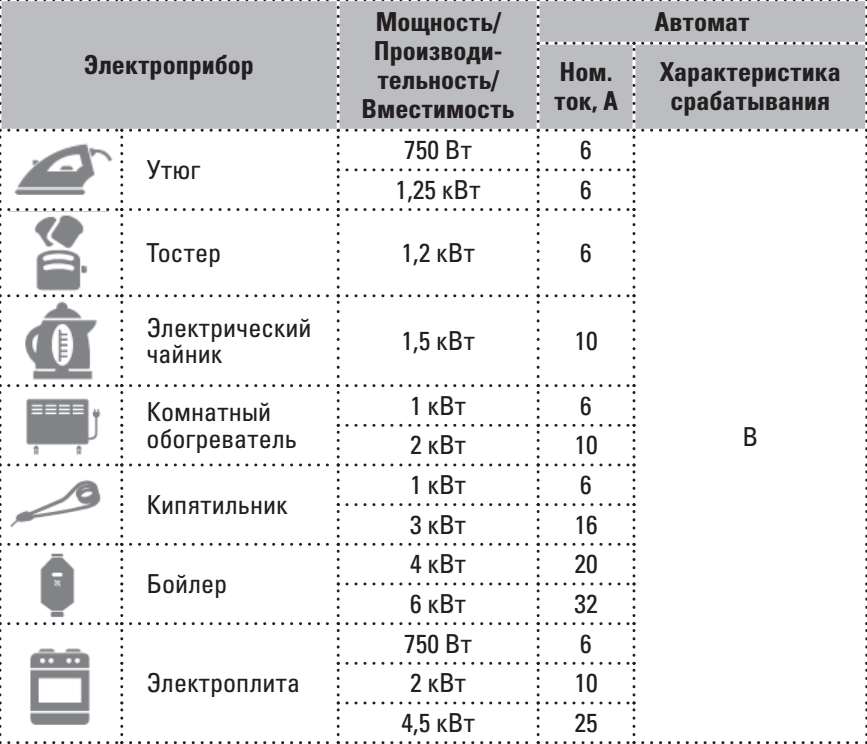 Но в отличие от остальных к него есть определенное место. Оно располагается сверху в левой части щитка. Такой расположение обуславливается тем, что идущие лини удобнее опускать сверху в низ. А данный автомат является первым из устройств подключения. К тому же это очень удобно. Он является немного обособленным от других. Это позволяет моментально сориентироваться даже не опытному человеку при необходимости экстренного отключения. Таким образом схема автоматического выключателя не является сложной.
Но в отличие от остальных к него есть определенное место. Оно располагается сверху в левой части щитка. Такой расположение обуславливается тем, что идущие лини удобнее опускать сверху в низ. А данный автомат является первым из устройств подключения. К тому же это очень удобно. Он является немного обособленным от других. Это позволяет моментально сориентироваться даже не опытному человеку при необходимости экстренного отключения. Таким образом схема автоматического выключателя не является сложной.
Иногда правда можно увидеть, что для небольших объектов энергоснабжения применяется однополюсной автоматический выключатель (рис. 3). Но это не совсем правильно. Так как он устанавливается только на фазу. И при отключении нейтраль все равно находится в рабочем состоянии.
Рис. 3. Однополюсной автомат
При приобретении, вводные автоматические выключатели, лучше выбирать в надежных магазинах. А установку доверять специалистам.
Советы по выбору мощности стабилизатора
КАК ПРАВИЛЬНО ПОДОБРАТЬ МОЩНОСТЬ СТАБИЛИЗАТОРА НАПРЯЖЕНИЯ?
Одним из главных критериев при выборе стабилизатора является его мощность. Есть несколько способов выяснить, какая необходима мощность стабилизатора. В этой статье мы попытаемся доступно объяснить как выбрать стабилизатор напряжения.
Есть несколько способов выяснить, какая необходима мощность стабилизатора. В этой статье мы попытаемся доступно объяснить как выбрать стабилизатор напряжения.
СПОСОБ 1 – ПОДБОР СТАБИЛИЗАТОРА ПО ТОКУ ВВОДНОГО АВТОМАТА
В электрощите Вашего дома есть автоматический выключатель, который отключает весь дом. Такой автомат называется вводным. Как правило, вводной автомат расположен рядом с прибором учета электроэнергии (счетчиком) и ограничивает выделенную мощность, которую Вы можете потреблять.
Даже если в настоящее время Вы не потребляете всю выделенную мощность, то в будущем, Вы наверняка добавите оборудование. Стабилизатор, подобранный по току вводного автомата, не будет Вас ограничивать в мощности потребления.
Для наглядного примера выбора мощности стабилизатора предлагаем воспользоваться следующей таблицей:
таблица расчета мощности стабилизатора
Для однофазной сети |
| Для трехфазной сети | ||
ток вводного автомата | максимально возможная мощность |
| ток вводного автомата | максимально возможная мощность |
16А | 4 кВА | 16А | 12 кВА | |
25А | 6,4 кВА | 25А | 19,2кВА | |
32А | 8 кВА | 32А | 24 кВА | |
40А | 9,1 кВА | 40А | 27,3 кВА | |
50А | 12 кВА | 50А | 36 кВА | |
63А | 14 кВА | 63А | 42 кВА | |
| 80А | 54 кВА | ||
100А | 72 кВА | |||
125А | 91 кВА | |||
150А | 108 кВА | |||
200А | 144 кВА | |||
300А | 216 кВА | |||
400А | 288 кВА | |||
500А | 375 кВА | |||
Если номинал Вашего вводного автомата меньше, стабилизатор все равно можно установить, но при этом необходимо помнить, что при понижении напряжения, входной ток будет увеличиваться из-за потребляемого, т. е. если чайник без стабилизатора потреблял ток 10 А, то теперь во входной сети будет 15А (для соседей это будет выглядеть так, как будто Вы докупили еще пол-чайника).
е. если чайник без стабилизатора потреблял ток 10 А, то теперь во входной сети будет 15А (для соседей это будет выглядеть так, как будто Вы докупили еще пол-чайника).
Если ток превысит значение номинала вводного автомата, то автомат отключится.
ПОЛЕЗНЫЙ СОВЕТ: При замене автомата на более мощный, убедитесь, что сечение проводов позволяет это сделать.
Для простоты выбора стабилизатора напряжения по току вводного автомата, Вы можете посетить специализированный сайт СНПТО на котором доступно и интуитивно понятно реализован выбор стабилизаторов по необходимой мощности (по номиналу тока вводного автомата).
СПОСОБ 2 — ПОДБОР СТАБИЛИЗАТОРА ПОД МОЩНОСТЬ НАГРУЗОК
Как выбрать стабилизатор напряжения под мощность нагрузок — берем калькулятор и подсчитываем, какую мощность потребляют Ваши электроприборы в кВА (киловольт амперах).
При переводе потребляемой мощности из кВт в кВА ее номинал делится на специальный коэффициент cos ф.
Для потребителей, имеющих обмотки индуктивности (двигатели, компрессоры, дроссельные преобразователи и т. п.) этот коэффициент:
cos ф = 0,8;
в этом случае 1 кВА = 0,8 кВт.
Для потребителей, преобразующих электроэнергию напрямую в тепло (ламп накаливания, обогревателей, чайника, электроплиты, духовки и т.п.):
cos ф = 1;
тогда 1 кВА = 1 кВт.
В некоторых случаях для электроприборов с двигателями коэффициент может составлять:
cos ф = 0,65;
и тогда 1 кВА = 0,65 кВт.
Таких нагрузок, как правило, немного. Обычно двигатели этих приборов часто работают на холостых оборотах. Типичным примером является рабочий инструмент (электродрели, шлифовальные машины и др.)
Пример расчета мощности оборудования дачного дома
электроприборы | мощность в Вт | коэффициент (cos ф) | мощность в ВА |
лампы накаливания по 100 Вт (5 шт. | 500 | 1 | 500 |
скважинный насос | 1000 | 0,8 | 1250 |
электроплита | 2000 | 1 | 2000 |
чайник | 2000 | 1 | 2000 |
холодильник | 200 | 0,8 | 250 |
телевизор | 50 | 1 | 50 |
стиральная машина: тэн нагрева воды | 1500 | 1 | 1500 |
водонагреватель | 1200 | 1 | 1200 |
обогреватели 1500 Вт (3 шт.) | 4500 | 1 | 4500 |
газонокосилка триммер | 600 | 0,65 | 750 |
ИТОГОВАЯ МОЩНОСТЬ ПОТРЕБЛЕНИЯ | 14 500 | ||
 )
)
Рекомендуемая мощность стабилизатора: не ниже 14 500 ВА (14 500 ВольтАмпер, 14,5кВА), подходит стабилизатор СНПТО-18.
СПОСОБ 3 — ВЫЗОВ СПЕЦИАЛИСТА ДЛЯ ДИАГНОСТИКИ СЕТИ
Если Вы не хотите загружать себя калькулятором и расчетами для подбора мощности стабилизатора напряжения, — Вы можете вызвать нашего специалиста.
Опытный специалист не только подсчитает мощности нагрузки, но и оценит состояние местной электросети, произведет замеры потребляемого тока и напряжения, проведет осмотр электропроводки, подберет стабилизатор напряжения исходя из состояния местной электросети и характера нагрузки.
Для вызова специалиста магазина Электрокапризам – НЕТ!™, пожалуйста, обращайтесь по телефону: 044-587-94-49
Как выбрать автоматические выключатели для квартиры либо дома | samelectrik.ru
Если вы намерены самостоятельно собрать щиток после замены проводки или проложили новую линию, вам придется столкнуться с вопросом выбора автоматического выключателя. У автоматов есть две основные функции — защита проводки от короткого замыкания и от перегрузки.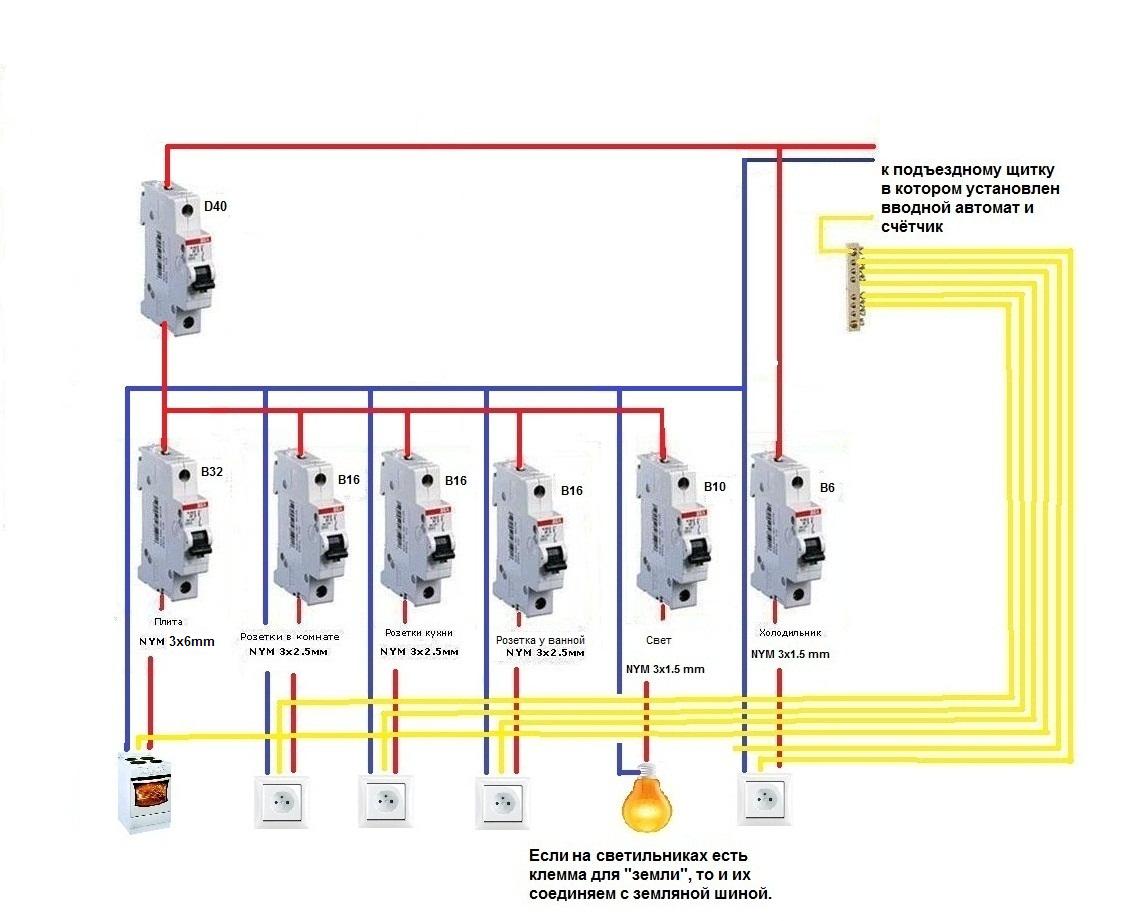 Неверный выбор автомата — прямая причина пожара.
Неверный выбор автомата — прямая причина пожара.
У автоматических выключателей есть несколько ключевых параметров, на которые нужно обратить внимание.
1. Номинальный ток, измеряется в амперах. Это значение, при достижении которого автомат сработает, то есть произойдет отключение цепи. Обычно автоматы бывают на 10, 16, 32, 40А и так далее. При выборе номинала действует нехитрое правило бывалых электриков: на каждый миллиметр сечения кабеля должно «приходиться» 10 ампер. То есть, например, при использовании кабеля сечением 1,5 мм нужен автомат на 10А — если получаются дробные значения, уменьшаем в меньшую сторону. Но лучше всего воспользоваться специальными таблицами, которые помогут выбрать и автомат в зависимости от сечения, и сечение в зависимости от уже имеющихся автоматов.
2. Ток срабатывания. Как правило, электрики выбирают для домашнего использования автоматы с током срабатывания классов B и С. Речь идет о том, как автомат будет себя вести при включении мощных электроприборов, когда пусковой ток может быть значительно выше номинального. Если вам нужно запустить двигатель электрического подъемника в гараже, то автомат не должно «выбить» из-за того, что пусковой ток он воспримет как аварийный режим работы проводки. Если планируете задействовать аппараты большой мощности, стоит задуматься о приобретении автоматов класса D.
Если вам нужно запустить двигатель электрического подъемника в гараже, то автомат не должно «выбить» из-за того, что пусковой ток он воспримет как аварийный режим работы проводки. Если планируете задействовать аппараты большой мощности, стоит задуматься о приобретении автоматов класса D.
3. Селективность. Она обеспечивает отключение в аварийной ситуации только определенного участка проводки, а не всей электроэнергии в доме. Здесь речь идет о последовательности установки автоматических выключателей. Номинальный ток вводного коммутационного аппарата должен превышать значение рабочего тока всех остальных, нижестоящих автоматических выключателей в щитке. Например, вводной автомат в доме имеет номинал 40А, на розетки стоят автоматы номинал 16А, а на освещение — 10А. При таком распределении условие селективности будет удовлетворено.
4. Количество полюсов. Для однофазной сети 220 В на ввод рекомендуется выбрать двухполюсный однофазный автомат. Если в дом приходит трехфазная электросеть, на ввод купите четырехполюсный коммутационный аппарат. На розетки и освещение ставятся однополюсные автоматы (разрывается фаза, ноль идет напрямую на нулевую шину и от шины к потребителям). С количеством полюсов разберется любой.
На розетки и освещение ставятся однополюсные автоматы (разрывается фаза, ноль идет напрямую на нулевую шину и от шины к потребителям). С количеством полюсов разберется любой.
5. Завод-изготовитель. Это одна из ключевых характеристик, так как автоматы от плохого производителя могут просто не сработать, что спровоцирует пожар. В Интернете есть масса таблиц с перечислением проверенных производителей, также можно почитать отзывы.
Что нужно помнить при выборе автомата? Ориентируйтесь не на мощность бытовой техники, а на электропроводку и сечение кабеля. Если вы намерены подключить обогреватель мощностью в 2 киловатта на кабель сечением 1,5 мм и надеетесь, что вас защитит автомат на 20А, то вы ошибаетесь — проводка просто загорится, а автомат так и не сработает.
В целом приняты следующие схемы: для освещения используется кабель 1,5 мм и автоматы 10А, для розеток — кабель 2,5 мм и автоматы на 16А. Все остальное рассчитывается по таблице, указанной выше. При таком раскладе безопасность проводке вне сомнений.
При таком раскладе безопасность проводке вне сомнений.
Также желательно подобрать всю автоматику от одного, качественного производителя. Вы сведете к нулю вероятность несоответствия, а также сможете без проблем смонтировать какое-либо дополнительное оборудование, например, шины-гребенки.
Введение в машинное обучение для начинающих | автор: Ayush Pant
Мы видели машинное обучение как модное слово в последние несколько лет, причиной этого может быть большой объем данных, производимых приложениями, увеличение вычислительной мощности за последние несколько лет и разработка более совершенных алгоритмов. .
Машинное обучение используется повсюду, от автоматизации рутинных задач до интеллектуального анализа, отрасли в каждом секторе пытаются извлечь из этого выгоду. Возможно, вы уже используете устройство, которое его использует.Например, носимый фитнес-трекер, такой как Fitbit, или умный домашний помощник, такой как Google Home. Но примеров использования машинного обучения гораздо больше.
- Прогнозирование. Машинное обучение также можно использовать в системах прогнозирования. Рассматривая пример ссуды, чтобы вычислить вероятность неисправности, системе потребуется классифицировать доступные данные по группам.
- Распознавание изображений. Машинное обучение также можно использовать для распознавания лиц на изображении. В базе из нескольких человек есть отдельная категория для каждого человека.
- Распознавание речи — это перевод произнесенных слов в текст. Он используется в голосовом поиске и многом другом. Голосовые пользовательские интерфейсы включают голосовой набор, маршрутизацию вызовов и управление устройствами. Также может быть использован простой ввод данных и подготовка структурированных документов.
- Медицинские диагнозы — ML обучен распознавать раковые ткани.
- Финансовая промышленность и торговля — компании используют ОД при расследовании мошенничества и проверках кредитоспособности.
В 1940-х годах была изобретена первая компьютерная система с ручным управлением, ENIAC (электронный числовой интегратор и компьютер).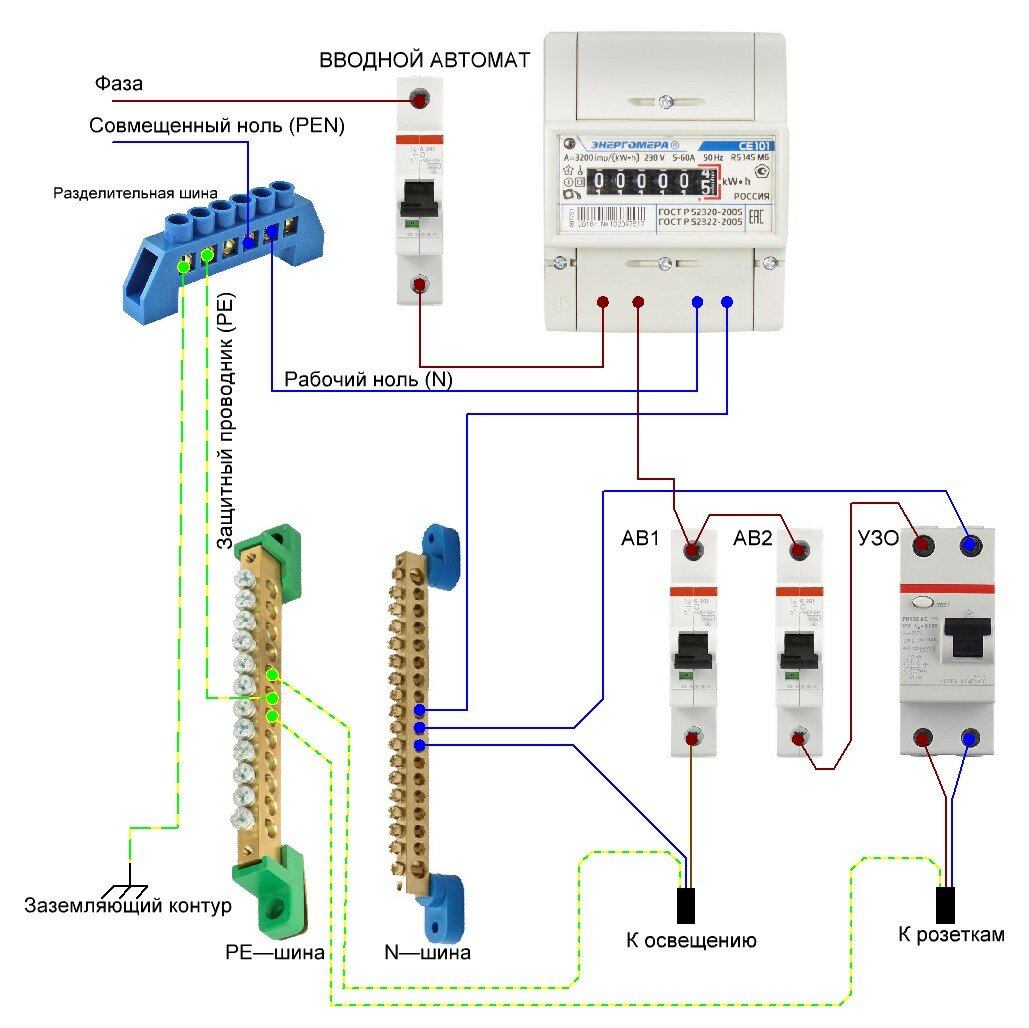 В то время слово «компьютер» использовалось как имя человека с интенсивными вычислительными возможностями, поэтому ENIAC называли вычислительной машиной! Что ж, вы можете сказать, что это не связано с обучением ?! НЕПРАВИЛЬНО, с самого начала идея заключалась в создании машины, способной имитировать человеческое мышление и обучение.
В то время слово «компьютер» использовалось как имя человека с интенсивными вычислительными возможностями, поэтому ENIAC называли вычислительной машиной! Что ж, вы можете сказать, что это не связано с обучением ?! НЕПРАВИЛЬНО, с самого начала идея заключалась в создании машины, способной имитировать человеческое мышление и обучение.
В 1950-х годах мы видим первую компьютерную игровую программу, которая заявляла, что может победить чемпиона мира по шашкам.Эта программа очень помогла шашистам в улучшении их навыков! Примерно в то же время Фрэнк Розенблатт изобрел персептрон, который был очень и очень простым классификатором, но когда он был объединен в большом количестве в сеть, он стал могущественным монстром. Что ж, монстр относительно времени, и для того времени это был настоящий прорыв. Затем мы видим несколько лет стагнации поля нейронной сети из-за ее трудностей в решении определенных задач.
Благодаря статистике машинное обучение стало очень известным в 1990-х годах.Пересечение информатики и статистики породило вероятностные подходы в искусственном интеллекте. Это еще больше сдвинуло поле зрения к подходам, основанным на данных. Имея доступ к крупномасштабным данным, ученые начали создавать интеллектуальные системы, способные анализировать и извлекать уроки из больших объемов данных. Следует отметить, что система IBM Deep Blue обыграла чемпиона мира по шахматам, гроссмейстера Гарри Каспарова. Да, я знаю, что Каспаров обвинил IBM в мошенничестве, но теперь это часть истории, и Deep Blue мирно отдыхает в музее.
По словам Артура Самуэля, алгоритмы машинного обучения позволяют компьютерам учиться на основе данных и даже улучшать себя без явного программирования.
Машинное обучение (ML) — это категория алгоритмов, которые позволяют программным приложениям более точно прогнозировать результаты без явного программирования. Основная предпосылка машинного обучения — создание алгоритмов, которые могут получать входные данные и использовать статистический анализ для прогнозирования выходных данных при обновлении выходных данных по мере появления новых данных.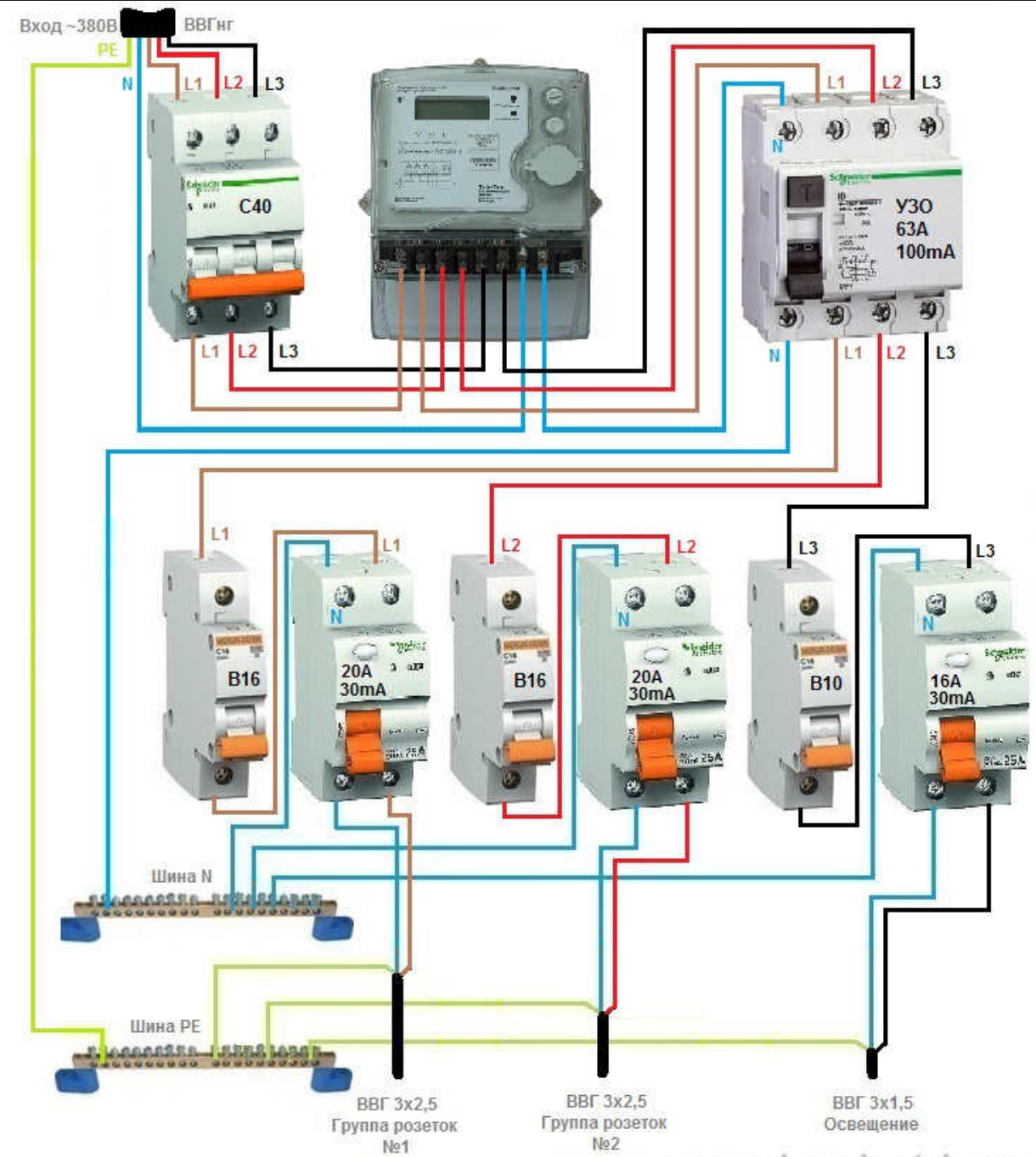
Машинное обучение можно разделить на 3 типа алгоритмов.
- Контролируемое обучение — [Ссылка скоро появится в будущем блоге]
- Неконтролируемое обучение — [Ссылка скоро появится в будущем блоге]
- Обучение с подкреплением — [Ссылка скоро появится в будущем блоге]
В контролируемом обучении система ИИ представлена данными, которые помечены, что означает, что все данные помечены правильной меткой.
Цель состоит в том, чтобы аппроксимировать функцию отображения настолько хорошо, чтобы при наличии новых входных данных (x) можно было предсказать выходные переменные (Y) для этих данных.
Пример контролируемого обученияКак показано в приведенном выше примере, мы изначально взяли некоторые данные и пометили их как «Спам» или «Не спам». Эти помеченные данные используются контролируемой обучающей моделью, эти данные используются для обучения модели.
После обучения мы можем протестировать нашу модель, проверив ее с помощью нескольких тестовых новых писем, и проверка модели может предсказать правильный результат.
Типы обучения с учителем
- Классификация : Проблема классификации возникает, когда выходной переменной является категория, например «красный» или «синий» или «болезнь» и «отсутствие болезни».
- Регрессия : проблема регрессии возникает, когда выходная переменная представляет собой реальное значение, такое как «доллары» или «вес».
При обучении без учителя система искусственного интеллекта представлена немаркированными, неклассифицированными данными, и алгоритмы системы воздействуют на данные без предварительного обучения. Выход зависит от закодированных алгоритмов. Подвергнуть систему обучению без учителя — один из способов тестирования ИИ.
Пример обучения без учителя В приведенном выше примере мы присвоили нашей модели некоторые символы: «Утки» и «Не утки».В наших обучающих данных мы не даем никаких ярлыков для соответствующих данных. Неконтролируемая модель может разделять обоих персонажей, глядя на тип данных и моделируя базовую структуру или распределение в данных, чтобы узнать о них больше.
Типы обучения без учителя
- Кластеризация : проблема кластеризации заключается в том, что вы хотите обнаружить присущие им группировки данных, такие как группировка клиентов по покупательскому поведению.
- Ассоциация : проблема изучения правил ассоциации — это когда вы хотите обнаружить правила, которые описывают большие части ваших данных, например, люди, которые покупают X, также склонны покупать Y.
Алгоритм обучения с подкреплением, или агент, обучается, взаимодействуя со своей средой. Агент получает вознаграждение за правильное выполнение и штрафы за неправильное выполнение. Агент учится без вмешательства человека, максимизируя свое вознаграждение и минимизируя штрафы. Это тип динамического программирования, который обучает алгоритмы с использованием системы вознаграждения и наказания.
Пример обучения с подкреплением В приведенном выше примере мы видим, что агенту даны 2 варианта: i.е. путь с водой или путь с огнем. Алгоритм подкрепления работает с системой вознаграждения, то есть, если агент использует путь огня, тогда награды вычитаются, и агент пытается узнать, что он должен избегать пути огня. Если бы он выбрал водный путь или безопасный путь, тогда к бонусным баллам добавлялись бы некоторые баллы, после чего агент пытался бы узнать, какой путь безопасен, а какой нет.
Алгоритм подкрепления работает с системой вознаграждения, то есть, если агент использует путь огня, тогда награды вычитаются, и агент пытается узнать, что он должен избегать пути огня. Если бы он выбрал водный путь или безопасный путь, тогда к бонусным баллам добавлялись бы некоторые баллы, после чего агент пытался бы узнать, какой путь безопасен, а какой нет.
По сути, агент использует полученные награды, улучшая свои знания о среде, чтобы выбрать следующее действие.
В этом блоге я представил вам основные концепции машинного обучения, и я надеюсь, что этот блог был полезен и мотивировал вас достаточно, чтобы заинтересоваться этой темой.
Начните с машинного обучения
Это пошаговые инструкции, которые вы так долго искали!
С чем вам нужна помощь?
Как мне начать?
Самый частый вопрос, который мне задают: «, как мне начать? ”
Мой лучший совет по началу работы с машинным обучением состоит из 5 этапов:
- Шаг 1 : Настройка мышления . Поверьте, вы можете практиковать и применять машинное обучение.
- Шаг 2 : Выберите процесс . Используйте системный процесс для решения проблем.
- Шаг 3 : Выберите инструмент . Выберите инструмент для вашего уровня и сопоставьте его со своим процессом.
- Шаг 4 : Практика на наборах данных . Выберите наборы данных, над которыми будете работать, и потренируйтесь в процессе.
- Шаг 5 : Создайте портфель . Соберите результаты и продемонстрируйте свои навыки.
 Поверьте, вы можете практиковать и применять машинное обучение.
Поверьте, вы можете практиковать и применять машинное обучение.Подробнее об этом нисходящем подходе см .:
Многие из моих студентов использовали этот подход, чтобы продолжить и преуспеть в соревнованиях Kaggle и получить работу инженеров по машинному обучению и специалистов по обработке данных.
Процесс прикладного машинного обучения
Преимущество машинного обучения — это прогнозы и модели, которые делают прогнозы.
Владение навыками прикладного машинного обучения означает знание того, как последовательно и надежно предоставлять высококачественные прогнозы от проблемы к проблеме.Вам нужно следовать систематическому процессу.
Ниже приведен 5-этапный процесс, которому вы можете следовать, чтобы постоянно достигать результатов выше среднего по задачам прогнозного моделирования:
- Шаг 1 : Определите вашу проблему.
- Шаг 2 : Подготовьте данные.
- Шаг 3 : Алгоритмы выборочной проверки.
- Шаг 4 : Улучшение результатов.
- Шаг 5 : Представьте результаты.
Подробное описание этого процесса см. В сообщениях:
Вероятность для машинного обучения
Вероятность — это математика количественной оценки и использования неопределенности.Это основа многих областей математики (например, статистики) и критически важна для прикладного машинного обучения.
Ниже приведен трехэтапный процесс, который вы можете использовать для быстрого повышения скорости с вероятностью для машинного обучения.
- Шаг 1 : Узнайте, что такое вероятность.
- Шаг 2 : Узнайте, почему вероятность так важна для машинного обучения.
- Шаг 3 : Погрузитесь в темы вероятностей.
Здесь вы можете увидеть все руководства по вероятности.Ниже приведены некоторые из самых популярных руководств.
Основания вероятности
Теорема Байеса
Распределения вероятностей
Теория информации
Статистика для машинного обучения
Статистические методы — важная фундаментальная область математики, необходимая для более глубокого понимания поведения алгоритмов машинного обучения.
Ниже приведен трехэтапный процесс, который вы можете использовать, чтобы быстро освоить статистические методы машинного обучения.
- Шаг 1 : Узнайте, что такое статистические методы.
- Шаг 2 : Узнайте, почему статистические методы важны для машинного обучения.
- Шаг 3 : Погрузитесь в темы статистических методов.
Здесь вы можете увидеть все публикации о статистических методах. Ниже приведены некоторые из самых популярных руководств.
Сводная статистика
Статистические проверки гипотез
Методы передискретизации
Оценка статистики
Линейная алгебра для машинного обучения
Линейная алгебра — важная фундаментальная область математики, необходимая для более глубокого понимания алгоритмов машинного обучения.
Ниже приведен трехэтапный процесс, который вы можете использовать, чтобы быстро освоить линейную алгебру для машинного обучения.
- Шаг 1 : Узнайте, что такое линейная алгебра.
- Шаг 2 : Узнайте, почему линейная алгебра важна для машинного обучения.
- Шаг 3 : Погрузитесь в темы линейной алгебры.
Здесь вы можете увидеть все сообщения по линейной алгебре. Ниже приведены некоторые из самых популярных руководств.
Линейная алгебра в Python
Матрицы
Векторы
Факторизация матрицы
Оптимизация для машинного обучения
Оптимизация — это ядро всех алгоритмов машинного обучения.Когда мы обучаем модель машинного обучения, она оптимизирует данный набор данных.
Вы можете быстро освоить оптимизацию для машинного обучения за 3 шага.
- Шаг 1 : Узнайте, что такое оптимизация.
- Шаг 2 : Откройте для себя алгоритмы оптимизации.
- Шаг 3 : Погрузитесь в темы оптимизации.
Здесь вы можете увидеть все сообщения по оптимизации. Ниже приведены некоторые из самых популярных руководств.
Локальная оптимизация
Глобальная оптимизация
Градиентный спуск
Приложения оптимизации
Понимание алгоритмов машинного обучения
Машинное обучение — это алгоритмы машинного обучения.
Вам необходимо знать, какие алгоритмы доступны для данной проблемы, как они работают и как получить от них максимальную отдачу.
Вот как начать работу с алгоритмами машинного обучения:
- Шаг 1 : Откройте для себя различные типы алгоритмов машинного обучения.
- Шаг 2 : Откройте для себя основы алгоритмов машинного обучения.
- Шаг 3 : Узнайте, как работают лучшие алгоритмы машинного обучения.
Здесь вы можете увидеть все сообщения об алгоритмах машинного обучения. Ниже приведены некоторые из самых популярных руководств.
Линейные алгоритмы
Нелинейные алгоритмы
Ансамблевые алгоритмы
Как изучать / изучать алгоритмы машинного обучения
Машинное обучение Weka (без кода)
Weka — это платформа, которую вы можете использовать для начала работы в прикладном машинном обучении.
Он имеет графический пользовательский интерфейс, что означает отсутствие необходимости в программировании, и предлагает набор современных алгоритмов.
Вот как начать работу с Weka:
- Шаг 1 : Откройте для себя возможности платформы Weka.
- Шаг 2 : Узнайте, как обойти платформу Weka.
- Step 3 : Узнайте, как добиться результатов с помощью Weka.
Здесь вы можете увидеть все сообщения Weka о машинном обучении.Ниже приведены некоторые из самых популярных руководств.
Машинное обучение Python (scikit-learn)
Python — одна из самых быстрорастущих платформ для прикладного машинного обучения.
Вы можете использовать те же инструменты, как pandas и scikit-learn, при разработке и оперативном развертывании вашей модели.
Ниже приведены шаги, которые можно использовать для начала работы с машинным обучением Python:
- Шаг 1 : Откройте для себя Python для машинного обучения
- Шаг 2 : Откройте для себя экосистему машинного обучения Python.
- Шаг 3 : Узнайте, как решать проблемы с помощью машинного обучения в Python.
Здесь вы можете увидеть все сообщения о машинном обучении Python. Ниже приведены некоторые из самых популярных руководств.
Машинное обучение на Python
R Машинное обучение (курсор)
R — это платформа для статистических вычислений и самая популярная платформа среди профессиональных специалистов по данным.
Он популярен из-за большого количества доступных методов и из-за отличных интерфейсов для этих методов, таких как мощный пакет каретки.
Вот как начать работу с машинным обучением R:
- Шаг 1 : Откройте для себя платформу R и ее популярность.
- Шаг 2 : Откройте для себя алгоритмы машинного обучения в R.
- Шаг 3 : Узнайте, как решать проблемы с помощью машинного обучения в R.
Здесь вы можете увидеть все сообщения о машинном обучении R. Ниже приведены некоторые из самых популярных руководств.
Прикладное машинное обучение в рублях
Алгоритм кода с нуля (Python)
Вы можете многое узнать об алгоритмах машинного обучения, написав их с нуля.
Обучение через кодирование — предпочтительный стиль обучения для многих разработчиков и инженеров.
Вот как начать машинное обучение, написав все с нуля.
- Шаг 1 : Откройте для себя преимущества алгоритмов кодирования с нуля.
- Шаг 2 : Узнайте, что алгоритмы кодирования с нуля — это только средство обучения.
- Шаг 3 : Узнайте, как с нуля кодировать алгоритмы машинного обучения на Python.
Здесь вы можете увидеть все сообщения «Алгоритмы кода с нуля». Ниже приведены некоторые из самых популярных руководств.
Подготовить данные
Линейные алгоритмы
Оценка алгоритма
Нелинейные алгоритмы
Введение в прогнозирование временных рядов (Python)
Прогнозирование временных рядов — важная тема в бизнес-приложениях.
Многие наборы данных содержат компонент времени, но тема временных рядов редко рассматривается подробно с точки зрения машинного обучения.
Вот как начать работу с прогнозированием временных рядов:
- Шаг 1 : Откройте для себя прогнозирование временных рядов.
- Шаг 2 : Откройте для себя временные ряды как контролируемое обучение.
- Шаг 3 : Узнайте, как добиться хороших результатов с помощью прогнозирования временных рядов.
Здесь вы можете увидеть все сообщения о прогнозировании временных рядов. Ниже приведены некоторые из самых популярных руководств.
Руководства по подготовке данных
Подготовка данных для машинного обучения (Python)
Эффективность вашей прогнозной модели зависит от данных, которые вы используете для ее обучения.
Таким образом, подготовка данных может стать наиболее важной частью вашего проекта прикладного машинного обучения.
Вот как начать работу с подготовкой данных для машинного обучения:
- Шаг 1 : Откройте для себя важность подготовки данных.
- Шаг 2 : Откройте для себя методы подготовки данных.
- Шаг 3 : Узнайте, как добиться хороших результатов с помощью подготовки данных.
Здесь вы можете увидеть все руководства по подготовке данных.Ниже приведены некоторые из самых популярных руководств.
Очистка данных
Выбор функций
Преобразование данных
Уменьшение размерности
XGBoost в Python (повышение стохастического градиента)
XGBoost — это высокооптимизированная реализация деревьев решений с градиентным усилением.
Он популярен, потому что его используют одни из лучших специалистов по данным в мире для победы в соревнованиях по машинному обучению.
Вот как начать работу с XGBoost:
- Шаг 1 : Откройте для себя алгоритм повышения градиента.
- Шаг 2 : Откройте для себя XGBoost.
- Шаг 3 : Узнайте, как добиться хороших результатов с помощью XGBoost.
Здесь вы можете увидеть все сообщения XGBoosts. Ниже приведены некоторые из самых популярных руководств.
Несбалансированная классификация
Несбалансированная классификация относится к задачам классификации, в которых существует намного больше примеров для одного класса, чем для другого класса.
Проблемы такого типа часто требуют использования специализированных показателей производительности и алгоритмов обучения, поскольку стандартные показатели и методы ненадежны или полностью выходят из строя.
Вот как вы можете начать работу с несбалансированной классификацией:
- Шаг 1 : Откройте для себя проблему несбалансированной классификации
- Шаг 2 : Откройте для себя интуицию для искаженного распределения классов.
- Шаг 3 : Узнайте, как решить проблемы несбалансированной классификации.
Здесь вы можете увидеть все сообщения о несбалансированной классификации. Ниже приведены некоторые из самых популярных руководств.
Показатели эффективности
Чувствительные к стоимости алгоритмы
Выборка данных
Продвинутые методы
Глубокое обучение (Керас)
Глубокое обучение — увлекательная и мощная область.
Современные результаты получены в области глубокого обучения, и это подраздел машинного обучения, который нельзя игнорировать.
Вот как начать работу с глубоким обучением:
- Шаг 1 : Узнайте, что такое глубокое обучение.
- Step 2 : Откройте для себя лучшие инструменты и библиотеки.
- Шаг 3 : Узнайте, как справляться с проблемами и добиваться результатов.
Здесь вы можете увидеть все сообщения о глубоком обучении. Ниже приведены некоторые из самых популярных руководств.
Фон
Многослойные персептроны
Сверточные нейронные сети
Рекуррентные нейронные сети
Повышение эффективности глубокого обучения
Несмотря на то, что модель нейронной сети с глубоким обучением легко определить и подогнать под нее, добиться хорошей производительности при решении конкретной задачи прогнозного моделирования может быть непросто.
Существуют стандартные методы, которые вы можете использовать для улучшения обучения, уменьшения переобучения и улучшения прогнозов с помощью вашей модели глубокого обучения.
Вот как начать повышать эффективность глубокого обучения:
- Шаг 1 : Откройте для себя проблему глубокого обучения.
- Шаг 2 : Откройте для себя основы диагностики и повышения производительности модели.
- Шаг 3 : Откройте для себя методы, которые можно использовать для повышения производительности.
Здесь вы можете увидеть все лучшие публикации по глубокому обучению. Ниже приведены некоторые из самых популярных руководств.
Better Learning (исправить обучение)
Лучшее обобщение (исправление переобучения)
Лучшие прогнозы (ансамбли)
Советы, уловки и ресурсы
Ансамблевое обучение
Прогнозирующая производительность — самая важная проблема для многих задач классификации и регрессии. Алгоритмы обучения ансамбля объединяют прогнозы из нескольких моделей и предназначены для работы лучше, чем любой участвующий член ансамбля.
Вот как начать повышать эффективность ансамблевого обучения:
- Шаг 1 : Откройте для себя ансамблевое обучение.
- Шаг 2 : Откройте для себя алгоритмы ансамблевого обучения.
- Шаг 3 : Откройте для себя методы, которые можно использовать для повышения производительности.
Здесь вы можете увидеть все статьи по ансамблевому обучению. Ниже приведены некоторые из самых популярных руководств.
Основы ансамбля
Укладка ансамблей
Комплекты для упаковки в мешки
Повышающие ансамбли
Сети с долговременной краткосрочной памятью (LSTM)
Рекуррентные нейронные сетис долгосрочной краткосрочной памятью (LSTM) предназначены для решения задач прогнозирования последовательности и представляют собой современный метод глубокого обучения для решения сложных задач прогнозирования.
Вот как начать работу с LSTM в Python:
- Шаг 1 : Откройте для себя перспективы LSTM.
- Шаг 2 : Узнайте, где можно использовать LSTM.
- Шаг 3 : Узнайте, как использовать LSTM в своем проекте.
Здесь вы можете увидеть все сообщения LSTM. Ниже приведены некоторые из самых популярных руководств по использованию LSTM в Python с библиотекой глубокого обучения Keras.
Подготовка данных для LSTM
Поведение LSTM
Моделирование с помощью LSTM
LSTM для временных рядов
Глубокое обучение для обработки естественного языка (NLP)
Работа с текстовыми данными затруднена из-за беспорядочного естественного языка.
Текст не «решен», но для получения современных результатов по сложным задачам НЛП вам необходимо использовать методы глубокого обучения.
Вот как начать работу с глубоким обучением для обработки естественного языка:
- Шаг 1 : Узнайте, что такое глубокое обучение для НЛП.
- Шаг 2 : Откройте для себя стандартные наборы данных для НЛП.
- Шаг 3 : Узнайте, как справляться с проблемами и добиваться результатов.
Здесь вы можете увидеть все сообщения о глубоком обучении для НЛП.Ниже приведены некоторые из самых популярных руководств.
Сумка со словами Модель
Моделирование языка
Обобщение текста
Классификация текста
Вложения слов
Подписи к фотографиям
Перевод текста
Глубокое обучение для компьютерного зрения
Работа с данными изображения затруднена из-за разницы между необработанными пикселями и смыслом изображений.
Компьютерное зрение не решено, но для получения современных результатов при решении сложных задач компьютерного зрения, таких как обнаружение объектов и распознавание лиц, вам нужны методы глубокого обучения.
Вот как начать работу с глубоким обучением для компьютерного зрения:
- Шаг 1 : Узнайте, что такое глубокое обучение для компьютерного зрения.
- Шаг 2 : Откройте для себя стандартные задачи и наборы данных для компьютерного зрения.
- Шаг 3 : Узнайте, как справляться с проблемами и добиваться результатов.
Здесь вы можете увидеть все сообщения о глубоком обучении для компьютерного зрения. Ниже приведены некоторые из самых популярных руководств.
Обработка данных изображения
Увеличение данных изображения
Классификация изображений
Подготовка данных изображения
Основы сверточных нейронных сетей
Распознавание объекта
Глубокое обучение для прогнозирования временных рядов
Нейронные сети с глубоким обучением могут автоматически изучать произвольные сложные сопоставления от входов к выходам и поддерживать несколько входов и выходов.
Такие методы, как MLP, CNN и LSTM, предлагают многообещающие возможности для прогнозирования временных рядов.
Вот как начать работу с глубоким обучением для прогнозирования временных рядов:
- Шаг 1 : Откройте для себя перспективы (и ограничения) глубокого обучения для временных рядов.
- Шаг 2 : Узнайте, как разработать надежные базовые и оправданные модели прогнозирования.
- Шаг 3 : Узнайте, как создавать модели глубокого обучения для прогнозирования временных рядов.
Здесь вы можете увидеть все сообщения о глубоком обучении для прогнозирования временных рядов.Ниже приведены некоторые из самых популярных руководств.
Тенденции прогнозов и сезонность (одномерный)
Распознавание человеческой деятельности (многомерная классификация)
Прогноз использования электроэнергии (многомерный, многоступенчатый)
Типы моделей
Примеры из практики временных рядов
Прогноз загрязнения воздуха (многомерный, многоступенчатый)
Генеративные состязательные сети (GAN)
Generative Adversarial Networks, или сокращенно GAN, — это подход к генеративному моделированию с использованием методов глубокого обучения, таких как сверточные нейронные сети.
СетиGAN — это захватывающая и быстро меняющаяся область, которая оправдывает обещание генеративных моделей в их способности генерировать реалистичные примеры по ряду проблемных областей, в первую очередь в задачах преобразования изображения в изображение.
Вот как начать работу с глубоким обучением для генеративных состязательных сетей:
- Шаг 1 : Откройте для себя перспективы GAN для генеративного моделирования.
- Шаг 2 : Откройте для себя архитектуру GAN и различные модели GAN.
- Шаг 3 : Узнайте, как разрабатывать модели GAN на Python с помощью Keras.
Здесь вы можете увидеть все руководства по Generative Adversarial Network. Ниже приведены некоторые из самых популярных руководств.
Основы GAN
Функции потерь GAN
Разработка простых моделей GAN
GAN для перевода изображений
Нужна дополнительная помощь?
Я здесь, чтобы помочь вам стать мастером прикладного машинного обучения.
Если у вас остались вопросы и вам нужна помощь, у вас есть несколько вариантов:
- Электронные книги : Я продаю каталог электронных книг, которые показывают, как быстро добиться результатов с помощью машинного обучения.
- Блог : Я много пишу в блоге о прикладном машинном обучении, попробуйте функцию поиска.
- Часто задаваемые вопросы : Самые частые вопросы, которые я получаю, и ответы на них
- Свяжитесь с : Вы можете связаться со мной, чтобы задать свой вопрос, но, пожалуйста, по одному вопросу за раз.
15-минутное руководство по выбору эффективных курсов машинного обучения и анализа данных
Мотивация
Билл Гейтс провозгласил на недавней церемонии вручения дипломов, что искусственный интеллект (ИИ), энергетика и биология — три самых захватывающих и вознаграждающих выбора карьеры, из которых могут выбирать современные молодые выпускники колледжей.
Не могу с этим согласиться.
Я твердо убежден в том, что некоторые из самых важных вопросов нашего поколения — связанные с устойчивостью, выработкой и распределением энергии, транспортом, доступом к основным жизненным удобствам и т. Д., зависят от того, насколько разумно мы можем смешать первые две ветви знания, о которых упоминает г-н Гейтс.
Другими словами, мир физической электроники (полупроводниковая промышленность составляет центральную часть этого мира) должен делать больше, чтобы полностью охватить плоды информационных технологий и новые разработки в области искусственного интеллекта или науки о данных.
Хотел узнать, но с чего начать?
Я профессионал в области полупроводников с более чем 8-летним опытом работы в ведущей технологической компании после получения докторской степени.Я горжусь тем, что работаю в области физической электроники, которая вносит непосредственный вклад в энергетический сектор. Разрабатываю силовые полупроводниковые приборы. Они созданы для эффективной и надежной передачи электроэнергии, и они питают все, от крошечного датчика внутри вашего смартфона до больших промышленных приводов двигателей, которые перерабатывают пищу или ткань для повседневного потребления.
Поэтому, естественно, я хочу изучить и применить методы современной науки о данных и машинного обучения для улучшения конструкции, надежности и работы таких устройств и систем.
Но я не выпускник информатики. Я не мог отличить связанный список от кучи. Машины опорного вектора звучали как (несколько месяцев назад) какое-то специальное оборудование для людей с ограниченными возможностями. И единственное ключевое слово ИИ, которое я запомнил (из моего факультативного курса первого года обучения), было « исчисление предикатов первого порядка », остаток так называемого « старого AI » или подхода инженерии знаний , в отличие от подхода к инженерии знаний. новый подход, основанный на машинном обучении.
Мне нужно было где-то начинать изучать основы, а затем углубляться в изучение.Очевидным выбором был MOOC (Массовые открытые онлайн-курсы). Я все еще нахожусь в стадии обучения, но считаю, что я, по крайней мере, накопил хороший опыт в выборе правильного MOOC для этого пути. В этой статье я хотел поделиться своими мыслями об этом аспекте.
Знай свое «Чи» и своего «врага»
Извините за плохую аналогию 🙂 Это из последней саги о супергероях Netlfix — Защитники.
Но это правда, что вы должны очень хорошо знать свои сильные и слабые стороны и технические склонности, прежде чем начинать процесс обучения через MOOC.
Потому что, давайте посмотрим правде в глаза, время и энергия ограничены, и вы не можете позволить себе тратить свои драгоценные ресурсы на то, что вряд ли будете практиковать на текущей или будущей работе. И это при условии, что вы хотите пройти курс обучения (почти) бесплатно, то есть проводить аудит МООК, а не платить за сертификаты . У меня там есть « почти », потому что в конце этой статьи я хотел бы перечислить несколько MOOC, за которые, как мне кажется, вы должны заплатить, чтобы продемонстрировать сертификаты.И в моем личном путешествии мне пришлось заплатить за несколько курсов Udemy, которые я выбрал, потому что они никогда не бывают бесплатными, но вы можете купить их по цене хорошего бутерброда на ланч, когда проводится акция.
Чему можно и чего нельзя научиться на МООК
На этой картинке я просто хочу показать возможности и невозможность этого процесса, то есть то, что вы можете надеяться узнать посредством самообучения и практики, и чему нужно научиться на работе, или какой образ мышления необходимо развивать, независимо от того, какой у вас профессия есть.При этом, однако, эти круги в целом охватывают основные навыки, которые можно изучить, чтобы заняться наукой о данных / машинным обучением, не имея опыта работы в CS. Обратите внимание, что даже если вы работаете в секторе информационных технологий (ИТ), вам, возможно, предстоит крутая кривая обучения, потому что эти новые области разрушают традиционные ИТ, а основные навыки и передовой опыт часто отличаются.
Я, например, считаю область науки о данных более демократичной, чем многие другие профессиональные области (например,грамм. моя собственная область работы в области полупроводниковых технологий), где входной барьер невысок и при достаточном усердии и рвении каждый может приобрести значимые навыки. Лично у меня нет горячего желания «прорваться» в эту область, скорее, у меня просто есть страсть позаимствовать плоды, чтобы применить их в своей области знаний. Однако эта конечная цель не влияет на начальную кривую обучения, которую нужно пройти. Итак, вы могли бы стать инженером по обработке данных, бизнес-аналитиком, специалистом по машинному обучению или экспертом по визуализации — область и возможности для выбора широко открыты.И если ваша цель такая же, как у меня — оставаться в текущей области знаний и применять недавно изученные методы — у вас тоже все в порядке.
Можно начинать с настоящих основ, ничего страшного 🙂
Я начал с реального базового уровня — изучаю Python на Codeacademy . По всей видимости, вы не можете пойти более элементарно :-). Но это сработало. У меня было отвращение к программированию, но простой и увлекательный интерфейс и правильный темп бесплатного курса Codeacademy были подходящими, чтобы взволновать меня достаточно, чтобы продолжить.Я мог бы выбрать курс Java или C ++ на Coursera, Datacamp или Udacity, но некоторые чтения и исследования показали мне, что Python — оптимальный выбор, уравновешивающий сложность обучения и полезность (особенно для науки о данных), и я решил довериться этой идее.
Через некоторое время вы захотите получить более глубокие знания (, но в небольшом темпе)
ВведениеCodeacademy стало хорошей отправной точкой. У меня был выбор из множества онлайн-платформ MOOC, и, как и ожидалось, я записался на несколько курсов одновременно.Однако после нескольких дней занятий на Coursera я понял, что недостаточно готов, чтобы изучать Python у профессора! Я искал курс, преподаваемый каким-то увлеченным инструктором, который потратит время, чтобы подробно изучить концепции, научить меня другим важным инструментам, таким как система блокнотов Git и Jupyter, и поддерживать правильный баланс между базовыми концепциями и продвинутыми темами в учебной программе. . И я нашел подходящего человека для этой работы: Хосе Марсиаль Портилья. Он предлагает несколько курсов на Udemy и является одним из самых популярных и получивших положительные отзывы инструкторов на этой платформе.Я зарегистрировался и прошел его курс Python Bootcamp . Это было потрясающее введение в язык с правильным темпом, глубиной и строгостью. Я настоятельно рекомендую этот курс для новых учеников, даже если вам придется выложить 10 долларов (курсы Udemy, как правило, не бесплатны, и их обычная цена составляет 190 или 200 долларов, но вы всегда можете подождать несколько дней, чтобы пройти цикл периодической акции и подписаться на 10 долларов. или 15 долларов США).
Важно сосредоточиться на науке о данных
Следующий шаг оказался для меня решающим.Я мог сбиться с пути и попытаться изучить все, что мог, на Python. В частности, объектно-ориентированная часть и часть определения классов, которая легко может затянуть вас в долгом и трудном путешествии. Теперь, не отвлекаясь от этой ключевой области вселенной Python, можно с уверенностью сказать, что вы можете практиковать глубокое обучение и хорошую науку о данных, не имея возможности определять свой собственный класс и методы в Python. Одной из фундаментальных причин постоянно растущей популярности Python как фактического языка, предпочитаемого для науки о данных, является доступность большого количества высококачественных, проверенных экспертами, написанных экспертами библиотек, классов и методов, которые только и ждут загрузки. в красивой упакованной форме и развернутой для бесшовной интеграции в ваш код.
Поэтому для меня было важно быстро перейти к пакетам и методам, наиболее широко используемым в науке о данных — NumPy, Pandas и Matplotlib.
Я познакомился с ними благодаря небольшому изящному курсу от edX. Несмотря на то, что большинство курсов по edX из университетов и строгих (и длинных ish) по своей природе, есть несколько коротких и более практических / менее теоретических курсов, предлагаемых технологическими компаниями, такими как Microsoft. Одна из них — Microsoft Professional Program in Data Science .Вы можете зарегистрироваться на любое количество курсов по этой программе. Однако я прошел только следующие курсы (и я намерен вернуться на другие курсы в будущем)
- Ориентация на науку о данных : Обсуждает повседневную жизнь типичного специалиста по данным и затрагивает основные навыки, которые, как ожидается, будут иметь в этой роли, а также базовое введение в составляющие предметы.
- Введение в Python для науки о данных : изучает основы Python — структуры данных, циклы, функции, а затем вводит NumPy , Matplotlib и Pandas .
- Введение в анализ данных с использованием Excel : Обучает основным и нескольким расширенным функциям анализа данных, построению графиков и инструментам с Excel (например, сводная таблица , power pivot и подключаемый модуль решателя ).
- Введение в R для науки о данных : знакомит с синтаксисом R, типами данных, векторными и матричными операциями, факторами, функциями, фреймами данных и графикой с помощью ggplot2 .
Хотя эти курсы представляют материал в элементарной форме и охватывают только самые основные примеры, их было достаточно, чтобы зажечь свечу! Боже, меня зацепило!
Перешел на изучение R подробно — с некоторого времени
Последний курс заставил меня осознать несколько важных вещей: (а) статистика и линейная алгебра лежат в основе процесса науки о данных, (б) я недостаточно знал / забыл об этом, и (в) R естественно подходит для та работа, которую я хочу проделать с моим набором данных — данные размером в несколько мегабайт, сгенерированные в результате экспериментов с контролируемым производством полупроводниковых пластин или моделирования TCAD, подготовленные для базового логического анализа.
Это побудило меня искать надежный вводный курс по языку R, и к кому лучше обратиться, чем к Хосе Портилья! Я записался на его курс « Data Science and Machine Learning Bootcamp with R ». Это была сделка «купи один — получи еще одну бесплатно», поскольку в первой половине курса были охвачены основы языка R, а затем были переключены на преподавание базовых концепций машинного обучения (все важные концепции, ожидаемые во вводном курсе, были рассмотрены с достаточной тщательностью). В отличие от курса edX Microsoft, в котором использовалась серверная практическая лабораторная среда, этот курс охватывал установку и настройку R Studio и необходимых пакетов, познакомил меня с kaggle и дал необходимый толчок, чтобы перестать быть пассивным учеником (также известным как MOOC video watcher) человеку, который не боится играть с данными.Он также последовал за великой книгой Гарета Джеймса, Даниэлы Виттен, Тревора Хасти и Роберта Тибширани « Введение в статистическое обучение в R » (ISLR), глава за главой.
Если вам разрешено прочитать только одну книгу за всю жизнь для изучения машинного обучения и ничего другого, выберите эту книгу и прочитайте все главы, без исключения. Кстати, в этой книге нет нейронных сетей или материалов по глубокому обучению, так что здесь…
Вооружившись материалами курса, книгой ISLR и попрактиковавшись на случайных наборах данных, загруженных из kaggle, или даже моих собственных данных об использовании электроэнергии из PG&E, я больше не боялся писать небольшие байты кодов, которые действительно могут моделировать что-то интересное или полезное.Я проанализировал некоторые данные о преступности на уровне округов США, выяснил, почему большой план эксперимента может привести к ложной корреляции, и даже об использовании электроэнергии в моей квартире за последние 3 месяца. Я также успешно использовал R для построения прогнозных моделей на основе некоторых реальных наборов данных из моей работы. Статистическая / функциональная природа языка и готовая оценка доверительных интервалов (p-значения или z-оценка) для различных моделей (регрессии или классификации) действительно помогают новому учащемуся легко закрепиться в области статистики. моделирование.
Как ИИ улучшает производительность сети? Никто не понимает полностью, и это ограничивает его использование
Так же, как операторы энергосистем осваивают аналитику данных для оптимизации эффективности оборудования, они обнаруживают, как сложные инструменты искусственного интеллекта могут сделать гораздо больше и как выбрать, что использовать.
Благодаря развертыванию усовершенствованной измерительной инфраструктуры (AMI) и оборудования, оснащенного интеллектуальными датчиками, системные операторы получают беспрецедентные объемы данных.Облачные вычисления и огромные вычислительные возможности позволяют аналитике данных окупать эти инвестиции для клиентов. Но для решения новых сложностей энергосистем может потребоваться машинное обучение (ML) и искусственный интеллект (AI).
AI — это форма информатики, которая сделает управление энергосистемой полностью автономным в реальном времени, сообщили Utility Dive исследователи и частные поставщики услуг энергосистемы. Машинное обучение — это часть ИИ, которая передает аналитику данных под контролем человека с помощью заранее установленных или усвоенных правил о системе, чтобы информировать ИИ о нормальных и ненормальных условиях работы.
«[D] ata управление подпадает под категории« сканирование, обход и запуск », и большинство утилит прямо сейчас сканируют свои данные. ИИ для управления данными будет« запущен »».
Кевин Уолш
Руководитель передачи и распределения, OSIsoft
«Знание, когда использовать аналитику данных, а когда — машинное обучение и искусственный интеллект, — вот основные вопросы, которые задают коммунальные предприятия», — сказал Utility Dive вице-президент GE Digital по данным и аналитике Мэтт Шнагг.Продолжение использования подхода, «который был достаточно хорошим в течение многих лет», имеет свои достоинства, но новые инструменты и возможности могут оправдать «обращение к специалистам по данным и облачным вычислениям», и есть «параметры», позволяющие выбирать между ними.
Огромный объем данных начинает превышать человеческие возможности, но системные операторы часто не имеют технологий для развертывания продемонстрированных решений AI и ML для управления потоком энергии, сообщили исследователи Utility Dive. Они признали, что математика решений еще не полностью изучена.Следующий большой вопрос может заключаться в том, будут ли системные операторы рисковать ML и AI ради результатов, которые люди еще не могут предоставить или понять.
Когда достаточно аналитики данных
Ценность использования данных энергосистемы становится все более очевидной. Это сэкономило время системных операторов и деньги клиентов. Кроме того, он обеспечивает прогнозируемое обслуживание инфраструктуры, которое может снизить растущую частоту и продолжительность перебоев в обслуживании и помочь избежать крупных непреднамеренных каскадных отключений.
«Коммунальные предприятия вложили миллиарды долларов в материальные активы, и они используют данные для управления этими активами», — сказал Utility Dive Кевин Уолш, главный специалист по передаче и распределению данных OSIsoft. «Но управление данными подпадает под категории« сканирование, обход и запуск », и большинство коммунальных служб сейчас сканируют свои данные. ИИ для управления данными будет« запущен »».
Поставщики услуг управления данными, такие как OSIsoft, помогают коммунальным предприятиям ассимилировать данные «и делать их доступными для всего предприятия, чтобы принимать интеллектуальные решения на основе того, что на самом деле происходит в полевых условиях», — сказал Уолш.«Для 75% того, что делают коммунальные предприятия, помимо, возможно, прогнозирования или управления возможностями, ИИ находится на начальной стадии и не имеет реальных вариантов использования».
«Специалисты по искусственному интеллекту и машинному обучению слишком часто ищут проблемы, которые нужно решить, вместо того, чтобы решать очень конкретные проблемы, с которыми сталкиваются коммунальные предприятия, и демонстрируют, как машинное обучение может быть правильным решением».
Джошуа Вонг
Генеральный директор, Opus One Solutions
Аномалия потока данных, обнаруженная аналитикой данных OSIsoft PI System, позволила муниципальному коммунальному предприятию Алекры, штат Техас, отложить замену трансформатора за 3 миллиона долларов на ремонт трансформатора за 100 000 долларов, отметил он.Duke Energy и Sempra Energy используют аналитику PI для профилактического обслуживания. По его словам, аналитика данных «делает большую часть того, что нужно коммунальным предприятиям», без затрат и сложностей, связанных с искусственным интеллектом и машинным обучением.
«Искусственный интеллект и машинное обучение — это ажиотаж среди инвесторов и широкой публики, но основная проблема коммунальных предприятий — это то, что любая аналитика привнесет в их операции», — согласился генеральный директор Opus One Solutions Джошуа Вонг.
Opus One использует передовые физические и математические формулы, лежащие в основе системы распределения, для создания «цифрового двойника» системы коммунального обслуживания, сказал Вонг Utility Dive.В основном с помощью аналитического программного обеспечения двойник используется для моделирования и информирования операций коммунальных систем, планирования и разработки рыночных и бизнес-моделей.
Чаще всего ML используется для алгоритмов на пять минут вперед и на день вперед, которые выполняют прогнозирование нагрузки и генерации, сказал он. Унаследованные программные технологии коммунальных предприятий не могут работать с «очень большими и взаимозависимыми наборами данных, необходимыми для энергопотока всей сети», но для прогнозирования требуется только обучение вперед »с одного момента в истории без множества зависимых явлений.«
Более совершенные алгоритмы могут быть созданы с помощью комбинации инструментов искусственного интеллекта и анализа данных, которые коррелируют реальные данные и обучение, сказал Вонг. «Наибольшее влияние машинное обучение окажет на создание корреляций, которые научат алгоритм понимать, как напряжение здесь влияет на напряжение там». Эти корреляции позволят «оптимизировать сетевые операции, такие как диспетчерское хранение аккумуляторов или управление зарядкой электромобилей», — сказал Вонг.
Пилотные проекты и исследования показывают, что автоматизация уже может оптимизировать некоторые из этих операций.
На пути к автоматизации
В рамках первого пилотного проекта того, что в конечном итоге может стать автономной сетью, Helia Technologies и колорадский кооператив Holy Cross Energy (HCE) тестируют возможности диспетчеризации батарей ML.
Четыре дома в системе HCE оснащены несколькими распределенными ресурсами, включая батареи. Как сообщил Utility Dive генеральный директор Helia Франсиско Мароч, контроллер Helia прогнозирует фактический потенциал заряда-разряда батарей, а не номинальные возможности производителей.Это позволяет домам поддерживать оптимальный поток мощности системы для HCE.
Подобное пилотное испытание возможности ML по оптимизации распределения батарей оказалось успешным для United Power в Колорадо, сообщил Utility Dive руководитель программы аналитических исследований Национальной ассоциации сельских кооперативов по производству электроэнергии Дэвид Пинни. «Алгоритм машинного обучения смог спрогнозировать оптимальную отправку кооперативом различных приложений хранения энергии на три дня вперед».
Duke Energy «начинает использовать возможности машинного обучения, особенно в областях анализа данных и прогнозной аналитики», — сообщил Utility Dive представитель Duke Джефф Брукс.Удаленные переключатели и устройства повторного включения Duke все еще находятся под контролем человека, которые позволяют реконфигурировать и перенаправлять в ответ на отключение, но некоторые из них выполняются с помощью «скриптовых алгоритмов и процессов».
«Прорыв в вычислительных возможностях и возможностях обработки данных позволяет алгоритмам обучаться посредством взаимодействия с сетевым окружением».
Цюхуа Хуан
Инженер-исследователь, Тихоокеанская Северо-Западная национальная лаборатория
В течение следующих трех-пяти лет специалисты по обработке данных Duke планируют «разработать и развернуть» искусственный интеллект и машинное обучение, которые позволят более полно автоматизировать аналитику, управление отключениями и потоки энергии, сказал Брукс.
Операторы систем передачи медленнее продвигаются к автоматизации, но исследования национальных лабораторий, финансируемых Министерством энергетики, теперь сосредоточены на алгоритмах машинного обучения, которые обучают нейронные сети для обработки системных данных, сообщили исследователи Utility Dive.
Нейронные сети — это наборы алгоритмов, предназначенные для распознавания и упорядочивания шаблонов в анализируемых данных, и ML может обучить их, чтобы помочь операторам систем передачи, столкнувшимся с внезапными большими колебаниями напряжения, сказал инженер-исследователь Тихоокеанской северо-западной национальной лаборатории (PNNL) Цюхуа Хуанг Utility Dive.На ранних стадиях моделирования алгоритмы реагировали за миллисекунды, чтобы предотвратить нестабильность напряжения и каскадные отключения.
«Прорыв в вычислительных возможностях и возможностях обработки данных позволяет алгоритмам обучаться посредством взаимодействия с сетевым окружением», — сказал он. «ML наблюдает за историческими данными и данными в реальном времени и учится добиваться хороших результатов способами, которые кажутся за пределами человеческой интуиции».
ML используется для обучения нейронной сети другого типа реагированию на отказ линии передачи, вызванный скачком спроса, погодным явлением или кибератакой, сообщил Utility Dive исследователь Аргоннской национальной лаборатории Кибак Ким.При моделировании он отреагировал в 12 раз быстрее, чем сегодня работают люди, и скорректировал напряжения «автоматически на основе обученной модели».
Цель состоит в том, чтобы вывести системных операторов «из цикла» и предоставить «принятие решений от начала до конца» ИИ, сказал Utility Dive научный сотрудник Национальной лаборатории возобновляемых источников энергии (NREL) Инчэнь Чжан. Это потребует времени и испытаний, потому что, в отличие от фильма Netflix, от которого легко отказаться, «неправильное решение системы электропитания может вызвать отключение электроэнергии во всей системе, а это неприемлемо.«
Необходимость испытаний для проверки надежности — основная причина, по которой машинное обучение и искусственный интеллект редко внедряются, — сказал Ким. Другая причина заключается в том, что, как отметил Вонг, коммунальные предприятия и системные операторы еще не имеют аппаратного и программного обеспечения для их использования, хотя эта проблема решается с помощью нового экономичного доступа к облачным вычислениям, сказал он.
Что еще более важно, коммунальные предприятия сопротивляются, потому что исследователи «не полностью понимают математику, лежащую в основе нейронных сетей, и почему они так хорошо работают», — сказал Ким.«Понимание придет, но я не знаю когда».
До этого момента алгоритм мог обнаружить что-то неизвестное и ответить некорректно, сказал он.
Очевидно, что ML работает так, как было задумано, «потому что вводимые в алгоритм данные изучаются и работают, как задумано», — сказал Хуанг из PNNL. «Но, возможно, мы не знаем точно, как нейронная сеть выбирает из входных данных и принимает окончательное решение, потому что для принятия этого решения требуется очень сложная обработка.«
Исследование теперь направлено на этот вопрос, добавил он. Вероятное объяснение состоит в том, что нейронные сети используют «совершенно другой способ интерпретации этих уравнений с некоторой логикой более высокого уровня».
Пока идет ответ на вопрос, операторы энергосистем должны решить, как действовать дальше.
Как выбрать, что использовать
Решение о том, нужны ли машинное обучение и искусственный интеллект для решения задач, давно решаемых с помощью аналитики данных, зависит от двух факторов, сказал Шнугг из GE Digital.Один из них — это системный оператор, а другой — проблема, которую оператор хочет решить.
Алгоритмы
ML «имеют тенденцию иметь наибольшее влияние при моделировании событий, которые произошли много раз, а не событий Черного лебедя без шаблона данных».
Мэтт Шнуг
Вице-президент по данным и аналитике, GE Digital
Рекомендации по принятию решения «не каноничны», но «есть параметры, когда лучше всего использовать ИИ и машинное обучение», — сказал он.«Во-первых, вам необходимо очистить и подготовить огромный объем данных для обучения и построения алгоритма. Это всего лишь ставки на стол. Доступ к облаку обычно является наиболее экономически эффективным способом получить это».
Во-вторых, алгоритмы машинного обучения «имеют тенденцию иметь наибольшее влияние при моделировании событий, которые произошли много раз, а не событий Черного лебедя без шаблона данных», — сказал он. Новое приложение GE Storm Readiness основано на истории повторяющихся отключений из-за штормов. «Штормовая готовность — вот результат модели.Чем больше отключений предстоит изучить, тем более точной может быть модель ».
В-третьих, моделирование должно пройти проверку «да, нет, черт возьми», решив реальную проблему, — сказал Шнуг. «Машинное обучение не требуется для предсказания завтрашнего восхода солнца, но если решение относительно чего-то очень насыщенного данными, которое происходит постоянно, может привести к заметно более высокой производительности, стоит использовать ИИ и машинное обучение для построения прогнозной модели».
Есть два определения «лучшей производительности», — добавил он. «Это может быть более точный прогноз, или он может сэкономить время при достижении той же точности.Прогностическая модель на основе машинного обучения, которая автоматизирует процесс или серию решений, на которые у человека уйдет гораздо больше времени, добавляет огромную ценность ».
В новом продукте GE Storm Readiness алгоритмы машинного обучения создают и обучают нейронную сеть для изучения истории данных о погоде и производительности системы. Затем он может предсказать за 72 часа, где шторм поразит систему и какие ресурсы потребуются для устранения его последствий.
Напротив, его новый продукт Network Connectivity полностью полагается на традиционную аналитику данных для управления активами системы передачи и распределения.Цель состоит в том, чтобы оптимизировать бизнес-деятельность коммунального предприятия, от обслуживания оборудования до проката грузовиков.
Приложение GE Effective Inertia — это гибридный инструмент, сочетающий в себе анализ данных системы передачи в реальном времени и алгоритм прогнозирования нагрузки и генерации на основе машинного обучения. Он прогнозирует колебания инерции системы за 24 часа вперед из-за мгновенных дисбалансов спроса и предложения, вызванных повышением уровней переменных возобновляемых источников энергии, и информирует о рентабельных закупках резервов для стабилизации колебаний.
«Облако демократизировало доступ к данным, и теперь качество данных и качество задаваемых вопросов являются наиболее важными», — сказал Шнугг. «Машинное обучение и искусственный интеллект — это только часть ценности. Самая большая ценность — помочь коммунальному предприятию решить свою проблему».
Введение в Vertex AI | Google Cloud
Vertex AI представляет AutoML и платформу AI вместе в единый API, клиентскую библиотеку и пользовательский интерфейс. AutoML позволяет обучать модели изображениям, таблицам, тексту и видео. наборы данных без написания кода, при обучении на платформе AI позволяет запускать собственный обучающий код.С Vertex AI оба AutoML обучение и индивидуальное обучение доступны варианты. Какой бы вариант вы ни выбрать для обучения, вы можете сохранять модели, развертывать модели и запрашивать прогнозы с Vertex AI.
Место Vertex AI в рабочем процессе машинного обучения
Вы можете использовать Vertex AI для управления следующими этапами в Рабочий процесс машинного обучения:
Создайте набор данных и загрузите данные.
Обучите модель машинного обучения на своих данных:
- Обучить модель
- Оценить точность модели
- Настройка гиперпараметров (только индивидуальное обучение)
Загрузите и сохраните вашу модель в Vertex AI.
Разверните обученную модель на конечной точке для обслуживания прогнозов.
Отправляйте запросы прогнозов на конечную точку.
Укажите разделение прогнозируемого трафика в конечной точке.
Управляйте своими моделями и конечными точками.
Компоненты Vertex AI
В этом разделе описаны части, из которых состоят Vertex AI и основное предназначение каждого предмета.
Обучение
Вы можете обучать модели на Vertex AI с помощью AutoML или использовать индивидуальное обучение, если вам нужен более широкий спектр доступных вариантов настройки в обучении платформе AI.
При индивидуальном обучении вы можете выбрать множество различных типов машин для учебные задания, включить распределенное обучение, использовать настройку гиперпараметров и ускоряться с помощью графических процессоров.
Развертывание моделей для прогнозирования
Вы можете развернуть модели на Vertex AI и получить конечную точку для служить прогнозы на Vertex AI.
Вы можете развертывать модели на Vertex AI независимо от того, была ли модель обучался Vertex AI.
Маркировка данных
Задания по маркировке данных позволить вам запросить человеческую маркировку для набора данных, который вы планируете использовать для обучения пользовательская модель машинного обучения.Вы можете отправить запрос на присвоение метки своему видео, изображение или текстовые данные.
Чтобы отправить запрос на маркировку, вы предоставляете репрезентативный образец маркированных данных, укажите все возможные метки для вашего набора данных и укажите некоторые инструкции по нанесению этих этикеток. Люди-этикетщики следуют за вашими инструкции, и когда запрос на маркировку будет завершен, вы получите свой аннотированный набор данных, который можно использовать для обучения модели машинного обучения.
Магазин функций
Feature Store — это полностью управляемый репозиторий, в котором вы можете принимать, обслуживать и делиться ценностями функций машинного обучения в вашей организации.Магазин функций управляет всей базовой инфраструктурой за вас. Для Например, он предоставляет вам хранилище и вычислительные ресурсы и может легко масштабироваться по мере необходимости.
Vertex AI Workbench
Vertex AI Workbench — это среда разработки на основе блокнотов Jupyter для всего рабочего процесса в области науки о данных. Верстак Vertex AI позволяет получать доступ к данным, обрабатывать данные в кластере Dataproc, тренируйте модель, делитесь своими результатами и многое другое, не покидая интерфейс JupyterLab.
В этом разделе описаны инструменты, которые вы используете для взаимодействия с Vertex AI.
Облачная консоль Google
Вы можете развертывать модели в облаке и управлять своими наборами данных, моделями, конечными точками, и рабочие места на Облачная консоль. Эта опция дает вам пользовательский интерфейс для работы с вашим машинным обучением. Ресурсы. В рамках Google Cloud ваши ресурсы Vertex AI подключены к таким полезным инструментам, как Cloud Logging и Cloud Monitoring. Лучшее место для начала использования Cloud Console — это Dashboard . страница раздела Vertex AI:
Перейти на страницу панели управления
Облачные клиентские библиотеки
Vertex AI предоставляет клиентские библиотеки для некоторых языков, чтобы помочь вам совершать вызовы API Vertex AI.Клиентские библиотеки предоставляют оптимизированный опыт разработчика за счет использования естественных условности и стили. Для получения дополнительной информации о поддерживаемых языках и как их установить, см. Установка клиента библиотеки.
В качестве альтернативы вы можете использовать Клиентские библиотеки Google API для доступа к API Vertex AI с использованием других языков, таких как Dart. Когда используя клиентские библиотеки Google API, вы создаете представления ресурсы и объекты, используемые API.Это проще и требует меньше кода чем напрямую работать с HTTP-запросами.
REST API
Vertex AI REST API предоставляет Сервисы RESTful для управления заданиями, моделями и конечными точками, а также для создания прогнозы с размещенными моделями в Google Cloud.
Образы виртуальных машин с глубоким обучением
Образы виртуальных машин с глубоким обучением — это набор образы виртуальных машин, оптимизированные для науки о данных и машин учебные задания. Все изображения поставляются с ключевыми фреймворками и инструментами машинного обучения. предустановлен.Вы можете использовать их прямо из коробки на инстансах с Графические процессоры для ускорения задач обработки данных.
Образы виртуальных машин Deep Learning доступны для поддержки множества комбинаций. каркаса и процессора. В настоящее время есть изображения, поддерживающие TensorFlow Enterprise, TensorFlow, PyTorch и общие высокопроизводительные вычисления, с версиями как для рабочих процессов с CPU, так и с GPU.
Чтобы увидеть список доступных фреймворков, см. Выбор изображение.
Дополнительные сведения см. В разделах Использование образов виртуальных машин с глубоким обучением и Контейнеры глубокого обучения с Vertex AI.
Контейнеры глубокого обучения
Контейнеры глубокого обучения — это набор контейнеров Docker. с предустановленными ключевыми фреймворками для анализа данных, библиотеками и инструментами. Эти контейнеры обеспечивают оптимизированную по производительности, согласованную среды, которые могут помочь вам быстро создавать прототипы и внедрять рабочие процессы.
Дополнительные сведения см. В разделах Использование образов виртуальных машин с глубоким обучением и Контейнеры глубокого обучения с Vertex AI.
Что дальше
Мониторинг бытовой техники по показаниям мощности с помощью ML
Потребление данных
После того, как система публикует данные в Cloud Pub / Sub, она доставляет запрос сообщения в «конечную точку push», обычно службу шлюза, которая потребляет данные.В нашей демонстрационной системе Cloud Pub / Sub отправляет данные в службу шлюза, размещенную в App Engine, которая затем перенаправляет данные в модель машинного обучения, размещенную в Cloud ML Engine, для вывода, и в то же время сохраняет необработанные данные вместе с полученными. результаты прогнозирования в BigQuery для последующего (пакетного) анализа.
Несмотря на то, что существует множество бизнес-зависимых вариантов использования, которые вы можете развернуть на основе нашего образца кода, мы проиллюстрировали визуализацию необработанных данных и результатов прогнозов в нашей демонстрационной системе.В репозитории кода мы предоставили две записные книжки:
-
EnergyDisaggregationDemo_Client.ipynb: этот ноутбук имитирует несколько интеллектуальных счетчиков, считывая данные о потребляемой мощности из реального набора данных и отправляя показания на сервер. Весь код, связанный с Cloud IoT Core, находится в этой записной книжке. -
EnergyDisaggregationDemo_View.ipynb: этот ноутбук позволяет просматривать необработанные данные о потреблении энергии с указанного интеллектуального счетчика и результаты прогнозов нашей модели практически в реальном времени.
Если вы будете следовать инструкциям по развертыванию в файле README и прилагаемых записных книжках, вы сможете воспроизвести результаты, показанные на рисунке 2. Между тем, если вы предпочитаете построить конвейер дезагрегации в другом Таким образом, вы также можете использовать Cloud Dataflow и Pub / Sub I / O для создания приложения с аналогичной функциональностью.
Обработка данных и машинное обучение
Введение в набор данных и исследование
Мы обучили нашу модель прогнозированию состояния включения / выключения каждого устройства по показаниям полной мощности, используя данные по электроэнергии на уровне домашних устройств Великобритании (UK-DALE, общедоступно здесь 1 ), чтобы эта сквозная демонстрационная система была воспроизводимой.UK-DALE каждые 6 секунд регистрирует энергопотребление всего дома и использование каждого отдельного прибора в 5 домах. Мы демонстрируем наше решение, используя данные из дома № 2, для которого набор данных включает в себя в общей сложности потребляемую мощность 18 устройств. Учитывая степень детализации набора данных (частота дискретизации Гц), трудно оценить устройства с относительно небольшим энергопотреблением. В результате из этой демонстрации исключены такие устройства, как ноутбуки и компьютерные мониторы. Основываясь на исследовании данных, показанном ниже, мы выбрали восемь приборов из первоначальных 18 предметов в качестве целевых приборов: беговая дорожка, стиральная машина, посудомоечная машина, микроволновая печь, тостер, электрический чайник, рисоварка и «плита», a.к.а., плита электрическая.
На рисунке ниже показаны гистограммы энергопотребления выбранных устройств. Поскольку все приборы большую часть времени выключены, большинство показаний близки к нулю. На рис. 4 показано сравнение совокупного энергопотребления выбранных устройств («app_sum») и энергопотребления всего дома («брутто»). Стоит отметить, что входными данными нашей демонстрационной системы является общее потребление (синяя кривая), потому что это наиболее доступные данные об энергопотреблении, которые можно измерить даже вне дома.
Машинное обучение в медицине: практическое введение | BMC Medical Research Methodology
Благодаря увеличению вычислительной мощности, хранилища, памяти и генерации огромных объемов данных компьютеры используются для выполнения широкого круга сложных задач с впечатляющей точностью. Машинное обучение (ML) — это название, данное как учебной дисциплине, так и совокупности методов, которые позволяют компьютерам выполнять сложные задачи. Как академическая дисциплина ML включает в себя элементы математики, статистики и информатики.Машинное обучение — это двигатель, который способствует развитию искусственного интеллекта. Он впечатляюще используется как в академических кругах, так и в промышленности для стимулирования разработки «интеллектуальных продуктов» с возможностью делать точные прогнозы с использованием различных источников данных [1]. На сегодняшний день основными бенефициарами резкого роста доступности больших данных, машинного обучения и науки о данных в 21 -м и -м веке стали отрасли, которые смогли собрать эти данные и нанять необходимый персонал для преобразования своих продуктов.Методы обучения, разработанные в этих отраслях и для них, предлагают огромный потенциал для улучшения медицинских исследований и оказания клинической помощи, особенно с учетом того, что провайдеры все чаще используют электронные медицинские карты.
Две области, которые могут получить выгоду от применения методов машинного обучения в области медицины, — это диагностика и прогнозирование результатов. Это включает возможность выявления высокого риска возникновения неотложных состояний, таких как рецидив или переход в другое болезненное состояние. Алгоритмы ML недавно были успешно применены для классификации рака кожи с использованием изображений, сравнимых с точностью, полученной обученным дерматологом [2], и для прогнозирования прогрессирования от преддиабета к диабету 2 типа с использованием регулярно собираемых электронных данных о состоянии здоровья [3].
Машинное обучение будет все чаще использоваться в сочетании с обработкой естественного языка (NLP) для понимания неструктурированных текстовых данных. Комбинируя ML с техниками НЛП, исследователи смогли извлечь новую информацию из комментариев из отчетов о клинических происшествиях [4], активности в социальных сетях [5, 6], отзывов врачей [7] и отчетов пациентов после успешного лечения рака [8] ]. Автоматически генерируемая информация из неструктурированных данных может быть исключительно полезной не только для понимания качества, безопасности и производительности, но и для ранней диагностики.Недавно автоматизированный анализ свободы слова, собранный во время личных интервью, позволил с идеальной точностью предсказать переход к психозу в группе молодых людей из группы высокого риска [9].
Машинное обучение также будет играть фундаментальную роль в развитии обучающихся систем здравоохранения. Обучающиеся системы здравоохранения описывают среду, которая объединяет науку, информатику, стимулы и культуру для постоянного совершенствования и инноваций. В практическом смысле эти системы; которое может происходить в любом масштабе, от небольших групповых практик до крупных национальных провайдеров, будет сочетать различные источники данных со сложными алгоритмами машинного обучения.Результатом станет непрерывный источник аналитических данных для оптимизации биомедицинских исследований, улучшения общественного здоровья и качества медицинской помощи [10].
Машинное обучение
Методы машинного обучения основаны на алгоритмах — наборах математических процедур, которые описывают отношения между переменными. В этой статье будет объяснен процесс разработки (известного как обучение ) и проверки алгоритма прогнозирования злокачественности образца ткани груди на основе его характеристик.Хотя алгоритмы работают по-разному в зависимости от их типа, в способах их разработки есть заметные общие черты. Хотя сложность алгоритмов машинного обучения может показаться тайной, они часто имеют более чем тонкое сходство с традиционным статистическим анализом.
Учитывая общие черты статистических методов и методов машинного обучения, граница между ними может показаться нечеткой или нечеткой. Один из способов обозначить эти совокупности подходов — рассмотреть их основные цели.Целью статистических методов является вывод ; сделать выводы о популяциях или извлечь научную информацию из данных, собранных из репрезентативной выборки этой популяции. Хотя многие статистические методы, такие как линейная и логистическая регрессия, позволяют делать прогнозы относительно новых данных, мотивация их использования в качестве статистической методологии состоит в том, чтобы делать выводы о взаимосвязях между переменными. Например, если бы мы создали модель, описывающую взаимосвязь между клиническими переменными и смертностью после операции по трансплантации органов, нам нужно было бы иметь представление о факторах, которые отличают низкий риск смертности от высокого, если бы мы должны были разработать меры для улучшения исходы и снизить смертность в будущем.Таким образом, при статистическом выводе цель состоит в том, чтобы понять взаимосвязи между переменными.
И наоборот, в области машинного обучения первоочередной задачей является точный прогноз ; «что», а не «как». Например, при распознавании изображений взаимосвязь между отдельными функциями (пикселями) и результатом не имеет большого значения, если прогноз точен. Это критический аспект методов машинного обучения, поскольку взаимосвязь между многими входными данными, такими как пиксели в изображении или видео и геолокация, сложна и обычно нелинейна.Исключительно сложно связно описать отношения между предикторами и результатами как в случае, когда отношения нелинейны, так и при большом количестве предикторов, каждый из которых вносит небольшой индивидуальный вклад в модель.
К счастью для области медицины, многие представляющие интерес взаимосвязи достаточно просты, например, между индексом массы тела и риском диабета или употреблением табака и раком легких. Из-за этого их взаимодействие часто можно достаточно хорошо объяснить с помощью относительно простых моделей.Во многих популярных приложениях машинного обучения, таких как оптимизация навигации, перевод документов и идентификация объектов в видео, понимание взаимосвязи между функциями и результатами имеет меньшее значение. Это позволяет использовать сложные нелинейные алгоритмы. Учитывая это ключевое различие, исследователям может быть полезно учесть, что алгоритмы существуют в виде континуума между теми алгоритмами, которые легко интерпретируются (то есть проверяемыми алгоритмами), и теми, которые не являются (то есть черными ящиками), представленными визуально на рис.1.
Рис. 1Компромисс между сложностью и интерпретируемостью в инструментах машинного обучения
Остаются интересные вопросы относительно того, когда традиционный статистический метод становится методом машинного обучения. В этой работе мы расскажем о том, что вычислительные усовершенствования традиционных статистических методов, таких как эластичная чистая регрессия, позволяют этим алгоритмам хорошо работать с большими данными. Однако более полное обсуждение сходств и различий между ML и традиционной статистикой выходит за рамки данной статьи.Заинтересованным читателям предлагаются материалы, развивающие обсуждаемые здесь идеи [11]. Следует также признать, что хотя концепция «черного ящика» в целом применима к моделям, использующим нелинейные преобразования, таким как нейронные сети, проводится работа по облегчению идентификации признаков в сложных алгоритмах [12].
Большинство методов машинного обучения можно разделить на два типа методов обучения: контролируемые и неконтролируемые.Оба они представлены в следующих разделах.
Обучение с учителем
Машинное обучение с учителем относится к методам, в которых модель обучается ряду входных данных (или функций), которые связаны с известным результатом. В медицине это может представлять собой обучение модели, которая связывает характеристики человека (например, рост, вес, статус курения) с определенным результатом (например, с началом диабета в течение пяти лет). После успешного обучения алгоритм сможет делать прогнозы результатов при применении к новым данным.Прогнозы, которые делаются моделями, обученными с использованием контролируемого обучения, могут быть дискретными (например, положительными или отрицательными, доброкачественными или злокачественными) или непрерывными (например, с оценкой от 0 до 100).
Модель, которая производит дискретные категории (иногда называемые классами), называется алгоритмом классификации . Примеры алгоритмов классификации включают те, которые позволяют предсказать, является ли опухоль доброкачественной или злокачественной, или установить, выражают ли комментарии, написанные пациентом, положительное или отрицательное мнение [2, 6, 13].На практике алгоритмы классификации возвращают вероятность класса (от 0 для невозможного и 1 для определенного). Обычно мы преобразуем любую вероятность больше 50 в класс 1, но этот порог может быть изменен для повышения производительности алгоритма по мере необходимости. В этой статье приводится пример алгоритма классификации, в котором прогнозируется диагноз.
Модель, которая возвращает прогноз непрерывного значения, известна как алгоритм регрессии . Использование термина регрессия в ML отличается от его использования в статистике, где регрессия часто используется для обозначения обоих двоичных результатов (т.е., логистическая регрессия) и непрерывные результаты (т. е. линейная регрессия). В ML алгоритм, который называется алгоритмом регрессии, может использоваться для прогнозирования продолжительности жизни человека или переносимой дозы химиотерапии.
Алгоритмы контролируемого машинного обучения обычно разрабатываются с использованием набора данных, который содержит ряд переменных и соответствующий результат. Для некоторых задач, таких как распознавание изображений или языковая обработка, переменные (которые могут быть пикселями или словами) должны обрабатываться селектором функций.Селектор признаков выбирает идентифицируемые характеристики из набора данных, которые затем могут быть представлены в числовой матрице и понятны алгоритму. В приведенных выше примерах признаком может быть цвет пикселя изображения или количество раз, когда слово появляется в заданном тексте. Используя те же примеры, исходы могут заключаться в том, показывает ли изображение злокачественную или доброкачественную опухоль или расшифрованные ответы на интервью указывают на предрасположенность к состоянию психического здоровья.
После того, как набор данных организован по функциям и результатам, к нему можно применить алгоритм машинного обучения.Алгоритм итеративно улучшается, чтобы уменьшить ошибку предсказания с использованием метода оптимизации.
Обратите внимание, что при обучении алгоритмов машинного обучения можно чрезмерно подогнать алгоритм к нюансам определенного набора данных, что приведет к модели прогнозирования, которая плохо обобщается на новые данные. Риск чрезмерной подгонки можно снизить, используя различные методы. Возможно, наиболее простой подход, который будет использован в этой работе, — это разделить наш набор данных на два сегмента; сегмент обучения и сегмент тестирования, чтобы убедиться, что обученная модель может быть обобщена для прогнозов за пределами обучающей выборки.Каждый сегмент содержит случайно выбранную долю функций и связанных с ними результатов. Это позволяет алгоритму связывать определенные функции или характеристики с конкретным результатом и известно как обучающий алгоритм . После завершения обучения алгоритм применяется к функциям в наборе данных тестирования без связанных с ними результатов. Прогнозы, сделанные алгоритмом, затем сравниваются с известными результатами набора данных тестирования, чтобы установить производительность модели.Это необходимый шаг для увеличения вероятности того, что алгоритм хорошо обобщит новые данные. Графически этот процесс проиллюстрирован на рис.2.
Рис. 2Обзор обучения с учителем. a Обучение b Проверка c Применение алгоритма к новым данным
Машинное обучение без учителя
В отличие от обучения с учителем, обучение без учителя не предполагает заранее определенного результата. При обучении без учителя шаблоны ищутся алгоритмами без какого-либо участия пользователя.Таким образом, неконтролируемые методы являются исследовательскими и используются для поиска неопределенных шаблонов или кластеров, которые встречаются в наборах данных. Эти методы часто называют методами уменьшения размерности и включают такие процессы, как анализ главных компонентов, латентный анализ Дирихле и t-распределенное стохастическое соседнее вложение (t-SNE) [14–16]. Техники неконтролируемого обучения подробно не обсуждаются в этой работе, в которой основное внимание уделяется управляемому машинному обучению. Тем не менее, неконтролируемые методы иногда используются вместе с методами, используемыми в этой статье, чтобы уменьшить количество функций в анализе, и поэтому их стоит упомянуть.Сжимая информацию в наборе данных до меньшего количества функций или измерений, можно избежать проблем, включая множественную коллинеарность или высокие вычислительные затраты. Наглядная иллюстрация метода неконтролируемого уменьшения размерности приведена на рис. 3. На этом рисунке необработанные данные (представленные различными формами на левой панели) представлены алгоритму, который затем группирует данные в кластеры схожих точек данных ( представлен на правой панели). Обратите внимание, что данные, которые не имеют достаточной общности с кластеризованными данными, обычно исключаются, тем самым уменьшая количество функций в наборе данных.
Рис. 3Визуальная иллюстрация метода неконтролируемого уменьшения размеров
Подобно алгоритмам контролируемого обучения, описанным ранее, они также имеют много общего со статистическими методами, которые будут знакомы исследователям-медикам. В методах обучения без учителя используются аналогичные алгоритмы, используемые для кластеризации и уменьшения размерности в традиционной статистике. Те, кто знаком с анализом главных компонентов и факторным анализом, уже знакомы со многими методами, используемыми в обучении без учителя.
Чего будет достигнута эта статья
В этой статье представлен прагматический пример использования контролируемых методов машинного обучения для получения классификаций из набора данных, содержащего несколько входных данных. Первый алгоритм, который мы вводим, регуляризованная логистическая регрессия, очень тесно связан с многомерной логистической регрессией. Его отличает, прежде всего, использование функции регуляризации, которая уменьшает количество функций в модели и уменьшает величину их коэффициентов.Таким образом, регуляризация подходит для наборов данных, которые содержат много переменных и отсутствующих данных (известных как наборов данных с высокой разреженностью ), таких как матрицы термин-документ, которые используются для представления текста в исследованиях интеллектуального анализа текста.
Второй алгоритм, машина опорных векторов (SVM), завоевал популярность среди сообщества машинного обучения благодаря своей высокой производительности, позволяющей получать точные прогнозы в ситуациях, когда взаимосвязь между функциями и результатом является нелинейной. Он использует математическое преобразование, известное как трюк ядра , который мы опишем более подробно ниже.
Наконец, мы представляем искусственную нейронную сеть (ИНС), в которой сложная архитектура и сильно изменяемые параметры привели к ее широкому использованию во многих сложных приложениях, включая распознавание изображений и видео. Добавление специализированных нейронных сетей, таких как рекуррентные или сверточные сети, к ИНС привело к впечатляющей производительности при решении ряда задач. Поскольку ИНС являются сильно параметризованными моделями, они подвержены чрезмерной подгонке. Их производительность можно улучшить с помощью метода регуляризации, такого как DropConnect.
Конечная цель этой рукописи — дать клиницистам и исследователям-медикам базовое понимание того, что такое машинное обучение, как его можно использовать, а также практические навыки для разработки, оценки и сравнения собственных алгоритмов для решения задач прогнозирования. проблемы в медицине.
Как работать с этим документом
Мы предоставляем концептуальное введение вместе с практическими инструкциями с использованием кода, написанного для среды статистического программирования R, который можно легко изменить и применить к другим задачам классификации или регрессии.Этот код будет служить основой, на которой исследователи могут разрабатывать свои собственные исследования машинного обучения. Представленные здесь модели могут быть адаптированы к различным типам данных и, с небольшими изменениями, подходят для анализа текста и изображений.
Эта статья разделена на разделы, в которых описываются типичные этапы анализа машинного обучения: подготовка данных, алгоритмы обучения, проверка алгоритмов, оценка производительности алгоритмов и применение новых данных к обученным моделям.
В документе представлены примеры кода R, используемого для выполнения анализа.Полный код приведен в дополнительном файле 1. Данные, которые использовались для этих анализов, доступны в дополнительном файле 2.